一种基于自注意力机制的序列化神经协同过滤推荐方法
本发明涉及推荐系统,特别是一种基于自注意力机制的序列化神经协同过滤推荐方法。
背景技术:
1、随着互联网规模的飞速发展,互联网上各种场景的数据也越来越多,因此用户在互联网上探索他们想要的东西也变得更加困难,基于这个原因,推荐系统被广泛用于各种场景中。构造推荐系统的一个关键难点是挖掘用户的潜在兴趣,以做出更准确的推荐。为了解决这个问题,研究人员从用户的历史行为序列中挖掘出用户的潜在兴趣,进行序列化推荐。与传统的推荐系统相比,序列化推荐系统能够从用户历史行为记录序列中捕捉到用户的长期依赖和动态偏好。最近几年来,序列化推荐已经成为推荐系统的一个技术热点。传统的序列化推荐模型主要包括序列模式挖掘模型、马尔可夫链模型和隐语义模型。序列模式挖掘模型从用户历史行为序列中挖掘出用户行为模式。这个模型的一个缺点是模型会产生大量的模式,一些不受欢迎的商品不会被推荐。马尔科夫链模型利用马尔科夫链来建立用户与商品之间的互动关系,但这种模型只能捕捉到短期的依赖关系,而忽略了长期的依赖关系。隐语义模型可以学习推荐系统中用户和商品的隐语义来进行推荐。这种模型很容易受到数据稀少的影响,有时不能做出准确的推荐。
2、湖南大学的专利申请“基于cnn和rnn的序列化推荐”(专利号:201811548205.8),本发明提出了一种基于cnn(convolutional neural network,卷积神经网络)和rnn(recurrent neural network,循环神经网络)相结合的序列化推荐算法,该算法利用cnn的局部特征学习能力来捕捉最近历史行为数据中存在的相关关系,同时利用rnn的全局和序列学习能力来学习用户历史行为的长短期偏好,最后通过学习到的特征表达利用多层感知机预测用户未来会产生的行为并提供推荐,实验表明该算法的效果优于单一的基于cnn或rnn的序列化推荐。本发明具有很高的应用价值,可广泛应用于互联网电商、新闻门户和娱乐等多种推荐场景。该方法的缺点是,cnn和rnn网络无法判定序列中不同商品的重要程度,未能分辨出序列中的噪声信息,从而对推荐结果造成一定的影响。
3、上海交通大学的专利申请“基于商品关联关系的序列化推荐方法”(专利号:202111059171.8),其特征在于以下步骤,获取交互数据步骤:从网络端获取用户与商品之间的交互数据;构建共生关系图步骤:令交互数据构建商品的共生关系图,所述共生关系图用关联关系图邻接矩阵进行表示;图卷积网络步骤:令关联关系图邻接矩阵进行图卷积操作,获得商品的关联性特征;推荐模型训练步骤:令商品的关联性特征输入推荐模型进行训练;序列化推荐步骤:令推荐模型输出商品关联关系的序列化推荐。该方法的缺点是,推荐中单纯的使用用户的序列化数据,未能考虑到用户的短期偏好,没有将全局的协同信息纳入到推荐过程中来。
4、西北工业大学的专利申请“一种基于长短期兴趣的序列化推荐方法”(专利号:202010014762.2),其特征在于:所述方法包括以下步骤:s1:获取数据,对数据进行预处理;s2:对所有的评论文本、提问文本进行处理,对每个商品的相关文本中选择得分最高的多个词作为提取特征,通过所有特征的集合来对商品进行描述,构建商品的特征表示矩阵;s3:构建用户购买序列的向量表示:根据商品的特征表示矩阵以及用户的历史购买序列得到每个用户购买序列的向量表示;s4:分别对用户的长期兴趣偏好和短期兴趣偏好进行表示;s5:将用户的长期兴趣偏好和短期兴趣偏好通过注意力机制获得用户聚合偏好;s6:通过确定聚合偏好和目标商品之间的关系,获得用户提问之后与商品交互的概率;s7:使用交叉熵损失函数来学习模型的参数,得到提问时刻后每个商品被购买的概率。该方法的缺点是,单纯利用序列信息来进行推荐会忽视掉全局的协同交互信息,从而影响推荐的准确性。
技术实现思路
1、本发明的目的在于:提出一种基于自注意力机制的序列化神经协同过滤推荐方法,采用自注意力机制,从用户历史行为记录序列中学习用户的潜在偏好,并获得信息增强的待推荐商品特征向量,消除序列中的大部分噪声,并捕捉到用户历史行为记录序列的长期依赖关系。
2、本发明采用的技术方案如下:
3、本发明是一种基于自注意力机制的序列化神经协同过滤推荐方法,包括以下步骤:
4、在推荐场景中收集用户与商品交互记录作为初始数据,之后将与用户有过交互记录的商品id整理成为用户历史行为记录序列;
5、推荐场景中的用户id与商品id进行one-hot嵌入,得到用户特征向量与商品特征向量;
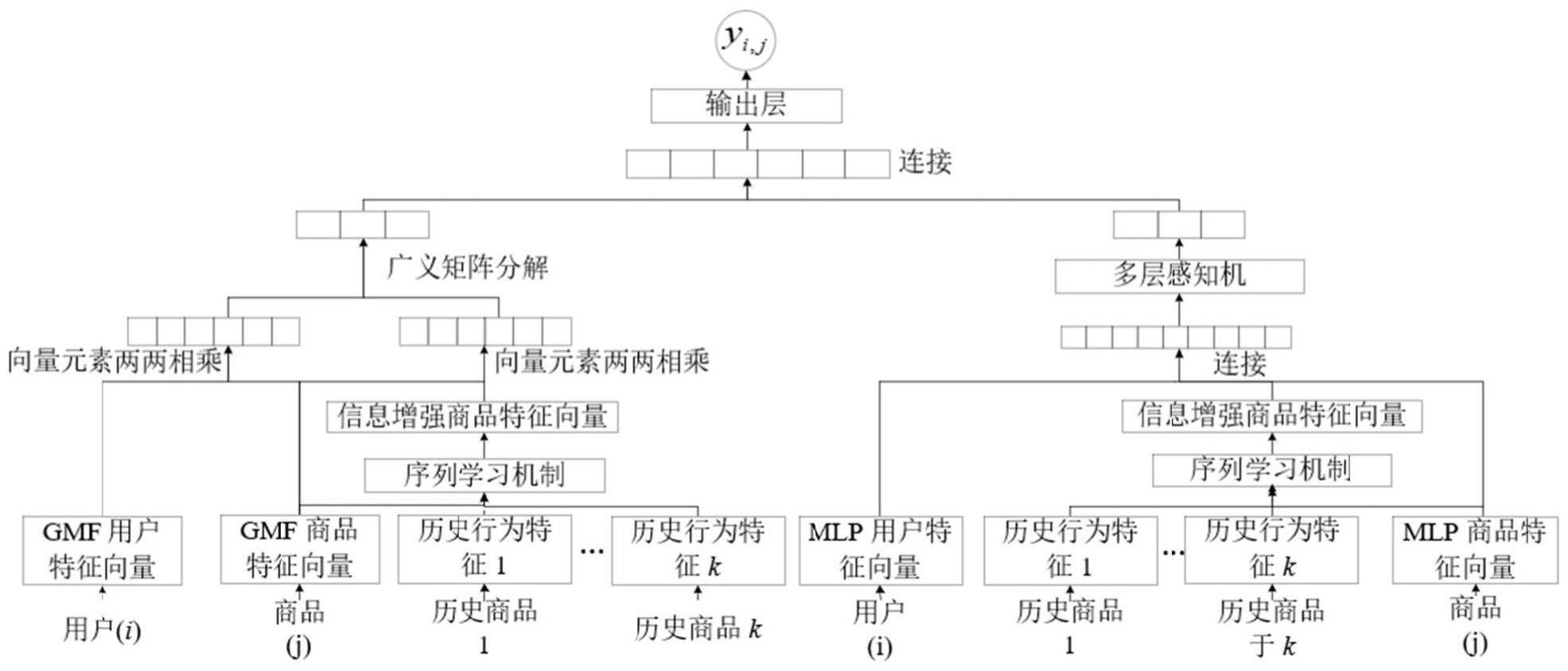
6、将待推荐商品特征向量放在用户历史行为记录序列的末端,并将这样的用户历史行为记录序列数据输入到自注意力机制中去,学习序列信息,得到具有丰富序列信息的待推荐商品特征向量;
7、将具有丰富序列信息的待推荐商品特征向量与原始嵌入得到的用户特征向量与商品特征向量一起输入到神经协同过滤模型的序列化广义矩阵分解部分与序列化多层感知机部分,完成用户对待推荐商品的评分计算,最后进行推荐。
8、进一步的,在推荐场景中有m个用户和n个商品,则u={u1,u2,...,um}表示用户特征向量集,r={r1,r2,...,rn}表示商品特征向量集,s={s1,s2,...,sk}表示用户历史行为记录序列集,用户历史行为记录序列的长度为k;
9、用户i对于商品j序列信息学习具体为:
10、将商品j放在用户历史行为记录序列的末端,得到商品特征向量矩阵e;
11、上述用户历史行为记录序列数据输入自注意力机制学习序列信息,得到具有丰富序列信息的待推荐商品特征向量s。
12、所述历史行为记录序列数据输入自注意力机制学习序列信息,具体的:
13、首先,商品特征向量矩阵e进行三种不同的线性变化,以获得q、k、v,具体公式如下:
14、q=ewq,k=ewk,v=ewv (1)
15、其中,q表示查询特征向量矩阵,k表示关键词特征向量矩阵,v表示值特征向量矩阵,w表示对输入矩阵e进行线性变化的线性变化矩阵;
16、wq是对输入矩阵e进行线性变化得到查询特征向量矩阵q的线性变化矩阵;
17、wk是对输入矩阵e进行线性变化得到关键词特征向量矩阵k的线性变化矩阵;
18、wv是对输入矩阵e进行线性变化得到值特征向量矩阵v的线性变化矩阵;
19、然后,采用缩放点积注意力来进行注意力计算,具体计算公式如下:
20、
21、其中,q表示查询特征向量矩阵,k表示关键词特征向量矩阵,v表示值特征向量矩阵,dk代表查询向量、关键词向量和值向量的维度的大小;
22、softmax是归一化指数函数,来获得注意力的权重。
23、进一步的,所述自注意力机制采用多头自注意力机制,从多个角度挖掘商品特征向量的潜在信息,多头自注意力机制将原商品特征向量切分为几个低维的子特征向量进行注意力计算,然后将各个子特征向量连接起来得到多头自注意力机制的输出结果,具体公式如下:
24、multihead(q,k,v) = concat(head1,...,headh)wo (3)
25、headi=attention(qwiq,kwik,vwiv) (4)
26、其中,headi表示第i头的注意力计算结果,
27、h表示多头注意力机制中的头数,
28、wiq,wik,wiv分别表示第i头中的查询特征向量矩阵、关键词特征向量矩阵和值特征向量矩阵对应的线性变化矩阵,
29、wo是对每个头注意力计算结果连接之后进行线性变化的矩阵;
30、将各头注意力机制得到的特征向量矩阵连接在一起,该矩阵的最后的一个特征向量就是具有丰富序列信息的待推荐商品特征向量s。
31、进一步的,所述用户历史行为记录序列的长度为k,对于不同用户历史行为记录序列的长度是不一样的,需要将不同长度的序列进行长度上的统一,具体的:
32、对于长序列,从序列中选择时间序列最近的k个商品来形成用户历史行为记录序列;
33、对于短序列,本发明用数字0来填补缺失的位置,直到序列的长度达到k;
34、在注意力计算中,使用一个额外的填充掩码特征向量矩阵,消除额外添加的数字0对序列信息的影响,对于每个头的注意力计算,使用缩放点积注意力来学习序列信息,具体的注意力分数计算如下:
35、
36、其中,qi,ki,vi分别表示第i头注意力计算中对应的查询特征向量矩阵、关键词特征向量矩阵和值特征向量矩阵;
37、softmax是归一化指数函数,可以将每个维度的结果映射为0到1之间;
38、m表示填充掩码特征向量矩阵,用于解决用户历史行为记录序列的长短不同问题;
39、headi表示每个头学习到的具有丰富序列信息的待推荐商品特征向量矩阵。
40、进一步的,所述神经协同过滤模型包括序列化广义矩阵分解和序列化多层感知机,对于序列化广义矩阵分解部分,具体的:
41、分别对原始的用户特征向量、商品特征向量做元素对应相乘,以及对原始的用户特征向量、具有丰富序列信息的待推荐商品特征向量s做元素对应相乘,具体公式如下:
42、p1=ui⊙rj (6)
43、p2=ui⊙s (7)
44、其中,ui是原始的用户特征向量,rj是原始的商品特征向量,s是具有丰富序列信息的待推荐商品特征向量,p1表示具有短期依赖信息的潜在特征向量,p2表示用户历史行为记录序列中具有长期依赖信息的潜在特征向量,
45、最后,使用线性结合的方法将上述两个向量p1、p2进行合并,公式如下:
46、p=α×p1+(1-α)×p2 (8)
47、其中,p是同时具有短期依赖信息与长期依赖信息的潜在特征向量,α是用来控制p1与p2在计算p时所占比例的超参数。
48、进一步的,对于所述序列化多层感知机部分,具体的:
49、首先,将原始的用户特征向量ui、原始的商品特征向量rj和具有丰富序列信息的待推荐商品特征向量s连接起来;
50、然后,将连接后的特征向量输入序列化多层感知机,具体公式如下:
51、
52、q1=a1(w1tq0+b1) (10)
53、
54、...
55、
56、其中,q0表示用户特征向量ui、商品特征向量rj和具有丰富序列信息的待推荐商品特征向量s连接后的结果;
57、q1,q2,…,qh分别表示序列化多层感知机中各层的潜在特征向量;
58、wht、bh、ah分别表示序列化多层感知机中第h层的激活函数、权重矩阵和偏置向量;
59、最终的qh也就是具有输入向量间复杂非线性关系的潜在特征向量。
60、进一步的,根据神经协同过滤模型的序列化广义矩阵分解与序列化多层感知机,分别得到具有复杂非线性信息的特征向量qh与同时具有长期依赖与短期依赖的特征向量p,将qh和p连接起来,融合用户和商品之间的长短期依赖信息和非线性复杂信息,进行最终的推荐评分预测,其具体公式如下:
61、
62、yi,j=sigmod(htz) (14)
63、其中,z是融合了序列化广义矩阵分解与序列化多层感知机各自生成的特征向量的总特征向量,sigmod函数将预测的分数映射到0到1之间,进行最终推荐评分预测结果的比较。
64、综上所述,由于采用了上述技术方案,本发明的有益效果是:
65、本发明是一种基于自注意力机制的序列化神经协同过滤推荐方法,构建了一套完整的序列推荐框架,其中包括序列信息学习部分和基于神经协同过滤模型进行评分预测的部分,序列信息学习部分利用自注意力机制来学习用户历史行为记录序列,既很好的学习到用户历史偏好信息,同时也避免了历史行为序列信息中噪声的干扰,将利用自注意力机制学习的待推荐商品特征向量和原始的用户特征向量与商品特征向量输入到神经协同过滤模型中,捕获到了推荐场景下的长期依赖信息与短期依赖信息,得到更加准确的推荐结果。
- 还没有人留言评论。精彩留言会获得点赞!