一种深度神经网络硬件加速器装置
本发明涉及深度神经网络硬件加速器技术,具体涉及一种可重构的神经网络硬件加速器的硬件装置。
背景技术:
1、随着深度神经网络(dnn)模型和应用的快速增长,很多新型深度神经网络模型不仅拓宽了应用范围,而且针对不同技术领域均可实现更好的结果。同时,随着dnn算法和网络模型架构的突破,其算法类型和数据传递方式变得更加多样化。例如,mobilenet(sandler,mark,et al."mobilenetv2:inverted residuals and linear bottlenecks."proceedings of the ieee conference on computer vision and patternrecognition.2018.)等轻量级dnn网络模型能够在低功耗边缘设备上进行网络处理,这些低功耗边缘设备通过使用深度可分离卷积来减少计算量。递归神经网络(rnn)模型将网络应用扩展到语言领域,包括语音和文本处理任务。transformer网络模型使用了softmax和层归一化(layer norm)等新算法,并在多个场景下优于rnn和传统cnn(卷积神经网络)模型。
2、为了高效处理dnn模型,研究人员设计了各类不同的dnn硬件加速器,其中面向的设备包括asic、fpga、cgra和其他嵌入式设备。dnn加速器的典型硬件架构包含一个大型处理元件(pe)阵列,一些用于激活和后处理的额外逻辑,以及用于更好数据局部性的大型片上缓冲区。与传统的cpu和gpu架构相比,dnn加速器可以实现数量级的性能和能效提升。pe阵列具有用于dnn相关算法(例如矩阵乘法、卷积、激活函数等)的专用数据流,加速器硬件可以使用不同的空间数据流来实现高效的数据重用,包括脉动阵列(tpu(norman p jouppiet al.in-datacenter performance analysis of a tensor processing unit.in isca,2017)等),多播网络(shidiannao(z.du,r.fasthuber,t.chen,p.ienne,l.li,t.luo,x.feng,y.chen,and o.temam,“shidiannao:shifting vision processing closer tothe sensor,”in proceedings of the 42nd annual international symposium oncomputer architecture,portland,or,usa,june13-17,2015)等),和基于树的结构(maeri(h.kwon,a.samajdar,and t.krishna,“maeri:enabling flexible dataflow mappingover dnn accelerators via reconfigurable interconnects,”in proceedings of thetwenty-third international conference on architectural support forprogramming languages and operating systems,asplos 2018)等)。
3、从dnn硬件加速器的角度来看,一个主要的挑战是如何实现针对各种dnn模型的高性能算法,并保证编程的易用性。最基本的dnn硬件加速器使用固定的数据流和功能,并且只能应用于标准cnn模型,难以处理各种复杂多变的网络模型。近年来,研究者提出了许多可重构的dnn加速器硬件,利用重构实现对不同网络模型的支持。此类加速器根据重构的方法可分为三种类型:可重构数据流加速器(rda),可重构功能加速器(rfa)以及异构多数据流加速器(hda)。可重构数据流加速器使用可配置开关为不同的计算模式配置不同的数据流,例如flexflow(lu,wenyan,et al."flexflow:a flexible dataflow acceleratorarchitecture for convolutional neural networks."2017ieee internationalsymposium on high performance computer architecture(hpca).ieee,2017.)和maeri。可重构功能加速器使用具有可变功能的多个计算单元,通过统一的全局控制器进行调度以处理dnn模型。配置是通过专用指令集架构(isa)实现的,例如cambricon、vta、brainwave。异构多数据流加速器在单个芯片上集成了多个具有不同数据流或功能的加速器(子核心)。hda(kwon,hyoukjun,et al."heterogeneous dataflow accelerators for multi-dnnworkloads."2021ieee international symposium on high-performance computerarchitecture(hpca).ieee,2021.)和dnpu(shin,dongjoo,et al."dnpu:an energy-efficient deep-learning processor with heterogeneous multi-corearchitecture."ieee micro 38.5(2018):85-93.)使用了这种方法。不同的dnn层使用不同的数据流,并且可以将它们调度到具有更好性能的特定子核心。
4、然而,现有的可重构dnn加速器只能实现上述三种重构方案中的一种。单一的重构方式难以应对多种不同的dnn处理需求。例如,rda难以处理各种不同类型的卷积,rfa的性能比传统固定数据流加速器有明显下滑。因此,目前的深度学习应用急需一种能够同时实现多种重构方法的dnn硬件加速器,能够支持同时处理各种深度神经网络模型计算。
技术实现思路
1、为了克服上述现有技术的不足,本发明提出一种深度神经网络加速器硬件装置,可同时实现上述三种重构方式(可重构数据流加速器(rda),可重构功能加速器(rfa)以及异构多数据流加速器(hda))的神经网络加速器,以克服现有可重构的dnn加速器硬件所实现的重构方式的单一性,是一种能够同时实现多种重构方式的dnn硬件加速器,能够同时处理各种深度神经网络模型计算。
2、为方便起见,本发明采用以下术语定义:
3、rda(reconfigurable dataflow accelerator)可重构数据流加速器
4、rfa(reconfigurable functionality accelerator)可重构功能加速器
5、hda(heterogeneous multi-dataflow accelerator)异构多数据流加速器
6、alu(arithmetic logic unit)算术逻辑单元
7、valu向量计算单元
8、pe(proecssing element)计算单元
9、io(input-output)输入输出
10、ws(weight stationary)权重固定数据流
11、os(output stationary)输出固定数据流
12、dma(direct memory access)直接内存访问
13、rtl(register transistor level)寄存器转换级电路
14、axi(advanced extensible interface)axi总线协议
15、mac(multiply accumulation)乘加运算
16、isa(instruction set architecture)指令集体系结构
17、ddr双倍速率同步动态随机存储器
18、本发明提供的技术方案是:
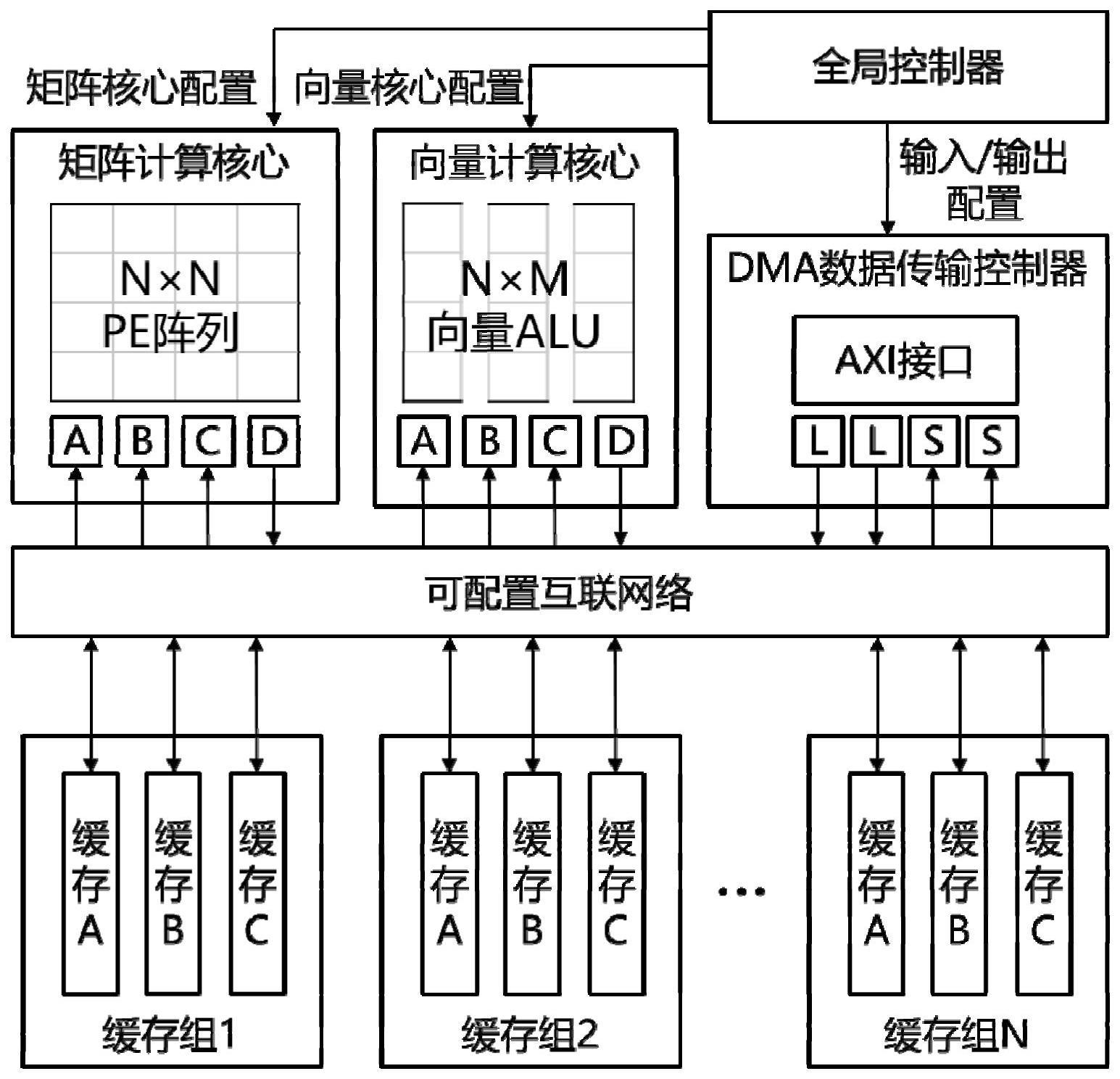
19、一种深度神经网络加速器硬件装置,包括:矩阵计算核心模块、向量计算核心模块、片上缓存模块、直接内存访问(dma)数据传输控制器模块和可配置互联网络模块;其中,矩阵计算核心模块和向量计算核心模块支持不同的可重构选项;可重构选项包括权重固定数据流和输出固定数据流;重构方式包括可重构数据流加速器(rda)、可重构功能加速器(rfa)以及异构多数据流加速器(hda);可同时实现数据流、功能和多模块的硬件重构特性,可处理多种类型的神经网络计算。
20、矩阵计算核心模块采用标准脉动阵列架构构建,硬件结构为n×n的脉动阵列,包含n^2个计算单元(pe);数据流在权重固定数据流和输出固定数据流之间变化,支持不同矩阵格式;矩阵计算核心模块可用于直接运行标准矩阵乘法、转置矩阵乘法,及基于标准矩阵乘法与转置矩阵乘法的卷积运算;
21、向量计算核心模块由m个向量计算单元(valu)串联而成,每个valu由n个并行的算术逻辑单元alu组成;每个alu均有一个输出寄存器;alu具有可配置的向量运算功能,通过alu互连实现针对多种数据重用模式进行配置;向量计算核心模块包括3个输入端口和1个输出端口;输入端口和输出端口均与缓存相连接;向量计算核心模块用于执行一元运算、二元运算和三元运算;向量计算核心模块支持不同可重配置数据流和多种不同操作数的重构;
22、dma数据传输控制器模块包括访存地址生成器和axi总线协议接口,用于加速器和外部存储的通信,实现同时在片上缓存和片外ddr中交换数据;
23、可重配置的互联网络模块用于控制片上缓存模块与两个计算核心模块之间的数据移动方式,并向其他每个模块发送对应的配置信息;矩阵计算核心模块和向量计算核心模块通过可配置互联网络模块,与多个片上缓存模块进行连接;
24、片上缓存模块包括多个片上缓存组;每个片上缓存组(bufg)包含三个缓存单元;用于保存从加速器外部加载的矩阵数据;每个缓存单元有多个存储区,对应每个计算核心和dma数据传输控制器中的多个数据端口。
25、与现有技术相比,本发明的有益效果:
26、现有的可重构dnn加速器只能实现可重构数据流加速器(rda),可重构功能加速器(rfa)以及异构多数据流加速器(hda)三种重构方案中的一种。而单一的重构方式难以应对多种不同的dnn处理需求。本发明提供的深度神经网络加速器硬件装置包括矩阵计算核心模块、向量计算核心模块、片上缓存模块、直接内存访问(dma)数据传输控制器模块和可配置互联网络模块;通过设计矩阵计算核心模块和向量计算核心模块支持不同的可重构选项,从而能够同时实现多种重构方式,同时处理各种深度神经网络模型计算。本发明通过支持多种重构方案,实现对不同dnn网络的高效处理。
- 还没有人留言评论。精彩留言会获得点赞!