一种基于故障字典的反事实置信数据生成方法
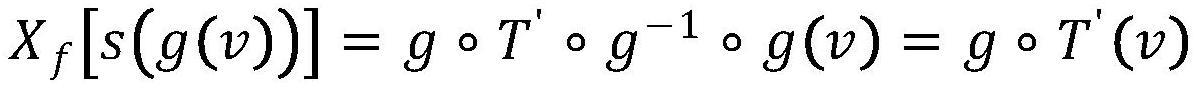
本发明涉及新一代信息,具体是一种基于故障字典的反事实置信数据生成方法。
背景技术:
1、对于机械设备来说,其受到自身材料属性、制造工业、外界环境等的影响,在工作的过程中会出现很多机械故障,进而导致设备终止运转,导致对应的工作流程也被迫中断。为了避免因机械故障而影响机械设备的正常运转,于是在非工作时间提前对机械进行健康诊断就显得十分必要。
2、随着技术的进步,越来越多的深度学习方法应用在了机械故障诊断的领域。但是其中普遍存在的问题是:大多数深度学习故障诊断的方法是基于训练集平衡的情况下对数据进行处理的,即各种类型的故障数据量是均衡的,且采集到的多次实验数据需要在统计上满足独立同分布的假设;而在训练集不平衡的情况下,诊断的结果会存在较大的误差。同时,由于实验时间和经济成本的约束,所采集的数据往往受限于某种特定工况,如转速、加载扭矩等,无法仅通过多次实验,反映不同工况和故障的穷尽组合,导致深度学习中数据的“分布外”现象,表现在,深度学习模型往往选取实验工况表征,而非故障机理表征作为判断故障类型的依据。在实际工业生产中,单一故障类型相对较易判断;复合故障类型由于是各种故障类型的并发和耦合,增加识别故障类型的难度,进而导致有确定故障类型的故障样本较少,样本分布的不均匀性和数据“分布外”现象,严重限制机械复合故障诊断的稳定性和准确性,因此亟待解决。
技术实现思路
1、为了避免和克服现有技术中存在的技术问题,本发明提供了一种基于故障字典的反事实置信数据生成方法。本发明通过生成的置信的反事实样本,能够解决了原始数据不平衡问题,有效提高了故障诊断的准确率。
2、为实现上述目的,本发明提供如下技术方案:
3、一种基于故障字典的反事实置信数据生成方法,包括以下步骤:
4、s1、采集故障机械的原始故障样本x;
5、s2、使用cnn和vae对原始故障样本进行处理,生成故障语义f和工况属性s;
6、s3、将故障语义f和工况属性s同时输入到生成器中并生成反事实样本
7、s4、将反事实样本输入到鉴别器中,不断训练模型,直到鉴别器无法分辨原始故障样本与反事实样本的区别;
8、s5、将反事实置信的样本输入到原始故障样本中,以扩大原始故障样本的容量。
9、作为本发明进一步的方案:当且仅当工况属性s与故障语义f是群解耦时,生成的反事实样本是反事实置信,在鉴别器进行群解耦时使用总体损失函数ltot对目标进行约束,总体损失函数ltot如下:
10、
11、其中,ls是工况属性损失函数;lf是故障语义损失函数;ld是第三损失函数;v和ρ为权衡参数;θ和为cnn和vae的训练模型;ω为解码器中的训练模型。
12、作为本发明再进一步的方案:工况属性损失函数ls,其表达式为:
13、
14、其中,β是一个权重因子,m表示原始故障样本x的数量,dkl表示先验随机噪声p(z)和由原始故障样本编码得到的后验工况属性之间kl散度;pθ(x(i)|s,f)表示样本数据的概率,表示工况属性的后验分布的概率,且pθ(x(i)|s,f)和使用深度高斯族实现。
15、作为本发明再进一步的方案:故障语义损失函数lf,其表达式为:
16、
17、其中dist表示欧式距离,exp表示以e为底的指数函数;x'表示工况属性s和其他故障类型故障语义f'结合生成的反事实样本。
18、作为本发明再进一步的方案:第三损失函数ld,其表达式为:
19、
20、其中||*||1表示l1范数,l1范数是指向量中各个元素绝对值之和,也称为“稀疏规则算子”,这里使用重构损失进行约束;表示数学期望,dec(·)表示关于语义嵌入解码器的函数。
21、作为本发明再进一步的方案:从数据空间中取值v=(s,f),使用ε表示故障语义f,表示为工况属性s,因此,和分别表示故障语义f和工况属性s的空间,使用表示从数据空间到特征空间的内生映射;其中g对应于pθ(x|s,f)的采样,且是具有连续逆函数g-1的连续单射函数;
22、当且仅当反事实样本相对于子集ε本质上群解耦时,反事实样本是置信的;反事实样本可以分解为:
23、
24、其中表示函数组成,t'表示反事实生成函数,g-1为g的连续逆函数;
25、保持工况属性s不变,将故障语义f值变换为f,则对于任何可以地分解为:
26、
27、作为本发明再进一步的方案:所述故障语义f为原始故障样本的振动特征,即振动频率和振动幅值,
28、f=(a1,a2,…,ak,…,ar)
29、其中,ai为f中的语义元素,且1≤i≤r;
30、多个故障语义为f构成故障语义集合w:
31、w={f1,f2,…,fi,…,fn}
32、其中n为故障样本的数量;
33、选择原始故障样本的r个样本构成故障振动信号集g:
34、g=(v1,v2,…,vk,…,vr)
35、其中r的选择范围要远大于振动信号的一个周期,其中vk表示第k个数据点;
36、定义故障振动信号集g的阈值为λ,如果故障振动信号集g的维度值vk大于λ,那么ak的值设为1,否则αk设为的值设为0,计算如下:
37、
38、其中,λ计算如下:
39、
40、其中α是经验决定的超参数,α选择需要保留故障振动信号的特征。
41、作为本发明再进一步的方案:所述工况属性s包括原始故障样本中的转速、负载、采样频率、采样环境、采样型号;
42、工况属性需要通过cnn和vae进行提取:由原始故障样本经过小波变换得到二维的时频矩阵,输入cnn网络进行特征提取;之后使用vae,通过其编码器编码和重构来学习输入数据的分布特征使用编码得到的潜在向量y作为原始故障样本的后验分布:
43、
44、
45、其中,u是概率密度函数,σ2表示分布的方差,μ表示分布的期望,eps表示一个与原始故障样本期望μ具有相同维度满足标准正态分布的矩阵。
46、与现有技术相比,本发明的有益效果是:
47、1、本发明利用从原始数据提取的工况属性s,替换掉“事实”原始样本故障语义,结合“反事实”故障语义f能够生成较高质量的反事实样本平衡数据集,解决了原始数据不平衡问题,有效提高了故障诊断的准确率。
48、2、本发明将cnn、vae、gan神经网络有机结合在了一起,利用了神经网络的强大性能,自动提取特征,高效率的对数据进行分析和处理,有效改进了传统故障诊断领域的专业门槛高和效率底下的问题。
49、3、本发明设计了一种反事实生成伪样本的方法,该方法不同于传统方法仅使用随机噪声生成伪样本,通过语义嵌入解码器和反馈模块学习原始信号的信息,在生成伪样本时提供辅助信息,能够生成更接近原始数据分布且具有多样性的伪样本。
- 还没有人留言评论。精彩留言会获得点赞!