一种基于联合检测和重识别的无锚实时多目标跟踪方法
本发明涉及到计算机视觉多目标跟踪任务,具体地涉及一种基于关联检测和重识别的单阶段多目标跟踪方法。
背景技术:
1、多目标跟踪(mot)一直是计算机视觉的一个长期目标,目标是估计视频中多个目标的轨迹,该任务的成功解决将有利于许多应用,如动作识别、运动视频分析、老年护理和人机交互。近年来大部分方法采用的是两阶段方法:首先通过目标检测算法定位目标,再通过重识别模型进行匹配将其链接到一个现有的轨迹或者生成新的轨迹。尽管随着目标检测算法和重识别算法的发展,两阶段方法在多目标跟踪上有明显的提升,但是两阶段方法不共享目标检测算法与重识别算法的特征图,导致推理速度慢,训练模型较大等缺点。
技术实现思路
1、本发明的目的提供一种基于关联检测和重识别的无锚多目标跟踪方法,以客服上述背景技术中所提出的技术问题。
2、为了解决上述的技术问题,本发明所采取的技术方案为:
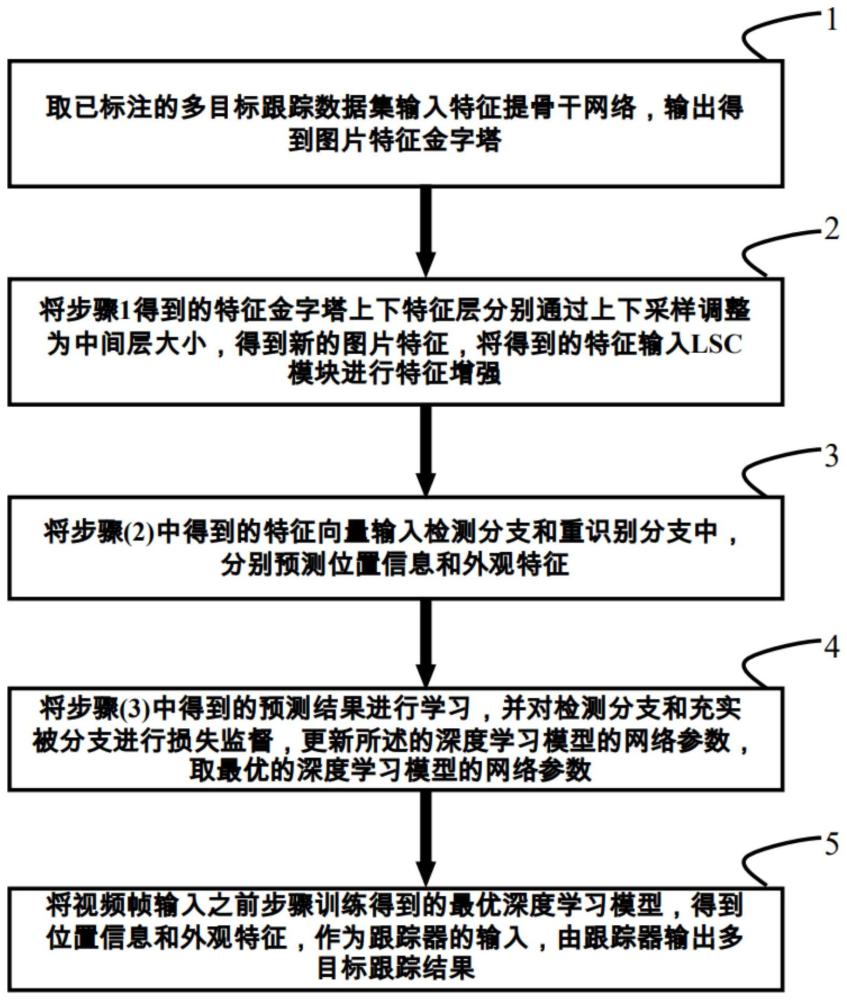
3、一种基于联合检测和重识别的无锚实时多目标跟踪方法,其特征在于,通过构建深度学习模型进行检测和跟踪,所述的深度学习模型包括,特征提取骨干网络、lsc注意力模块、检测分支、重识别分支,具体实施步骤包括:
4、s1;取已标注的图片输入特征提取骨干网络,得到由特征提取骨干网络输出的图片特征金字塔,所述特征提取骨干网络包括深度残差网络和变体dla参数聚合方法;
5、s2:将所述图片特征金字塔上下特征层分别进行上、下采样,将上下特征层调整为中间层特征的大小,形成特征向量f∈rl×s×c;将所述的特征向量f,输入lsc注意力模块,得到特征增强后的特征向量f′;
6、s3:将所述的特征向量f′输入所述的检测分支和重识别分支,分别得到位置信息和外观特征;
7、s4:根据得到预测结果进行学习,并对检测分支和重识别分支进行损失监督,更新所述深度学习模型的网络参数;
8、s5:取训练后最优的深度学习模型对图片的检测结果放入跟踪器中进行跟踪。
9、其中,步骤s1所述的特征提取骨干网络的深度残差网络为resnet-34;在resnet-34网络中采用一种变体参数聚合方法dla,为不同预测级别选取对骨架网络不同层,其中的上采样模块中的所有卷积层都由可变形的卷积层代替,以便它们可以根据对象的尺寸和姿势动态调整感受野;输入图像通过骨干网络进行前项传播,以获得在1/32,1/16/,1/8向下采样率的特征金字塔。
10、其中,步骤s2所述的lsc注意力模块包含三种注意力:
11、首先,尺度感知的注意力用于动态融合不同的特征,如公式(1)所示:
12、
13、其中f(·)是一个线性函数,近似与1×1卷积层,是一个hard-sigmoid函数;
14、其次,基于融合特征的空间感知注意力用于关注空间位置和特征级别之间一致共存的区域,考虑到特征的高维度,分解为两步骤:首先通过对可变形卷积进行压缩,使注意力学习变得稀疏,然后在相同空间位置上对不同层次的特征进行聚合,如公式(2)所示:
15、
16、其中,k为稀疏采样位置的个数,pk+δpk为通过自学习空间偏移量δpk来聚焦于判别区域的移位位置,δmk为自学习的位置pk的重要性标量;两者都是从的中位水平输入特征中学习而来;
17、最后,任务意识的注意力,用于实现联合学习和归纳对象的不同表征,如公式(3)所示:
18、
19、其中是第c通道的特征片,[α1,α2,β1,β2]t=θ(·)是一个学习控制激活函数阈值的超函数,θ(·)首先在l×s维上进行全局平均池化以降低维数,然后使用两个全连接层和一个归一化层,最后应用唯一sigmoid函数将输出归一化到[-1,1]。
20、其中,步骤s3所述的检测分支,包括三个并行的预测器用于跟踪任务中的目标检测部分,每个预测器由256通道的卷积核大小为3×3的卷积与卷积核大小为1×1的卷积组成,所述的预测器包括:热图预测器、框尺寸预测器和中心偏移预测器;
21、所述的热图预测器中的损失函数包括:
22、热图预测器负责预测物体的中心位置,热图的输出特征图大小为h×w×1,若热图随真实物体中心崩塌,则输出的特征图中该位置的响应为1;热图预测器随着热图中位置与目标中心距离的增加,响应呈指数级衰减;对于每个gt框计算目标中心为和然后点在特征图上的位置由其除以步长得到,即在热图中,位置(x,y)的热图响应计算如公式(4)所示:
23、
24、其中,n表示图像中物体的数量,σc为标准差;
25、损失函数定义为具有焦点损失的像素级逻辑回归,如公式(5)所示:
26、
27、其中,是预测热图,α,β为预设的损失参数;
28、所述的框尺寸预测器和中心偏移预测器的损失函数包括:
29、中心偏移预测器用于更精确地定位目标在图像中的位置;由于特征图的步长为4,因此会引入最大为4像素的不可忽略的误差;框偏移预测器估算每个像素点相对于目标中心的连续偏移,以减轻对下采样的影响;框尺寸预测器负责估计每个位置上的目标边界框的尺寸;
30、将框偏移预测器和大小预测器的输出表示为和对于每个gt框可以计算其大小为同样地,gt的偏移可以计算为分别将对应位置的偏移量和尺寸表示为和然后为两个预测器加入l1损失,如公式(6)所示:
31、
32、其中,λs为权重系数,设置为0.1。
33、其中,步骤s3所述的重识别分支中的重识别特征提取是在特征f′之上应用了具有128个内核的卷积层,以提取每个位置的身份嵌入特征,其中的重识别损失函数包括:
34、通过分类任务学习重识别特征,训练集中具有相同身份的所有对象都被视为同一类;将生成的特征图表示为e∈r128×h×w,从特征图中心位于(x,y)的目标中提取的目标重识别特征为
35、对于图像中的每一gt框获取到目标中心可以抽取一个特征向量并使用一个全连接层和一次softmax操作将其映射到一个类分布向量p={p(k),k∈[1,k]};将gt类标签的one-hot表示为li(k),然后计算目标重识别损失如公式(7)所示:
36、
37、其中,k是类别数量。
38、其中,步骤s4所述的损失监督中的损失函数包括:
39、通过将损失相加来联合训练检测和重新识别分支;使用不确定性损失来自动平衡检测和重新id任务,如公式(8)和(9)所示:
40、ldetection=lheat+lbox (8)
41、
42、其中w1和w2是平衡两个任务的可学习参数;具体来说,给定一个具有一些对象及其对应id的图像,生成热图、框偏移量和尺寸图以及对象的单热编码表示。这些与估计的度量进行比较,以获得损失来训练整个网络。
43、其中,步骤s5所述的跟踪器包含基于匈牙利算法的在线跟踪算法,具体包括:
44、在网络推理时间内,跟踪系统在第一帧中执行跟踪的初始化;在随后的帧中,轨迹集更新边界框、相关检测的分数、外貌特征、指示轨道是否处于活动状态和丢失或移除的“轨道状态”;
45、根据检测框得分,把检测框分为高分框和低分框分开处理;第一次使用高分框检测并计算diou距离与帧间外观相似度形成的相似度矩阵,以此将当前帧与之前轨迹集合关联在一起;第二次使用低分框和第一次没有匹配上高分框的跟踪轨迹计算diou距离与帧间外观相似度形成的相似度矩阵进行匹配;相似度矩阵通过匈牙利算法进行全局分配将检测链接到轨迹集中;
46、对于没有匹配上跟踪轨迹,得分又足够高的检测框,对其新建一个跟踪轨迹;对于没有匹配上检测框的跟踪轨迹,保留30帧,在其再次出现时再进行匹配;最后,所有未匹配的高置信度检测将初始化为新轨迹。
47、本发明通过在一个模型中并行训练两种任务,提高了学习效率的同时减少了推理时间。该方法的核心思想是在一个网络中同时完成目标检测和身份嵌入,通过共享大部分计算量来减少推理时间。
48、本发明将实时视频输入到本发明的网络中,提取出高分辨率的特征映射,通过lsc注意力模块进行特征增强,将获得的特征图分别进行目标检测任务和重识别任务,并进行多目标跟踪。本发明提出的跟踪器采用两阶段跟踪方式,通过提出新的相似度矩阵,实现更好的跟踪效果。本发明提出的无锚单阶段多目标跟踪网络,实现了多目标跟踪的良好的实时性和鲁棒性。
49、本发明的优点是:学习效率高,减少了推理时间,具有良好的实时性和鲁棒性,在跟踪多目标时稳定、精准。
- 还没有人留言评论。精彩留言会获得点赞!