一种通过大数据分析为文化企业进行政策匹配推荐方法与流程
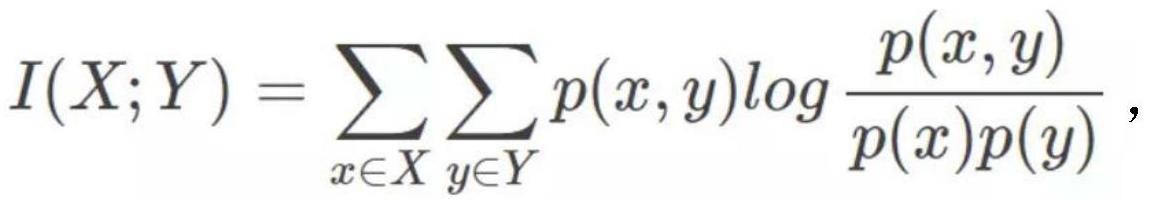
本发明属于大数据,特指一种通过大数据分析为文化企业进行政策匹配推荐方法。
背景技术:
1、随着移动互联网、物联网等新技术的迅速发展,人类进入数据时代,很多数据信息都可以通过互联网进行分类、分析和储存,企业形象和声誉在互联网上以碎片化方式呈现。如何从全媒体海量数据中获得企业在网民中的认知度,绘制出全面的企业网络形象至关重要。
2、为此,现有技术采用根据企业的大数据建立企业画像,企业画像描述的是企业基本情况、经营情况、消费决策和对产品的诉求等多维度企业信息数据,运用企业画像,可以更加全面地了解企业状况。
3、然而现有技术不够完善,中央及各级政府每年发布大量的扶持政策,通过政策引导企业的发展,但是由于政策信息存在数据格式不统一、信息海量、关键信息难以分辨等问题,导致难以快速地匹配和推荐合适的政策给企业。
技术实现思路
1、为克服现有技术的不足及存在的问题,本发明提供一种通过大数据分析为文化企业进行政策匹配推荐方法。
2、为实现上述目的,本发明采用如下技术方案:
3、一种通过大数据分析为文化企业进行政策匹配推荐方法,包括:
4、步骤1:获取政策数据;
5、步骤2:获取文化企业数据,其中,文化企业数据来源于一体化数字资源系统;
6、步骤3:基于自然语言处理方法对政策数据进行处理得到政策要点,基于分类模型对政策要点进行分类得到政策数据所属类型;
7、步骤4:建立数据仓库,将文化企业数据、政策要点和政策数据所属类型存储至数据仓库;
8、步骤5:对文化企业数据进行清洗加工和标准化处理;
9、步骤6:根据清洗加工和标准化处理得到的文化企业数据建立文化企业标签集,根据政策要点和政策数据所属类型建立政策标签集,根据文化企业标签集和政策标签集确定匹配度,判断匹配度是否大于匹配阈值,若是则将政策推荐给文化企业。
10、作为优选,所述步骤1,具体包括:
11、步骤11:将政策数据录入在政府部门系统中,其中,政策数据包括发布区域、政策名称、发布单位、兑现单位、政策文号、政策类型、引发时间、适用对象、政策咨询电话、政策有效期和政策源文件;
12、步骤12:将政策数据存储在云关系型数据库中,云关系型数据库通过大数据平台的数据集成功能将云关系型数据库中的政策数据同步至大数据平台。
13、作为优选,所述步骤2,具体包括:
14、步骤21:梳理文化企业数据的数据目录清单;
15、步骤22:根据数据目录清单在一体化数字资源系统上申请文化企业数据;
16、步骤23:通过大数据平台调取申请到的文化企业数据;
17、步骤24:配置更新频率,根据更新频率迭代步骤21至23。
18、作为优选,所述步骤3,具体包括:
19、步骤31:对政策数据进行预处理得到政策特征词集和词类标签集;
20、步骤32:对政策特征词集和词类标签集进行特征选择得到最优的政策特征词和词类标签,将最优的政策特征词和词类标签作为政策要点;
21、步骤33:对分类模型进行训练、优化和评估处理,将政策要点代入处理后的分类模型进行分类得到政策数据所属类型。
22、作为优选,所述分类模型为文本循环神经网络模型。
23、作为优选,所述步骤31,具体包括:
24、步骤311:基于语料清洗方法清洗政策数据;
25、步骤312:将清洗后的政策数据代入jieba分词库切分得到政策特征词集;
26、步骤313:基于词性标注方法在政策特征词集上标注得到词类标签集。
27、作为优选,所述步骤32,具体包括:
28、步骤321:基于词向量的表示方法将政策特征词集和词类标签集处理得到可被计算机识别的政策特征词集和词类标签集;
29、步骤322:将可被计算机识别的政策特征词集和词类标签集代入如下互信息特征选择公式计算得到政策特征词和词类标签的互信息量:
30、
31、式中,i(x,y)是x和y的互信息量,x为政策特征词集,y词类标签集,p(x,y)为x和y联合概率的分布函数,p(x)是x的边缘概率分布函数,p(y)是y的边缘概率分布函数;
32、步骤323:按照政策特征词和词类标签的互信息量由大到小依次排序得到互信息量序列,选择互信息量序列前k个政策特征词和词类标签的互信息量作为最优互信息量子集,将最优互信息量子集对应的政策特征词和词类标签作为最优的政策特征词和词类标签,将最优的政策特征词和词类标签作为政策要点。
33、作为优选,所述步骤33,具体包括:
34、步骤331:对分类模型进行训练;
35、步骤332:通过配置调优方法和策略加持方法对训练后的分类模型进行优化,其中,配置调优方法包括同义词替换配置方法、分词自定义词典配置方法和分词停止词配置方法;
36、步骤333:判断分类模型的准确率是否大于90%,若是则将政策要点代入处理后的分类模型进行分类得到政策数据所属类型,若否则迭代步骤331至333。
37、作为优选,所述步骤4,具体包括:
38、步骤41:根据文化企业数据、政策要点和政策数据所属类型建立数据仓库,数据仓库划分为操作数据层、汇总数据层、数据明细层和应用数据层;
39、步骤42:在政策模型上划分得到企业主题域和政策主题域。
40、作为优选,所述步骤5,具体包括:
41、步骤51:从文化企业数据中抽取企业要素,根据企业要素计算得到要素分值,根据企业要素和要素分值形成企业属性纵表;
42、步骤52:对企业属性纵表进行清洗过滤;
43、步骤53:根据清洗规则对清洗过滤后的企业属性纵表进行清洗加工;
44、步骤54:将企业清洗加工后的企业属性纵表转换为企业属性横表;
45、步骤55:获取清洗加工后企业属性纵表中的企业注册地址,将企业注册地址代入地理编码api得到企业注册地址的经纬度,将企业注册地址的经纬度代入逆地理编码标准化更新得到清洗加工后企业属性纵表中的企业注册地址和所属行政区划,从而实现企业注册地址和所属行政区划的标准化处理。
46、作为优选,所述步骤53,具体包括:
47、统计清洗过滤后企业属性纵表中的缺失字段,对缺失字段进行清洗;
48、统计清洗过滤后企业属性纵表中的格式内容,对格式内容进行清洗;
49、统计清洗过滤后企业属性纵表中的重复内容,对重复内容进行合并,保留了有效的数据,避免数据发生重复;设置合法性检测规则,基于合法性检测规则检查中间表是否合法,若否则对中间表进行舍弃或重新取值。
50、作为优选,统计清洗过滤后企业属性纵表中的缺失字段,对缺失字段进行清洗的步骤,具体包括:
51、步骤531:统计清洗过滤后企业属性纵表中的缺失字段,统计缺失字段的缺失率,基于缺失字段匹配表统计缺失字段的重要性,其中,缺失字段匹配表包括缺失字段和缺失字段重要性的映射关系;
52、步骤532:判断缺失字段的缺失率是否大于缺失阈值,若是则丢弃缺失字段,若否则判断缺失字段重要性是否大于权重阈值,若否则丢弃缺失字段,若是则采用补全字段表对缺失字段进行补全,其中,补全字段表包括缺失字段和缺失字段对应补全字段的映射关系。
53、作为优选,统计清洗过滤后企业属性纵表中的格式内容,对格式内容进行清洗,具体包括:
54、步骤533:统计清洗过滤后企业属性纵表中的格式内容;
55、步骤534:基于数据标准对清洗过滤后企业属性纵表中的格式内容进行标准化处理。
56、步骤535:对清洗过滤后的企业属性纵表进行归一化处理。
57、作为优选,所述步骤6,具体包括:
58、步骤61:根据清洗加工和标准化处理得到的文化企业数据建立得到文化企业标签集;
59、步骤62:将政策要点和政策数据所属类型代入政策规则建立得到政策标签集;
60、步骤63:将文化企业标签集和政策标签集进行匹配并计算得到匹配权重集和匹配分值集,将匹配权重集和匹配分值集代入如下公式计算得到匹配度:
61、
62、其中,ppd为匹配度,β1…βn为第一匹配权重…第n匹配权重,n1…nn为第一匹配分值…第n匹配分值,e为欧拉数;
63、步骤64:判断匹配度是否大于匹配阈值,若是则将政策推荐给文化企业。
64、本发明相比现有技术突出且有益的技术效果是:
65、在本发明中,通过对文化企业数据进行清洗加工和建立标签等处理,通过对政策数据进行预处理、特征选择、训练优化和建立标签等处理,最终进行标签匹配从而达到为海量的文化企业匹配上合适政策或者为不同的政策寻找到合适企业的效果,因此本发明具有自动匹配、适配效果好、数据可读性强的优点。
66、在本发明中,可采用海量的历史文化企业数据和政策数据对分类模型进行训练从而提高文化企业和政策匹配的准确性,有助于提高本发明的权威性和可靠性。
- 还没有人留言评论。精彩留言会获得点赞!