一种基于GRM模型的作业四象限评估学生能力方法与流程
本发明涉及机器学习的,具体涉及一种基于grm模型的作业四象限评估学生能力方法。
背景技术:
1、作业在教育教学中一直扮演着重要的角色,在教育教学中具有非常重要的意义。通过作业,老师可以了解学生掌握新知识及新旧知识整合的程度,学生也可以通过做作业达到对所学知识的整理、巩固、深入理解和灵活运用。布置适量的作业是老师了解学生掌握知识情况的必要手段。布置适量的作业是检验学生学习心理和能力的重要途径。通过对学生完成的作业进行评估,教师可掌握学生的认知能力、认知类型和认知水平,特别是一些活动作业,更能体现出学生的学习心理品质,有助于培养和发展学生的思维能力、综合能力、创造能力和自我教育能力,更有助于老师发现学生的特长、禀性,便于对症下药、因材施教。
2、现有对完成的作业进行评估的方法主要是依据于任课教师对学生完成的作业进行批改,继而对该学生的作业进行评估,给出提升改进建议。但是任课教师对学生作业进行批改、评估,在主观上主要是根据自己的经验、意图等进行作业的批改,具有主观性,不够客观、准确。且任课教师对作业进行批改、评估,存在着费时费力的问题,如果群体数量不够大时还可以进行,但是如果群体数目达到一定数量,那么将无法快速、及时地对学生的作业进行评估,提出提升改进意见,再者,任课教师对作业进行批改、评估,不能很好地考虑到学生个人能力与试题难度的问题,任课教师不太可能清楚地记得每个学生的能力水平高低,这道题对于该学生而言是较为简单还是较为困难,因为有这个局限,教师对学生提出的建议就不能够很好地针对于不同能力的学生做出对应的评估。
技术实现思路
1、本发明克服现有技术的不足,提供了一种基于grm模型的作业四象限评估学生能力方法。本发明的目的通过以下的技术方案实现:
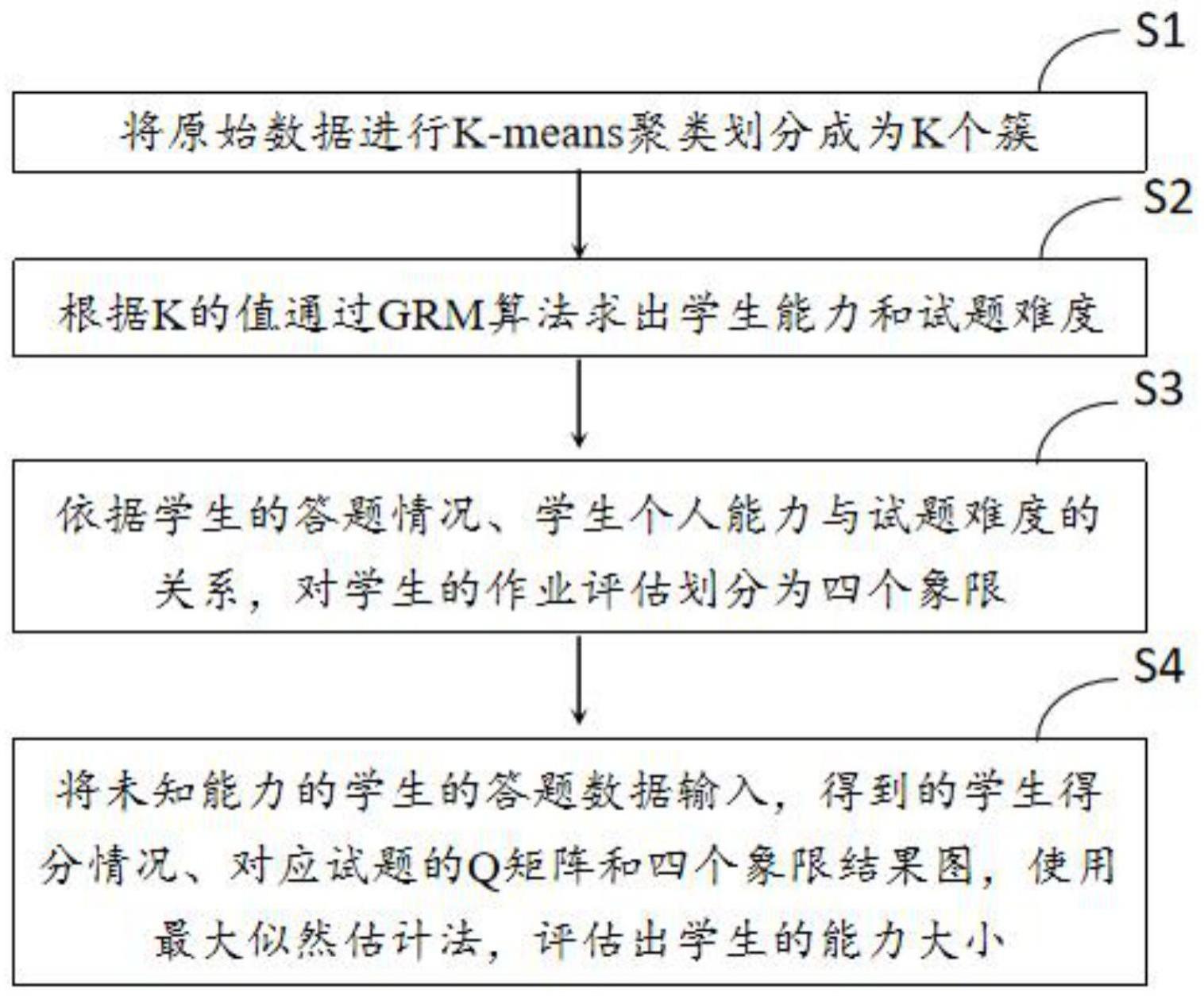
2、一种基于grm模型的作业四象限评估学生能力方法,包括:
3、s1:将原始数据进行k-means聚类划分成为k个簇;
4、s2:根据k的值通过grm算法求出学生能力和试题难度;
5、s3:依据学生的答题情况、学生个人能力与试题难度的关系,对学生的作业评估划分为四个象限;
6、s4:将未知能力的学生的答题数据输入,得到的学生得分情况、对应试题的q矩阵和四个象限结果图,使用最大似然估计法,评估出学生的能力大小。
7、优选的,所述s1中,原始数据包括学生在学习系统答题时的学生id、题目id、测评的结果、测评点个数、通过测评点个数、题目类型和题目得分。
8、更优的,首先需要进行判断学生是否参与作答了此题,如果没有参与作答,则筛除未参与作答的用户;如果学生已参与作答,则答题次数+1,同时判断该学生通过测评点个数与测评点个数是否相同,如果相等,则答对题目次数+1,同时记录下是在第几次答对;原始数据经过处理,转换成一个记录着学生对应的总共答题次数,在第几次时答对,答题正确率的数据表。
9、优选的,所述s1中,通过引入轮廓系数s确定k,计算公式如下:
10、
11、其中a表示样本点与同一簇中所有其他点的平均距离,即样本点与同一簇中其他点的相似度;b表示样本点与下一个最近簇中所有点的平均距离,即样本点与下一个最近簇中其他点的相似度,s∈(-1,1)。
12、优选的,所述k-means聚类将原始数据划分成k个簇,并给出每个样本数据对应的中心点。具体步骤如下:
13、①随机选取k个中心,记为
14、②定义损失函数:
15、
16、其中xi代表第i个样本,ci是xi所属的簇,代表簇对应的中心点,m是样本总数,j是定义的损失函数;j(c,t)
17、③令z=0,1,2......为迭代步数,重复如下过程直到j收敛:
18、a:对于每一个样本xi将l其分配到距离最近的中心
19、
20、b:对于每一个类中心k,重新计算该类的中心
21、
22、首先固定中心点,调整每个样本所属的类别以减少j,再固定每个样本的类别,调整中心点继续减小j,两个过程交替循环,j单调递减直到最小值,中心点和样本划分的类别同时收敛;
23、④学生答题时越早答对,答题正确率越高,则该题目就属于更好的一类,同时规定了k的范围在2-14之间,即一道题目最少可以分为两类,最多可以分为14类,通过迭代寻找到每一道题目最适合的轮廓系数,确定样本中心;
24、⑤最终输出每一道题目对应的k值——簇,通过这个k值得到参与作答本道题的学生被分为几类,最后依据排序算法,根据前面的聚类结果对不同类别学生赋予分值,最后生成一个学生得分情况与对应试题的矩阵表q。
25、优选的,所述s2中,k-means聚类得到n+1个类别,则难度系数就有n个,用户的得分情况有n+1种。项目难度参数有大小顺序,等级越高难度越大,学生i在题目j上得k及k分以上的概率p为:
26、
27、其中θi表示第i位学习者的能力大小,d为常量,αj表示第j道题目的试题区分度,βjk表示试题j得k分的难度。
28、更优的,所述学习者能力大小的判断要依据于学生第一次答对题目在第几次以及学生作答的正确率二者的数据,用户答对题目的次数越前,正确率越高,则说明该用户的能力越强;
29、学习者i在试题j中得k分的概率得分概率的计算为:
30、p(xij=k)=p(xij≥k)-p(xij≥k+1)
31、其中p(xij≥k)表示学习者i在j题中得分大于或等于k分的概率,p(xij≥k+1)表示学习者i在j题中得分大于或等于k+1分的概率;
32、试题难度的计算公式为:
33、βk=ln((1-pk)/pk)
34、对于多级反应模型,试题难度的计算为:
35、β=(β1+β2+......+βn)/n
36、其中,pk表示的是得k分的概率,βk表示得k分时的难度,n表示难度系数个数,即聚类得到的n+1个类别。
37、所述s3中,四象限中横轴表示学生能力与试题难度的关系,在横轴的负半轴,表示的是试题难度大于学生能力,即对该学生而言为较难的题目,在横轴的正半轴,表示的是试题难度小于学生能力,即对于学生而言是在能力范围之内的题目。试题难度等于学生能力的判断,不能简单的根据数值上的相等,数值即我们前面利用grm模型求出的试题难度、学生能力,而应该根据历史数据,求出能够作答对这道题目的学生能力大小;
38、四象限中纵轴表示学生的答题情况,在纵轴的正半轴,表示的是学生答对了这道题,在纵轴的负半轴,表示的是学生答错了该题目。
39、班级学生平均能力的计算:
40、θ=(θ1+θ2+......+θn)/n
41、其中,θ1表示班级第一名学生的能力,θ2表示班级第二名学生的能力,θn表示最后一名学生的能力,θ1+θ2+......+θn表示班级所有学生的能力相加,n表示班级的总人数。
42、本发明与现有技术相比,还存在以下优点:
43、(1)本发明通过grm算法,依据历史答题数据,求出题目的难度、学生的能力,后续即使是刚加入班级的学生,也能够通过在题库中抽取题目进行测试,通过grm模型评估出该学生的能力大小。
44、(2)本发明通过作业四象限评估方法对学生完成的作业进行评估,评估出学生作答作业的相关情况,避免了传统任课教师评估中的主观性问题,能够对大量的数据进行处理,避免了费时费力的问题,同时也结合学生个人能力与试题难度综合考虑,对于同一道题,针对不同能力的学生,能够给出不同的评估与提升建议。
- 还没有人留言评论。精彩留言会获得点赞!