一种水平划分数据集的差分隐私保护安全多方数据发布方法
本发明属于数据安全与隐私保护领域,涉及一种水平划分数据集的差分隐私保护安全多方数据发布方法。
背景技术:
1、随着大数据技术的快速发展,高维数据如医疗保健数据或者用户行为数据,被收集并用于不同目的。通常,这些数据被不同的公司或机构拥有,把这些数据聚合起来,可以更好地支持决策或提供服务。但是,各方持有的数据集可能包含个体的敏感信息,如果各方简单地集成本地数据集并共享,会对数据集中个体的隐私构成严重威胁。所以,在聚合各方的数据集的时候,应该满足隐私保护要求。
2、近年来,隐私保护数据发布问题引起了学者们的关注,在多次尝试定义数据发布中的隐私要求之后,差分隐私成为大家广泛接受的隐私模型。与传统隐私模型(如k-匿名,l-多样性)不同,差分隐私为数据发布提供了强有力的理论保证,不会受到攻击者背景知识的影响。
3、差分隐私保护数据发布问题目前已被广泛研究,有单方发布方法也有多方发布方法。单方发布方法有privbayes、jtree、pivsyn等。privbayes是用贝叶斯网络定义一组加噪低维分布,来近似输入数据的联合分布;jtree是从依赖图中识别出一组边缘分布表,以基于结树算法的推理基础来近似联合分布;pivsyn则是用大量的低维边缘分布更新一个初始数据集,最终得到和低维边缘分布接近的合成数据集。前述3种方法都是通过估计低维边缘分布得到近似的总体联合分布,其中pivsyn性能最优,此方法在“nist.2018differentialprivacy synthetic data challenge”比赛中曾经被提出。多方发布方法有后提出的dp-subn、dplt等。dp-subn用于水平划分数据集场景,在第三方的帮助下,各个参与者共同初始化一个贝叶斯网络结构并以串行方式对其进行更新,然后学习贝叶斯网络的参数,最后第三方从贝叶斯网络抽样得到数据集;dplt则是用于垂直划分数据集场景,在第三方的帮助下,任两方分别生成一个隐树模型(特殊的贝叶斯网络结构),并将两个索引树(即只有隐属性节点)合并为一个树,然后第三方对其进行抽样,得到数据集。前述方法中,privbayes、jtree、dp-subn、dplt都是把低维边缘分布放到图模型中,并用采样的方法生成合成数据集,当图比较密集,算法效率就不高,对于需要用到安全多方计算的多方场景,复杂度更甚,而pivsyn没有采用图模型,而是用大量低维边缘分布更新初始合成数据集,看起来就简单高效很多。
4、因此,本发明受pivsyn启发,将其扩展到多方场景下,不像dp-subn、dplt一样用繁琐的图模型来表示数据集,而是选择一些关联度高的属性组合,并用它们的低维边缘分布更新随机初始化的合成数据集,使得最终合成数据集的分布与所有的低维边缘分布接近。
技术实现思路
1、发明目的:本发明提供一种水平划分数据的差分隐私保护安全多方数据发布方法,将现有的单方数据合成方案pivsyn扩展到多方,可用于安全多方数据发布,应用范围更加广泛。
2、为实现上述发明目的,本发明所提供的技术方案如下:
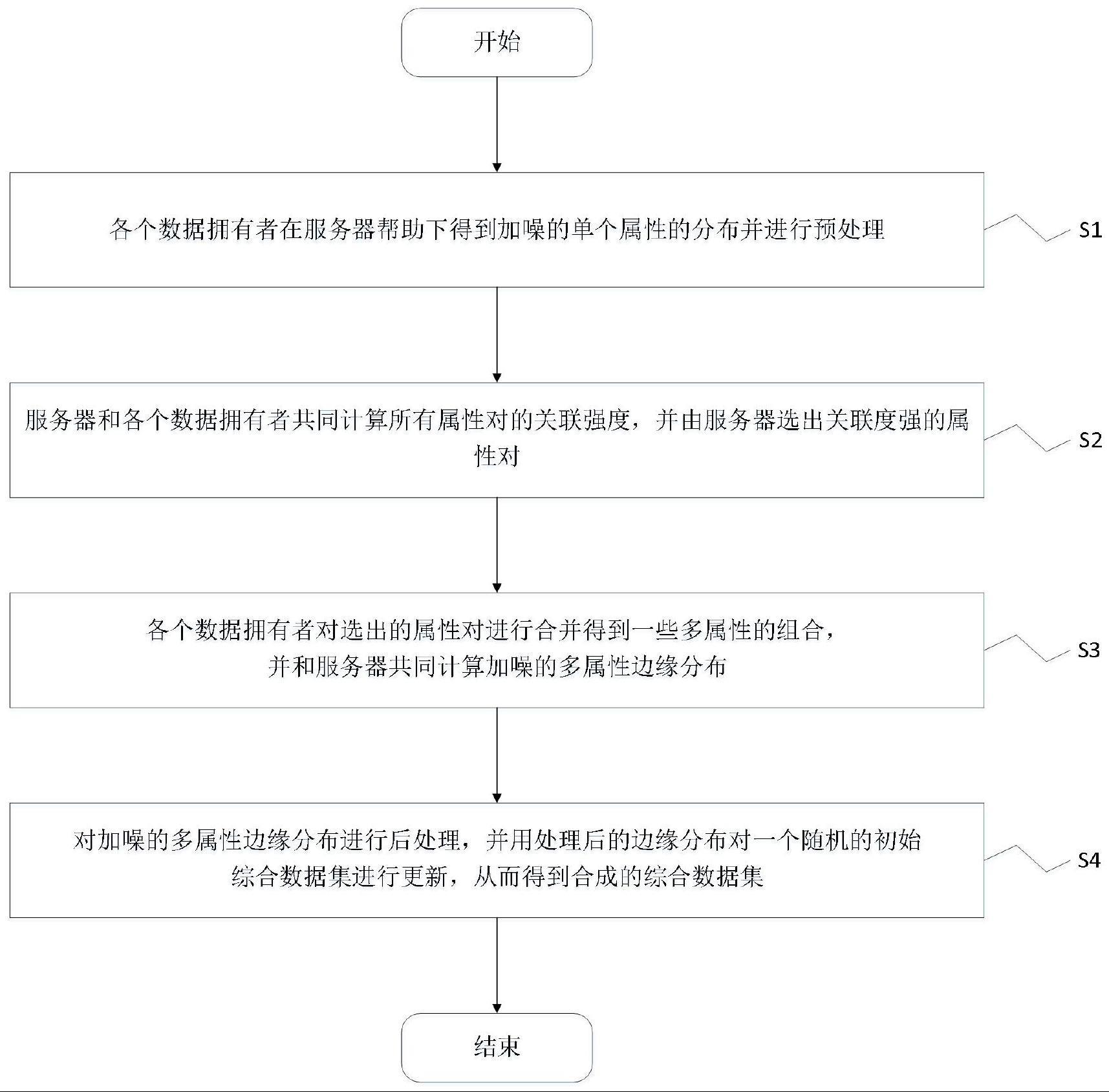
3、一种水平划分数据的差分隐私保护安全多方数据发布方法,包括以下步骤:
4、s1、各个数据拥有者在服务器帮助下得到加噪的单个属性的分布并进行预处理;
5、其中,所加的噪声为拉普拉斯噪声,由4个服从正态分布的高斯变量yi~n(0,λ/2),i∈{1,2,3,4}产生:其中lap(λ)的概率分布函数为且每个数据拥有者都有4个高斯变量;
6、s2、服务器和各个数据拥有者共同计算所有属性对的关联强度,并由服务器选出关联度强的属性对;
7、假设有d个属性x1,…,xd,则需计算所有个属性对的关联强度,关联强度用indifa,b=|ma,b-ma×mb|22衡量,其中ma,b是属性对ab的真实联合分布,ma×mb是假设属性a和b独立,它们的分布的外积,m是分布表,|·|2表示二范数;
8、属性对选择问题可以转换为一个优化问题:
9、
10、其中每个属性对对应一个标号i(i∈{1,…,m});示性变量xi=1表示属性对被选择,反之未被选择;ψi是由拉普拉斯噪声引入的噪声误差,取l1误差,即ψi=ci*λi,其中ci是第i个属性对的大小,即ci=2(i∈{1,...,m}),而λi是第i个属性对所加拉普拉斯噪声的尺度;φi表示由属性对应该被选择但却没有被选引起的依赖误差,且φi和indifi正相关,所以对φi进行近似:φi≈indifi+noise(noise是和步骤(s1)一样用高斯变量生成的拉普拉斯噪声,隐私预算不同);
11、s3、各个数据拥有者对选出的属性对进行合并得到一些多属性的分布,并和服务器共同计算加噪的多属性边缘分布(即多个属性的联合分布);
12、s4、对加噪的多属性边缘分布进行后处理,并用处理后的边缘分布对一个随机的初始综合数据集进行更新,从而得到合成的综合数据集。
13、进一步的,步骤(s1)包括如下过程:
14、各个数据拥有者在服务器的帮助下得到加噪的单个属性的分布;
15、数据拥有者们对得到的加噪的单个属性的分布进行预处理,即筛选并合并低频率的取值。
16、进一步的,步骤(s2)包括如下过程:
17、各个数据拥有者为所有属性对以及属性对涉及的两个属性分配标号(服务器不会知道),并将各自数据集中属性对的分布以及涉及的两个属性的分布用阈值paillier算法进行加密,然后发给服务器;
18、服务器用indifa,b=|ma,b-ma×mb|22计算每个属性对的indif;
19、服务器选出使总体误差最小的一些属性对,返回被选属性对的标号。
20、进一步的,步骤(s3)包括如下过程:
21、服务器将步骤(s2)选出的属性对的标号(服务器不知道哪个标号对应哪个属性对)发给各个数据拥有者,各个数据拥有者进行同样的属性对合并操作,得到一些属性组合;
22、各个数据拥有者再次为合并操作后得到的多属性组合标号,并和服务器共同计算加噪的多属性边缘分布,噪声以和步骤(s1)相同的方式产生,加噪的多属性边缘分布由服务器聚合得到,且服务器仍不知道哪个标号对应哪个多属性组合。
23、进一步的,步骤(s4)包括如下过程:
24、服务器将步骤(s3)得到的加噪多属性边缘分布发给某个数据拥有者,该数据拥有者对加噪的多属性边缘分布进行后处理操作以确保噪声边缘分布一致;
25、该数据拥有者初始化一个综合数据集;
26、该数据拥有者用后处理得到的加噪边缘分布对初始综合数据集进行更新,最终得到合成数据集。
27、有益效果:本发明将现有的高效合成数据集方案pivsyn拓展到多方场景,一方面避免了以往多方数据发布中图模型的使用,效率更高,另一方面将pivsyn的应用场景扩展到多方,同时利用安全多方计算技术保护了各方的数据隐私,使得应用更加广泛。
- 还没有人留言评论。精彩留言会获得点赞!