命名实体识别的模型训练及识别方法、装置和存储介质与流程
本技术涉及人工智能领域,尤其涉及一种命名实体识别的模型训练及识别方法、装置和存储介质。
背景技术:
1、命名实体识别(named entity recognition,ner)任务是对文本中的命名实体进行定位并划分为预定义的实体类别的过程。命名实体的类别主要包括人名、地名、机构名、媒体资源名、专有名等。ner任务是许多自然语言应用的基础,例如,问答、文本摘要和机器翻译等。
2、随着网络及相关技术的发展,媒体资源具有数量庞大、实时更新并且没有相关的标注数据集等特点。针对这一特定领域的命名实体识别任务,现有的技术并不能取得满意的效果。媒体资源数据的更新迭代较快,且不同频道的媒体资源数据特点存在较大差异,如影视类的媒体资源的名称命名与教育、体育等频道差异较大,基于规则的方法无法涵盖所有的语法规则和词典。缺少标注数据,基于深度学习的方法无法进行学习。缺少媒体资源名称的高质量表示,基于聚类的方法无法获得较好的结果。
技术实现思路
1、有鉴于此,本技术实施例提供了一种命名实体识别的模型训练及识别方法、装置和存储介质,旨在提高媒体资源领域的实体名称识别性能。
2、本技术实施例的技术方案是这样实现的:
3、本技术实施例提供了一种命名实体识别的模型训练方法,包括:
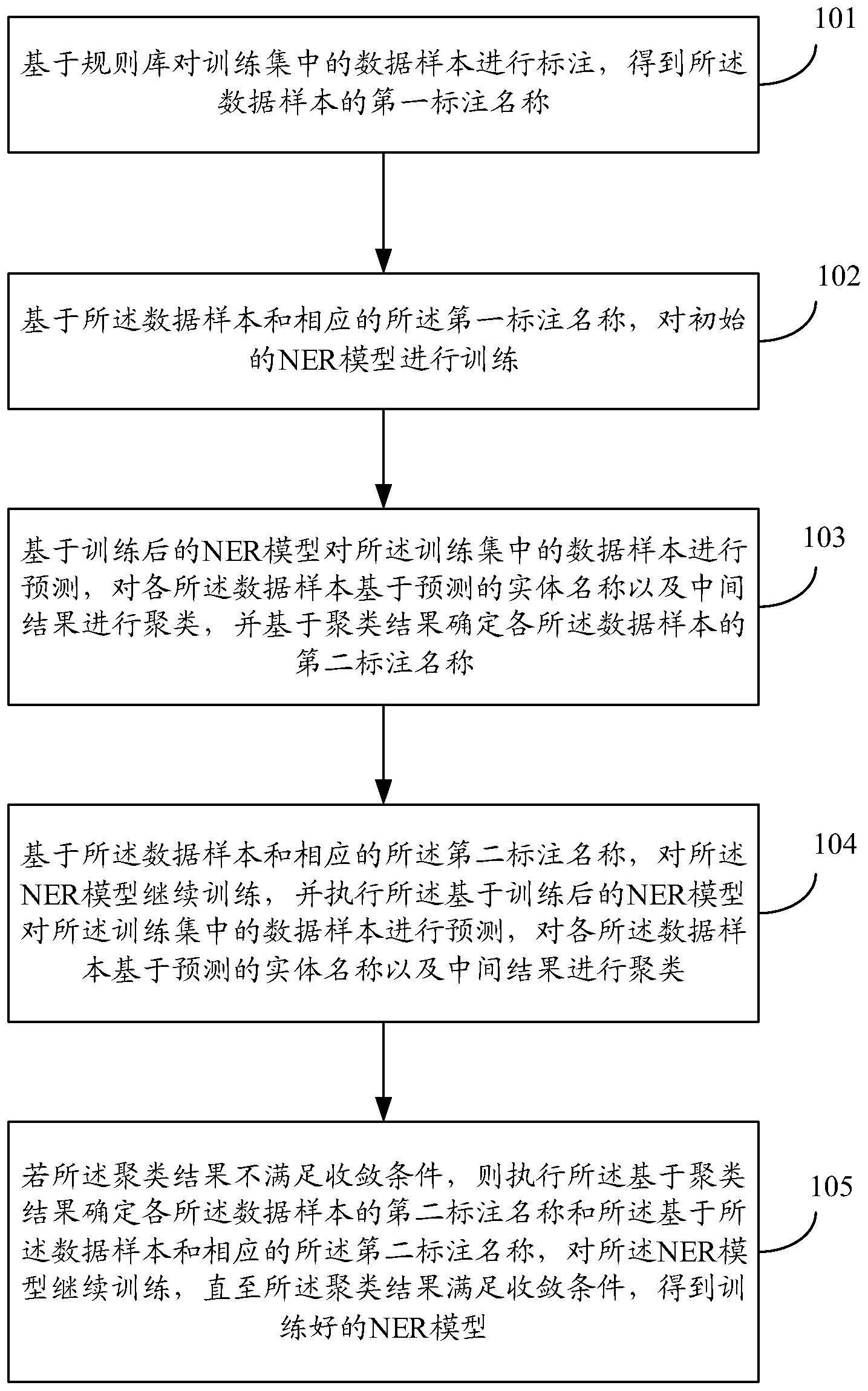
4、基于规则库对训练集中的数据样本进行标注,得到所述数据样本的第一标注名称;
5、基于所述数据样本和相应的所述第一标注名称,对初始的ner(命名实体识别)模型进行训练;
6、基于训练后的ner模型对所述训练集中的数据样本进行预测,对各所述数据样本基于预测的实体名称以及中间结果进行聚类,并基于聚类结果确定各所述数据样本的第二标注名称;
7、基于所述数据样本和相应的所述第二标注名称,对所述ner模型继续训练,并执行所述基于训练后的ner模型对所述训练集中的数据样本进行预测,对各所述数据样本基于预测的实体名称以及中间结果进行聚类;
8、若所述聚类结果不满足收敛条件,则执行所述基于聚类结果确定各所述数据样本的第二标注名称和所述基于所述数据样本和相应的所述第二标注名称,对所述ner模型继续训练,直至所述聚类结果满足收敛条件,得到训练好的ner模型。
9、上述方案中,所述方法还包括:
10、获取所述数据样本的属性特征;
11、相应地,所述对各所述数据样本基于预测的实体名称以及中间结果进行聚类,并基于聚类结果确定各所述数据样本的第二标注名称,包括:
12、基于所述数据样本的预测的实体名称、中间结果及所述属性特征进行聚类处理,得到聚类后的簇;
13、将各簇的簇中心所在的数据样本的预测的实体名称确定为相应簇的所有数据样本的第二标注名称。
14、上述方案中,所述数据样本为媒体资源名称,所述属性特征包括以下至少之一:媒体资源的海报信息、媒体资源年份信息、媒体资源类型和媒体资源的演员信息。
15、上述方案中,所述基于所述数据样本的预测的实体名称、中间结果及所述属性特征进行聚类处理,得到聚类后的簇,包括:
16、基于所述数据样本的预测的实体名称、中间结果及所述属性特征进行编码转换,得到表示所述数据样本的特征向量;
17、对各所述数据样本的特征向量基于相似度进行聚类处理,得到聚类后的簇。
18、上述方案中,所述聚类结果满足收敛条件,包括:
19、基于训练集中各所述数据样本距离所属簇的簇中心的误差平方和确定聚类收敛且簇内各数据样本的预测的实体名称相同。
20、上述方案中,所述规则库包括以下至少之一:白名单、过滤规则和转换规则,所述基于规则库对训练集中的数据样本进行标注,包括以下至少之一:
21、基于白名单对所述数据样本进行匹配,若匹配成功,则将匹配的实体名称作为所述第一标注名称,其中,所述白名单包括预设的实体名称;
22、基于过滤规则对所述数据样本进行文本过滤处理和/或基于转换规则对所述数据样本进行文本转换处理,将转换处理后的文本作为所述第一标注名称。
23、上述方案中,所述方法还包括:
24、基于所述数据样本和相应的所述第二标注名称,更新所述规则库。
25、第二方面,本技术实施例提供了一种命名实体识别方法,包括:
26、获取待识别数据;
27、将所述待识别数据输入本技术实施例第一方面所述方法训练得到的ner模型,得到所述待识别数据的实体名称。
28、第三方面,本技术实施例提供了一种命名实体识别的模型训练装置,包括:
29、规则标注模块,用于基于规则库对训练集中的数据样本进行标注,得到所述数据样本的第一标注名称;
30、第一训练模块,用于基于所述数据样本和相应的所述第一标注名称,对初始的ner模型进行训练;
31、预测及聚类模块,用于基于所述第一训练模块训练后的ner模型对所述训练集中的数据样本进行预测,对各所述数据样本基于预测的实体名称以及中间结果进行聚类,并基于聚类结果确定各所述数据样本的第二标注名称;
32、第二训练模块,用于基于所述数据样本和相应的所述第二标注名称,对所述ner模型继续训练;
33、所述预测及聚类模块还用于基于所述第二训练模块训练后的ner模型对所述训练集中的数据样本进行预测,对各所述数据样本基于预测的实体名称以及中间结果进行聚类;若所述聚类结果不满足收敛条件,则基于聚类结果确定各所述数据样本的第二标注名称和由所述第二训练模块对所述ner模型继续训练,直至所述聚类结果满足收敛条件,得到训练好的ner模型。
34、第四方面,本技术实施例提供了一种命名实体识别装置,包括:
35、获取模块,用于获取待识别数据;
36、识别模块,用于将所述待识别数据输入本技术实施例第三方面所述模型训练装置训练得到的ner模型,得到所述待识别数据的实体名称。
37、第五方面,本技术实施例提供了一种命名实体识别的模型训练设备,包括:处理器和用于存储能够在处理器上运行的计算机程序的存储器,其中,所述处理器,用于运行计算机程序时,执行本技术实施例第一方面所述方法的步骤。
38、第六方面,本技术实施例提供了一种命名实体识别设备,包括:处理器和用于存储能够在处理器上运行的计算机程序的存储器,其中,所述处理器,用于运行计算机程序时,执行本技术实施例第二方面所述方法的步骤。
39、第七方面,本技术实施例提供了一种计算机存储介质,所述计算机存储介质上存储有计算机程序,所述计算机程序被处理器执行时,实现本技术实施例第一方面或者第二方面所述方法的步骤。
40、本技术实施例提供的技术方案,基于规则库对训练集中的数据样本进行标注,得到数据样本的第一标注名称;基于数据样本和相应的第一标注名称,对初始的ner模型进行训练;基于训练后的ner模型对训练集中的数据样本进行预测,对各数据样本基于预测的实体名称以及中间结果进行聚类,并基于聚类结果确定各数据样本的第二标注名称;基于数据样本和相应的第二标注名称,对ner模型继续训练,直至聚类结果满足收敛条件,得到训练好的ner模型。由于融合基于规则、深度学习和聚类的方法,既可以利用规则库实现样本的自动标注,还可以基于聚类对预测结果进行校准和后续模型的优化训练,如此,可以有效改善ner模型的训练效果,进而提高实体名称的识别性能。
- 还没有人留言评论。精彩留言会获得点赞!