一种低资源下融合多维特征的联合解码三元组抽取方法与流程
本发明涉及自然语言处理中的实体和关系联合抽取领域,尤其涉及一种低资源下基于主动学习融合多维特征的联合解码三元组抽取方法。
背景技术:
1、三元组抽取也做实体关系联合抽取,通过对文本信息建模,自动识别实体、实体类型和实体间特定关系类型,构建<头实体,关系,尾实体>关系三元组,是构建知识图谱、智能知识问答、语义搜索等下游任务的基础,现有的三元组抽取方式存在以下几点亟需解决的问题:
2、语料匮乏问题。语料匮乏是三元组抽取工作中,业内面临的普遍问题,三元组抽取标注语料,不仅需要标注实体类型,还需要标注实体之间的关系,以及关系的类型,较实体识别任务或关系分类任务,标注难度呈指数上升,需要投入极大的人力成本,更为棘手的是,当下游应用进行修改后,上游的标注要求会动态调整,此时就需要重新标注,因此三元组抽取语料构建过程中会面临标注难度大、人力成本高、标注效率低等问题。
3、误差累积问题。三元组抽取方法分为两大类,管道模型和联合模型。管道模型是指先抽取句子中的实体,然后再对实体进行关系分类,最终得到三元组。管道模型由于把实体关系抽取分为两个顺序子任务,实体抽取和关系分类,将实体识别和关系抽取当作两个独立的任务,两个任务的解决过程中没有考虑到两个子任务之间的相关性,从而导致关系抽取任务的结果严重依赖于实体抽取的结果,导致误差累积的问题。联合模型又分为参数共享和联合解码方法,共享参数模型计算过程中仍将实体抽取损失和关系抽取损失相加,没有实现真正的联合抽取。联合解码方法加强了实体模型和关系模型的交互,真正实现了实体识别和关系抽取的信息共享。
4、主动学习策略选择问题。基于不确定抽样的策略是适用于序列学习的一种策略,业界实验表明,可有效缓解序列学习任务中语料不足的问题,但不同的主动学习策略适用于计算不同特征的文本,策略的种类选择很大程度上,影响了主动学习效果的好坏。
5、主动学习是当前解决序列学习中语料不足问题的较为成熟的办法,关于三元组抽取误差累积问题也已有相关的联合解码模型解决,但如何将主动学习和联合解码模型进行有效结合是业内一直没有解决的问题。
技术实现思路
1、针对上述现有技术中存在的问题,本发明的目的是:将三种主动学习策略、底层自然语言处理特征与联合解码模型tplinker相结合,提供一种低资源下基于主动学习融合多维特征的联合解码三元组抽取方法。
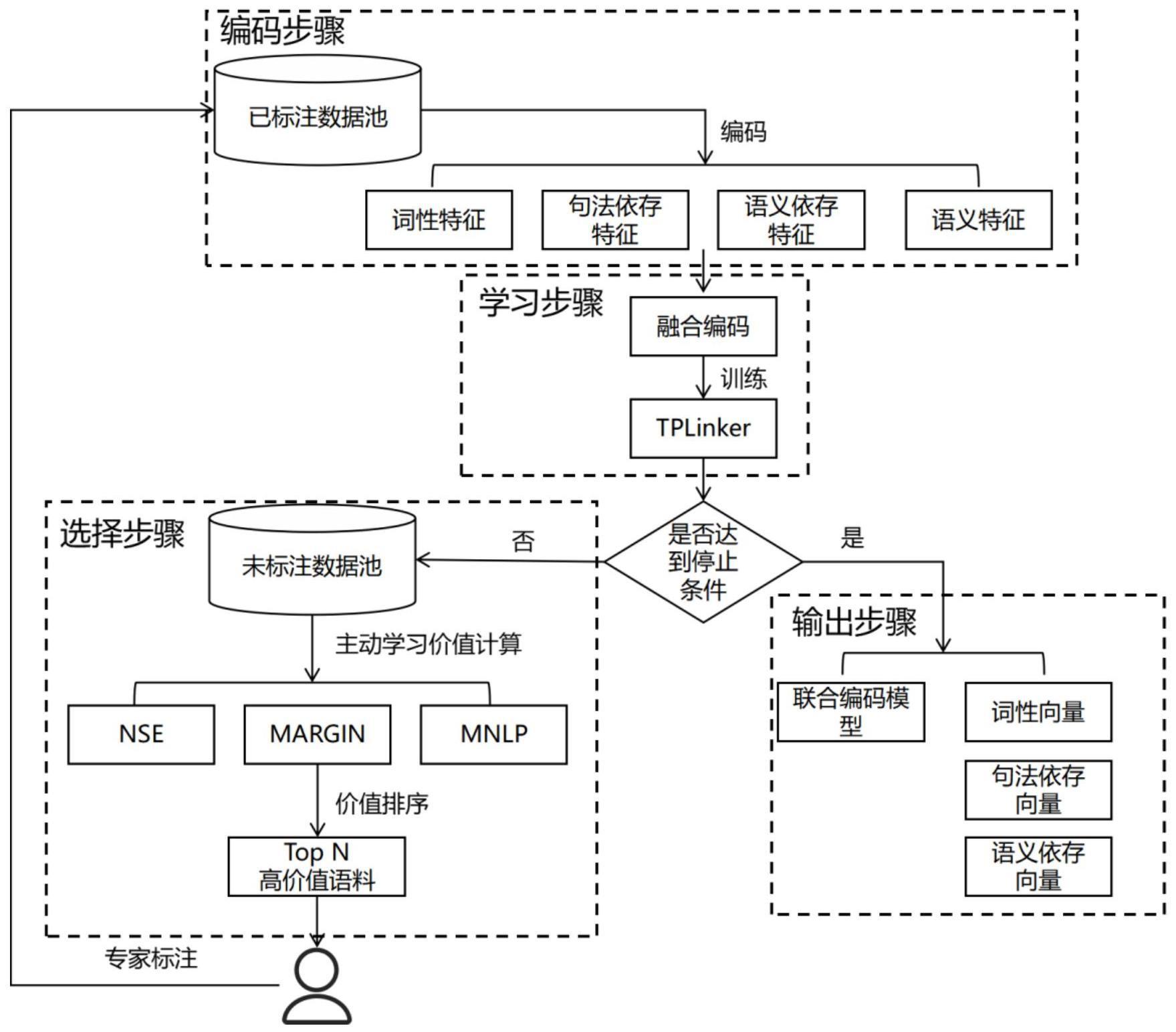
2、为了实现上述目的,本发明采用的技术方案为:一种低资源下融合多维特征的联合解码三元组抽取方法,将训练数据进行分词,获得底层自然语言处理特征词性、句法依存和语义依存,将底层自然语言处理特征与roberta字级编码结合,输入联合解码模型tplinker,基于主动学习主动学习的不确定性采样策略,计算关系三元组的标注价值,将标注价值高的交由专家标注并输入模型进行训练,重复三元组价值计算、专家标注、模型训练过程,直到达到多对多三元组抽取精度目标。具体包括以下步骤:
3、步骤1:将训练数据分别输入roberta和hanlp中,得到字级的语义特征和词级底层自然语言处理特征,包括词性特征、句法依存特征和语义依存特征;
4、步骤2:将词级底层自然语言处理特征拆分并与字级语义特征融合,输入tplinker模型进行训练;
5、步骤3:tplinker模型训练完成后,判断f1值、损失值或未标注数据数量是否达到停止条件,若是,则进行步骤5,否则进入步骤4;
6、步骤4:基于三种不确定抽样的主动学习策略边际抽样、n-best序列熵和最大规范化对数概率,计算句子的标注价值,将排名前n个句子交由专家标注并注入已标注池;
7、步骤5:输出训练完成的联合编码模型,词性向量字典、句法依存向量字典和语义依存向量字典构成三元组抽取的预训练模型,对新输入的句子进行三元组抽取。
8、所述步骤1具体包括:
9、步骤11:取已标注数据池中所有已标注数据;
10、步骤12:通过预训练模型roberta获得包含语义特征的编码;
11、步骤13:将句子输入语法工具hanlp,分词后得到底层自然语言处理特征:词性特征、句法依存特征和语义依存特征;
12、步骤14:为词性特征、句法依存特征和语义依存特征分别构建三张向量字典,宽度分别为词性特征数量、句法依存特征数量的两倍加一和语义依存特征数量的两倍加一;长度分别为roberta字级编码长度,字典初始化采用pytorch框架默认的正态分布方式冷启动。
13、所述步骤2具体包括:
14、步骤21:将基于分词结果获取的三维底层自然语言处理特征,拆分为字级特征,针对词性特征,将词性特征复制到每个字符中;针对句法和语义依存特征,将依存特征复制到每一个字符的同时,依存关系头尾分配不同的向量;
15、步骤22:将字级的词性特征、句法依存特征、语义依存特征和语义特征融合;对于句子[w1,…wn],如果字wi分配到的词性为名词,句法依存特征为被指向主谓关系,语义依存特征为指向施事关系,则向量编码计算如下:
16、
17、其中,cn为词性名词向量,ssbv_r为被指向主谓关系向量,dagt_l为指向施事关系向量,为roberta编码字wi的向量;
18、步骤23:将编码输入tplinker模型,进行训练;获取实体对(wi,wj)生成的表示hi,j如下所示:
19、hi,j=tanh(wh·[hi;hj]+bh),j≥i
20、其中wh是参数矩阵,b是训练中要学习的偏差向量,hi和hj分别是字wi和wj的向量;
21、对于实体开始-实体结束,头实体开始-尾实体开始,头实体结束-尾实体结束,使用统一的标注架构,对于实体对(wi,wj)的关系预测结果link(wi,wj),计算公式如下:
22、p(yi,j)=softmax(wo·hi,j+bo)
23、
24、其中p(yi,j=l)表示将(wi,wj)的链接识别为l的概率,wo是参数矩阵,bo是偏差向量。
25、所述步骤3中停止条件包括:f1值达到阈值、损失连续三轮不再降低或未标注数据池中不包含任何数据。
26、所述步骤4具体包括:
27、步骤41:将未标注数据池中的数据输入tplinker模型中,最大似然估计法训练的实体对关系分类器,得到句子[w1,…wn]中所有实体对识别为相应类型关系的概率集合{p(y1,1=l1),p(y1,1=l2),…,p(yi,j=ln)},其中n为所有关系种类数量;
28、步骤42:使用三种基于不确定抽样的主动学习策略:边际抽样、n-best序列熵和最大规范化对数概率,计算句子的标注价值;
29、步骤43:使用动态加权法获得序列最终得分;
30、步骤44:将序列最终价值得分进行排序,将排名前n个句子,交由专家进行标注,标注后,注入已标注数据池,重复编码模块、学习模块、判断过程。
31、本发明为解决语料不足问题,一是,主动学习策略提高数据质量,减少标注数据数量,缓解模型对大规模语料的依赖;二是,先验底层自然语言处理特征的融合,增加了编码信息量,一定程度上缓解语料匮乏低资源情况下编码特征不足问题。为解决误差累积问题,引入tplinker联合解码机制,实现实体抽取、关系抽取、主动学习计算三种任务的交互,实现了各任务的信息共享,具体的,由于借鉴了tplinker的标注机制一次解码即可完成实体抽取和关系抽取任务,主动学习策略则使用解码计算结果进行句子价值计算。为解决主动学习策略选择问题,设计主动学习策略动态加权机制,一方面,较传统的使用单一主动学习策略,多种策略组合获得的句子价值得分更为全面平衡,一定程度上规避部分策略由于不适用语料特征,造成的偏差和疏漏。另一方面,可根据语料特性、策略特征,或通过扫参的方式灵活调整策略评分权重,增加方案的灵活性、普适性。
32、与现有技术相比,本发明的主要优点在于:
33、(1)本发明在低资源条件下,将底层的自然语言处理先验知识:词性、语义依存、句法依存,与预训练模型输出的字级编码进行融合,丰富了编码的语法特征、句法结构、依存关系等信息,从而提升关系预测准确率,一定程度上弥补了三元组标注困难导致的语料匮乏问题;
34、(2)将参数共享模型与基于池的主动学习场景结合,通过主动学习筛选有价值的标注数据交由专家标注,一方面,高价值标注数据可以提升模型训练效果,人工仅需标注部分数据而不是全部,降低人工标注成本,一定程度上缓解语料匮乏问题,另一方面,实体抽取、关系抽取和主动学习策略计算三种任务实现了信息共享和端到端的三元组抽取,解决了管道式模型带来的暴露偏差问题;
35、(3)设计主动学习策略动态加权机制,一方面,较传统的使用单一主动学习策略,多种策略组合获得的句子价值得分更为全面平衡,一定程度上规避部分策略由于不适用语料特征,造成的偏差和疏漏。另一方面,可根据语料特性、策略特征,或通过扫参的方式灵活调整策略评分权重,增加方案的灵活性、普适性。
- 还没有人留言评论。精彩留言会获得点赞!