一种临床术语标准化方法及装置、存储介质
本技术涉及计算机,主要涉及一种临床术语标准化方法及装置、存储介质。
背景技术:
1、电子病历作为医疗诊断的载体,记录了病人的重要信息。由于不同医生之间书写风格的差异和临床术语表达方式的多样,导致对于同一个病人,不同医生给出的电子病历的表述也有所差别。这种医学实体表达不统一的情况阻碍了研究人员对电子病历的统计和分析,也对医疗人员检索和研究相关病例产生不便。临床术语标准化是解决医学实体表达统一的方法,即对医生书写的术语给出标准术语集内对应的标准词。目前部分医院雇佣工作人员对医生给出的临床术语做标准化处理,但是临床术语标准化任务需要专业的医学知识和大量的人力成本,得到的标准化结果也不够准确。因此,临床术语标准词的自动化生成方法对电子病历的解读和利用具有重要意义。
2、2016年,宁温馨和于明在基于汉字和词语构成词向量的基础上,利用分布式语义实现中文临床术语标准化。2019年,赵逸凡等使用siamese网络架构和lstm网络搭建模型,实现了基于深度学习的电子病历实体标准化算法。2020年,黄嘉俊在基于领域知识库结合分词、实体识别和词向量表示技术的基础上,使用组合语义相似度技术对疾病术语进行标准化。张虹科等构建了一个融合条目词嵌入和注意力机制的模型,通过融合条目词嵌入丰富词语的表示,结合注意力提取关键信息,最后用全连接神经网络分类器输出结果。闫璟辉等先用transformer模型生成伪标准词,再利用lcs算法获得候选标准词,最后使用bert进行语义相似度排序。2021年,孙曰君等使用bert实现了临床术语标准化,该方法通过计算jaccard系数从标准术语集中挑选出候选词,然后用bert对术语原词和候选词进行匹配得到标准化的结果。崇伟峰等通过ner提取部位和术式使用lcs算法获得候选标准词,在基于bert的基础上实现了术语标准化模型。
3、目前对临床术语标准化的主流做法是将临床术语标准化任务分解成标准词数量预测、候选标准词匹配和候选标准词打分排序三个子任务。在术语原词形式简单的情形,研究者会使用文本相似度算法来匹配候选词,然后用文本蕴含的方法对其进行排序,选择出标准词。然而,当术语原词结构复杂时,这些方法便难以适用。总体来说,单纯地使用文本相似度算法难以有效地匹配候选标准词,同时文本蕴含技术又很难准确地对候选标准词进行排序。
技术实现思路
1、针对现有技术中的临床术语标准化处理任务中单纯地使用文本相似度算法难以有效地匹配候选标准词,同时文本蕴含技术又很难准确地对候选标准词进行排序的技术问题,本技术提出了一种临床术语标准化方法及装置、存储介质。
2、根据本技术的第一方面,提出了一种临床术语标准化方法,包括:
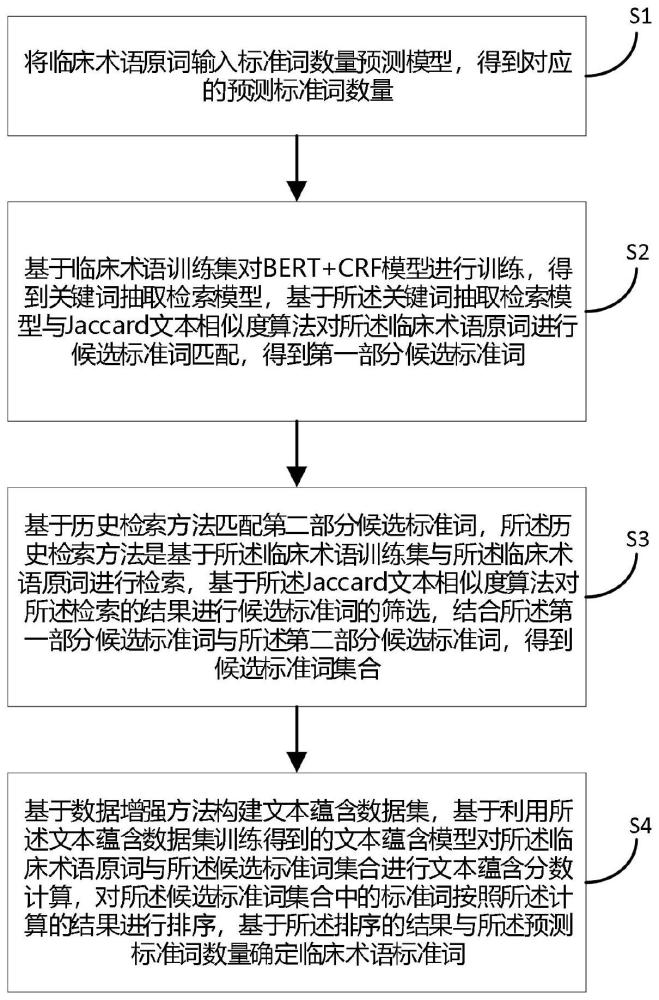
3、s1:将临床术语原词输入标准词数量预测模型,得到对应的预测标准词数量;
4、s2:基于临床术语训练集对bert-crf模型进行训练,得到关键词抽取检索模型,基于所述关键词抽取检索模型与jaccard文本相似度算法对所述临床术语原词进行候选标准词匹配,得到第一部分候选标准词;
5、s3:基于历史检索方法匹配第二部分候选标准词,所述历史检索方法是基于所述临床术语训练集与所述临床术语原词进行检索,基于所述jaccard文本相似度算法对所述检索的结果进行候选标准词的筛选,结合所述第一部分候选标准词与所述第二部分候选标准词,得到候选标准词集合;
6、s4:基于数据增强方法构建文本蕴含数据集,基于利用所述文本蕴含数据集训练得到的文本蕴含模型对所述临床术语原词与所述候选标准词集合进行文本蕴含分数计算,对所述候选标准词集合中的标准词按照所述计算的结果进行排序,基于所述排序的结果与所述预测标准词数量确定临床术语标准词。
7、在具体的实施例中,步骤s1所述的将临床术语原词输入标准词数量预测模型之前,还包括:
8、基于预设的标准词候选集对预设的临床术语数据集进行预处理,得到预处理后的临床术语数据集,所述预处理包括数据清洗和文本替换,所述临床术语数据集中包括临床术语训练集、临床术语验证集与临床术语测试集,所述临床术语数据集中的数据包括临床术语原词与临床术语标准词的临床术语集合,所述临床术语集合中临床术语原词对应至少一个临床术语标准词。
9、在具体的实施例中,步骤s2所述的基于临床术语训练集对bert-crf模型进行训练,包括以下步骤:
10、s21:将所述临床术语训练集中的临床术语原词里的文字分别在与所述临床术语原词对应的临床术语标准词中进行检索,将无法检索到所述临床术语标准词的文字标注为0;
11、s22:将能够检索所述临床术语标准词的文字按照首字、中间字和末字分别标注为1、2、3;
12、s23:在所述临床术语原词的首位与末位插入0,得到训练数据;
13、s24:基于所述训练数据对所述bert-crf模型进行训练,得到关键词抽取检索模型。
14、在具体的实施例中,步骤s2所述的基于所述关键词抽取检索模型与jaccard文本相似度算法对所述临床术语原词进行候选标准词匹配,包括以下步骤:
15、s25:基于所述关键词抽取检索模型对所述临床术语原词进行数据标注,得到关键词;
16、s26:基于所述关键词在所述标准词候选集中进行检索,得到与所述关键词对应的候选标准词,所述候选标准词的数量为一个或多个;
17、s27:响应于所述关键词存在且所述关键词未检索到所述候选标准词,重新执行步骤s25与s26以获得另外的关键词进行检索;
18、s28:基于所述jaccard文本相似度算法对所述临床术语原词与所述候选标准词进行文本相似度分数的计算,得到文本相似度分数;
19、s29:基于所述文本相似度分数对候选标准词进行排序,对所述排序后的候选标准词进行筛选,得到第一部分候选标准词。
20、在具体的实施例中,步骤s3所述的基于历史检索方法匹配第二部分候选标准词,所述历史检索方法是基于所述临床术语训练集与所述临床术语原词进行检索,基于所述jaccard文本相似度算法对所述检索的结果进行候选标准词的筛选,结合所述第一部分候选标准词与所述第二部分候选标准词,得到候选标准词集合,包括以下步骤:
21、s31:将所述临床术语训练集中的临床术语集合加入查询索引;
22、s32:基于所述jaccard文本相似度算法计算所述临床术语原词与所述查询索引中临床术语集合中包括的所有临床术语原词间的文本相似度分数;
23、s33:基于所述文本相似度分数对所述查询索引中的临床术语集合进行排序,基于所述排序的结果进行候选标准词的筛选,得到第二部分候选标准词;
24、s34:将所述第一部分候选标准词与所述第二部分候选标准词进行合并,得到候选标准词集合。
25、在具体的实施例中,步骤s4所述的基于数据增强方法构建文本蕴含数据集,包括以下步骤:
26、s41:基于所述临床术语训练集中的临床术语集合进行相似标准词的替换,得到原临床术语原词对应新临床术语标准词的临床术语集合;
27、s42:基于所述s41得到的集合进行eda数据增强,得到新临床术语原词对应新临床术语标准词的临床术语集合;
28、s43:将所述s41得到的集合与所述s42得到的集合进行合并,得到新临床术语集合;
29、s44:将所述新临床术语集合与所述临床术语训练集中的临床术语集合结合,得到所述文本蕴含数据集。
30、在具体的实施例中,步骤s4所述的基于利用所述文本蕴含数据集训练得到的文本蕴含模型对所述临床术语原词与所述候选标准词集合进行文本蕴含分数计算,对所述候选标准词集合中的临床术语标准词按照所述计算的结果进行排序,基于所述排序的结果与所述预测标准词数量确定临床术语标准词,包括以下步骤:
31、s45:基于所述文本蕴含数据集建立正负例训练集,所述正负例训练集用于训练所述文本蕴含模型;
32、s46:基于所述文本蕴含模型对所述临床术语原词与所述候选标准词集合进行文本蕴含分数计算,得到文本蕴含分数,基于所述文本蕴含分数对所述候选标准词集合进行排序,得到排序后的候选标准词集合;
33、s47:基于所述排序后的候选标准词集合根据所述预测标准词数量进行候选标准词的筛选,得到临床术语标准词。
34、在具体的实施例中,步骤s45所述的基于所述文本蕴含数据集建立正负例训练集,所述正负例训练集用于训练所述文本蕴含模型,具体包括:
35、基于所述文本蕴含数据集中满足一个临床术语原词对应多个临床术语标准词的临床术语集合进行临床术语标准词的分割,得到正例训练数据;
36、基于所述jaccard文本相似度算法对所述文本蕴含数据集中所有临床术语原词对应的临床术语标准词与所述标准词候选集中的所有标准词进行文本相似度分数计算,得到文本相似度分数,基于所述文本相似度分数筛选未与临床术语原词对应的临床术语标准词,得到负例训练数据,结合正例训练数据与负例训练数据构建正负例训练集。
37、根据本技术的第二方面,提出了一种临床术语标准化装置,包括:
38、标准词数量预测模块901,用于对临床术语原词进行数量预测,得到预测标准词数量;
39、候选标准词匹配模块902,用于对临床术语原词进行候选标准词的匹配,得到临床术语候选标准词集合;
40、文本蕴含模块903,用于对所述临床术语候选标准词集合进行候选标准词的文本蕴含分数计算与排序,得到与所述临床术语原词对应的临床术语标准词。
41、根据本技术的第三方面,提出了一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1-8任意一项所述的临床术语标准化方法。
42、本技术公开了一种临床术语标准化方法及装置、存储介质,该方法通过bert-crf构建关键词抽取模型,能够有效的匹配临床术语原词对应候选标准词,并提出一种数据增强方法解决了临床术语标准化中文本蕴含技术很难准确地对候选标准词进行排序的技术问题,提高了临床术语标准化任务的准确率。
- 还没有人留言评论。精彩留言会获得点赞!