文本搜索模型的训练方法及装置、计算设备与流程
本技术涉及文本搜索,尤其涉及一种文本搜索模型的训练方法及装置、计算设备。
背景技术:
1、近年来,随着大数据技术的快速发展及人工智能算法的落地,数字化赋能各行各业。在一些场景中,用户期待基于大数据技术完成文本搜索任务,以在海量的文本数据库中获取目标文本。然而,目前的文本搜索方法的准确性仍有待提高。
技术实现思路
1、本技术实施例提供一种文本搜索模型的训练方法及装置、计算设备,能够有利于提高文本搜索的准确性。
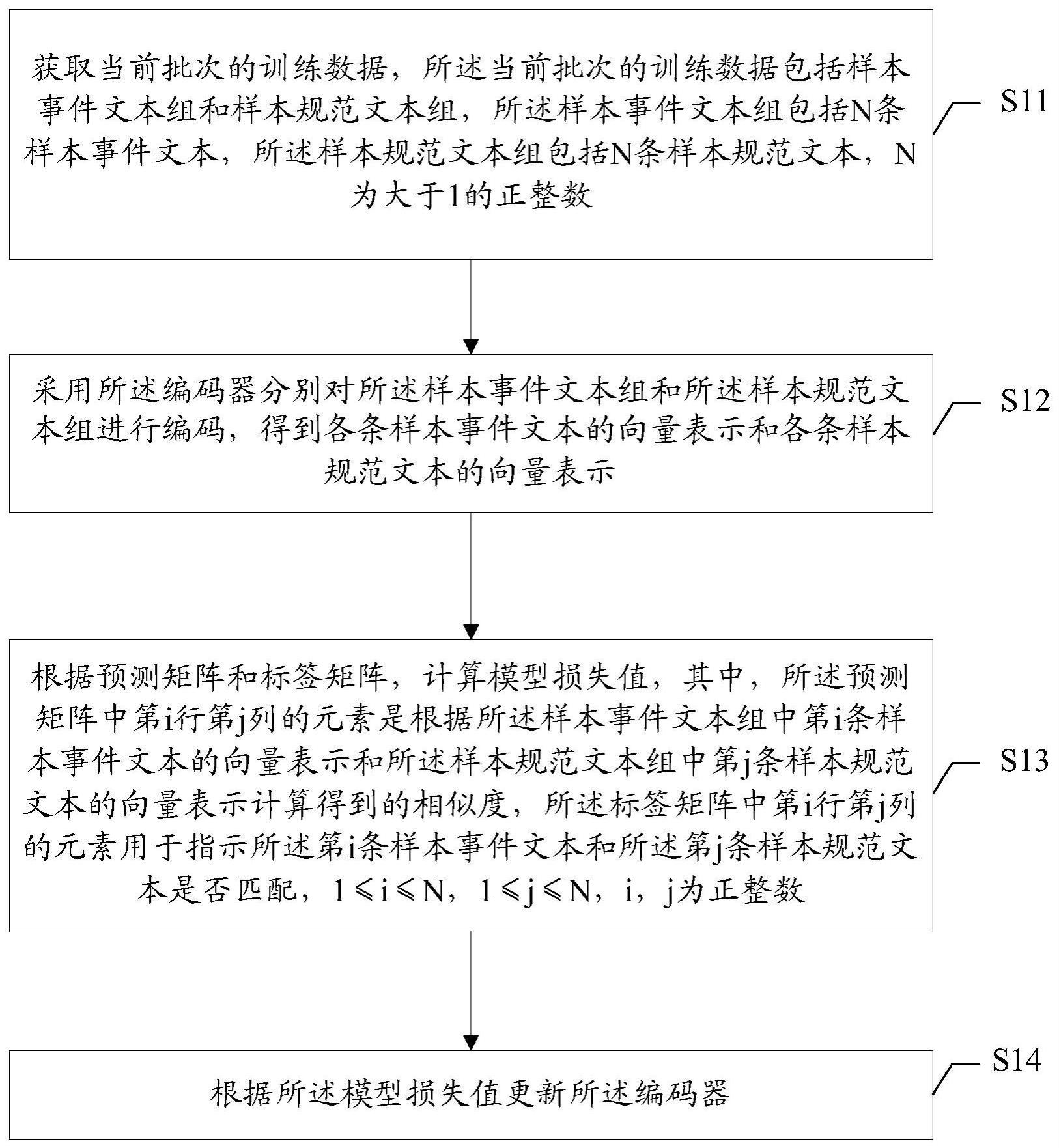
2、本技术实施例提供一种文本搜索模型的训练方法,所述文本搜索模型包括编码器,所述方法包括:获取当前批次的训练数据,所述当前批次的训练数据包括样本事件文本组和样本规范文本组,所述样本事件文本组包括n条样本事件文本,所述样本规范文本组包括n条样本规范文本,n为大于1的正整数;采用所述编码器分别对所述样本事件文本组和所述样本规范文本组进行编码,得到各条样本事件文本的向量表示和各条样本规范文本的向量表示;根据预测矩阵和标签矩阵,计算模型损失值,其中,所述预测矩阵中第i行第j列的元素是根据所述样本事件文本组中第i条样本事件文本的向量表示和所述样本规范文本组中第j条样本规范文本的向量表示计算得到的相似度,所述标签矩阵中第i行第j列的元素用于指示所述第i条样本事件文本和所述第j条样本规范文本是否匹配,1≤i≤n,1≤j≤n,i,j为正整数;根据所述模型损失值更新所述编码器。
3、可选的,所述n条样本事件文本所属的事件类别各不相同。
4、可选的,获取当前批次的训练数据包括:获取所述n条样本事件文本;根据所述标签矩阵中第j列的n个元素和所述n条样本事件文本,从规范文本数据库中抽取所述第j条样本规范文本。
5、可选的,所述标签矩阵中第j列的元素中仅单个元素为1,所述规范文本数据库包括多个规范文本集合,根据所述标签矩阵中第j列的n个元素和所述n条样本事件文本,从规范文本数据库中抽取所述第j条样本规范文本包括:确定所述第j列的元素中值为1的元素对应的样本事件文本,记为第j列的正例事件文本;从所述第j列的正例事件文本关联的规范文本集合中抽取所述第j条样本规范文本。
6、可选的,所述规范文本集合包括多个样本规范文本单元,从所述第j列的正例事件文本关联的规范文本集合中抽取所述第j条样本规范文本包括:从所述第j列的正例事件文本关联的样本规范文本单元中抽取所述第j条样本规范文本。
7、可选的,所述标签矩阵中第i行第i列的元素均为1,其余元素均为0。
8、可选的,所述编码器包括第一编码器和第二编码器,采用所述编码器分别对所述样本事件文本组和所述样本规范文本组进行编码包括:采用所述第一编码器对所述样本事件文本组进行编码,得到各条样本事件文本的向量表示;采用所述第二编码器对所述样本规范文本组进行编码,得到各条样本规范文本的向量表示。
9、可选的,所述第一编码器和所述第二编码器均为句向量编码器。
10、可选的,所述方法还包括:获取诉求事件文本;将所述诉求事件文本输入至所述编码器,得到所述编码器输出的事件文本向量;获取多条候选规范文本向量;根据所述事件文本向量和各条候选规范文本向量之间的相似度,从多条候选规范文本中确定至少一条目标规范文本,所述目标规范文本为与所述诉求事件文本相匹配的规范文本。
11、本技术实施例还提供一种文本搜索模型的训练装置,所述文本搜索模型包括编码器,所述装置包括:获取模块,用于获取当前批次的训练数据,所述当前批次的训练数据包括样本事件文本组和样本规范文本组,所述样本事件文本组包括n条样本事件文本,所述样本规范文本组包括n条样本规范文本,n为大于1的正整数;编码模块,用于采用所述编码器分别对所述样本事件文本组和所述样本规范文本组进行编码,得到各条样本事件文本的向量表示和各条样本规范文本的向量表示;损失计算模块,用于根据预测矩阵和标签矩阵,计算模型损失值,其中,所述预测矩阵中第i行第j列的元素是根据所述样本事件文本组中第i条样本事件文本的向量表示和所述样本规范文本组中第j条样本规范文本的向量表示计算得到的相似度,所述标签矩阵中第i行第j列的元素用于指示所述第i条样本事件文本和所述第j条样本规范文本是否匹配,1≤i≤n,1≤j≤n,i,j为正整数;更新模块,用于根据所述模型损失值更新所述编码器。
12、本技术实施例还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器运行时,执行上述的文本搜索模型的训练方法的步骤。
13、本技术实施例还提供一种计算设备,包括存储器和处理器,所述存储器上存储有可在所述处理器上运行的计算机程序,所述处理器运行所述计算机程序时执行上述的文本搜索模型的训练方法的步骤。
14、与现有技术相比,本技术实施例的技术方案具有以下有益效果:
15、在本技术实施例的方案中,每个批次的训练数据包括:样本事件文本组和样本规范文本组,样本规范文本组包括n条样本规范文本,样本事件文本组包括n条样本事件文本,然后采用编码器分别对样本事件文本组和样本规范文本组进行编码,得到各条样本事件文本的向量表示和各条样本规范文本的向量表示,进一步根据预测矩阵和标签矩阵计算模型损失值,并根据模型损失值更新编码器。
16、上述方案中,预测矩阵中第i行第j列的元素是根据第i条样本事件文本的向量表示和第j条样本规范文本的向量表示计算得到的相似度,标签矩阵中第i行第j列的元素用于指示第i条样本事件文本和第j条样本规范文本是否匹配,由此,通过单个批次的训练能够使得编码器学习到多个样本事件文本各自匹配的规范文本的向量表示和/或不匹配的规范文本的向量表示。通过多批次的训练,进一步能够使匹配同一事件类别的规范文本的向量表示在语义空间内的距离不断减小和/或使匹配不同事件类别的规范文本的向量表示在语义空间内的距离不断增大,从而后续能够使用文本搜索模型准确地搜索到事件文本相匹配的规范文本。
17、进一步,样本规范文本组中n条样本事件文本所属的事件类别各不相同。采用这样的方案,能够在单批次的训练中对各个事件类别的正例样本和/或负例样本进行学习,有利于提高训练效率。
18、进一步,标签矩阵中第j列的元素中仅有1个元素为1,其余元素均为0。采用上述方案,仅根据标签矩阵中单个元素的值抽取第j条样本规范文本,即可使得第j条样本规范文本和n条样本事件文本中各条样本事件文本均满足标签矩阵中第j列的元素的要求。有利于提高获取样本规范文本组的效率,从而提高训练效率。
19、进一步,本技术实施例的方案中,分别为事件文本和规范文本各自设置编码器,通过训练能够使得两个编码器分别对不同的语言结构或者语言模态的文本进行各自的向量化编码,相较于采用同一编码器对两种不同的语言结构或者语言模态的文本进行编码的方案,上述方案能够提高文本向量表示的准确性,从而有利于提高文本搜索的准确性。
20、进一步,本技术实施例的方案,第一编码器和第二编码器均为句向量编码器,由此,编码得到的事件文本的向量表示和规范文本的向量表示均为句向量,相较于采用词向量来表征文本的方案,上述方案能够更加充分地表达文本的语义,有利于提高文本搜索的准确性。
- 还没有人留言评论。精彩留言会获得点赞!