一种基于国网营销采集系统的数据同步链路方法及系统与流程
本发明属于电力系统用户侧,更具体地,涉及一种网上国网营销采集系统的数据同步链路方法及系统。
背景技术:
1、国网营销采集系统为基础系统主要目的是存储用户的用电信息和账单信息,如图1所示,普通低压居民用户每天的用电量、企业用户每天的用电量、企业级高压用户的用电负荷、企业级高压用户的用电负荷趋势、居民及企业用户每个月的用电账单信息、居民及企业用户阶梯电量账单信息、居民及企业用户计量点账单信息、企业级高压用户趋势信息等,通过每个用户或企业的电表信息以及省侧线下营业厅办理的业务数据,对采集的数据通过用电类别进行归类和区分录入省级电网侧营销采集系统,省级电网侧营销采集系统需要将源数据同步至总部进行汇总和计算展示,目前网上国网总部运行方式为北京、上海双轨运行,待所有省环境都切换至北京环境以后,总部上海环境将成为备用环境。
2、总部的新型大数据平台中,使用hive数据库工具和gbase数据库就显得尤为重要。hive服务可以提供海量数据仓库的解决方案以及针对大数据的分析建模,hive处理的数据都存储在hdfs上可以实现存储大批量的数据,采用分布式计算的模式可以大大提高数据的计算能力,gbase数据库也可以作为数据仓库,gbase数据库具有联邦架构,大规模并行计算,海量数据压缩、高效存储结构、智能索引、虚拟集群及镜像、灵活的数据分布、完善的资源管理、在线快速扩展、在线节点替换、高并发、高可用性、高安全性、易维护、高效加载等优点。
3、从当前一般企业情况来看每天涉及的数据量都是上亿级别的,而这种大体量的数据每日都是需要进行数据同步,传输到目标端数据库进行备份存储和相关指标计算。比较常见的传输方式分两种,一种是全量抽取同步,还有一种是将数据按照一定的逻辑进行拆分然后多次进行同步直至同步完成,面对全量抽取同步时如果数据量较小那么效率会比较高,但是面对大体量的数据时候,同步效率就会大打折扣甚至出现无法同步的情况,如果是拆分同步的话,涉及的时间较长会影响整体的业务数据流转。
4、在国网体系中最为重要的就是用户的电量和账单的数据查询,全国用户的用电信息和账单信息每日增量均在十几亿左右,面对这种体量的数据如果采取传统的数据传输方式会影响整体数据的同步效率,同步缺失或者不及时会影响用户查询的状态。
5、在当前环境下数据同步过程中可能会出现数据文件丢失,没有监控看同步状态无法及时定位异常情况,数据链路不连续以及数据同步效率低等问题,解决这些问题已经成了信息化数据传输最为重要的一环。
技术实现思路
1、为解决现有技术中存在的不足,本发明提供了一种基于网上国网营销采集系统的数据同步链路方法及系统,该数据同步链路方法能够有效解决大批量增量数据的同步,并且能够做到实时监控和备份,对运维人员处理异常的情况起到了至关重要的作用。
2、本发明采用如下的技术方案。
3、一种基于网上国网营销采集系统的数据同步链路方法,所述方法包括步骤:
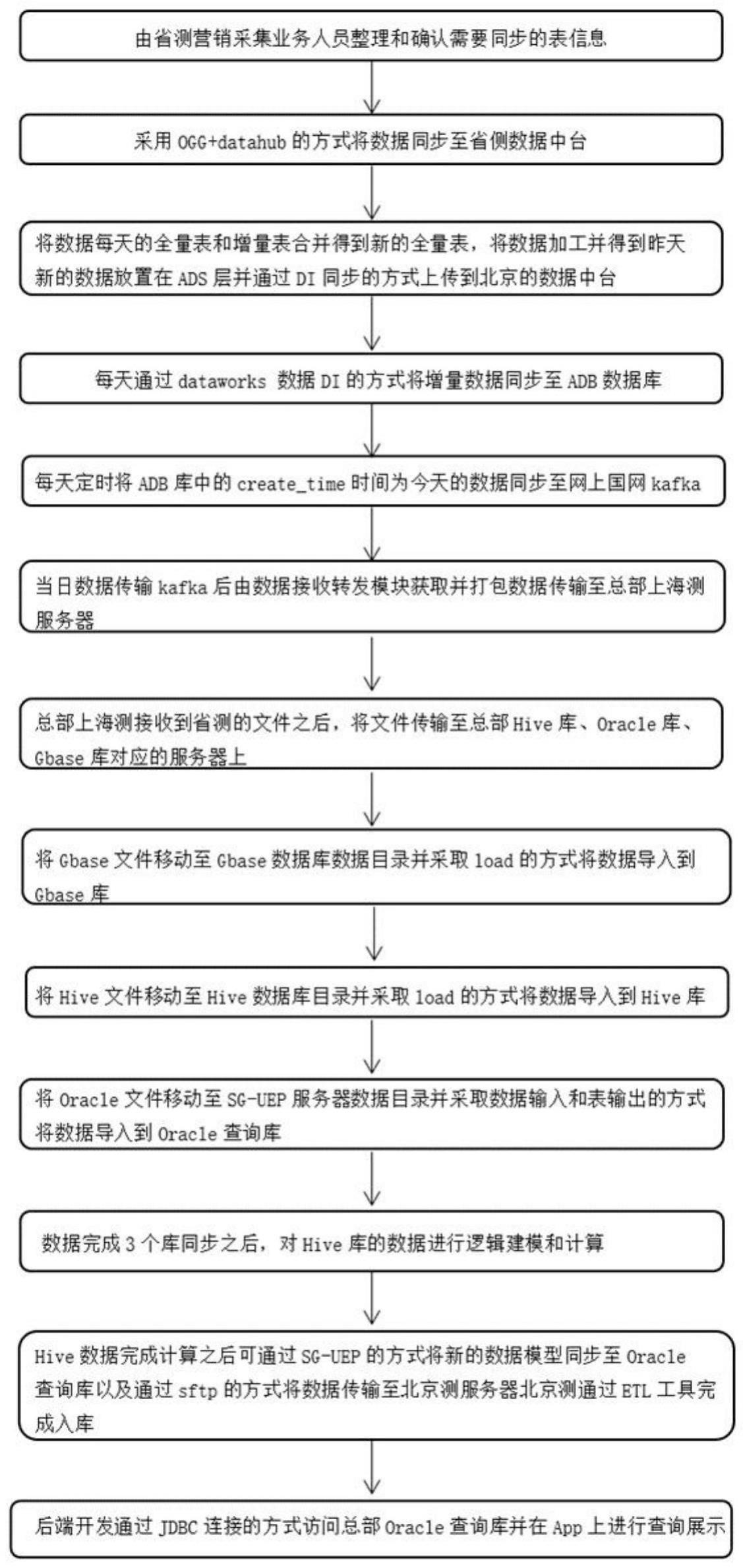
4、步骤1,在省级电网侧确认需要同步的数据信息;
5、步骤2,采用ogg+datahub的方式将省级电网侧营销采集系统中的上一天源数据同步至省级电网侧数据中台中的贴源层增量表当日分区内;
6、步骤3,将数据每天的全量表和增量表合并得到新的全量表,将数据加工并得到当日新的数据放置在ads层并通过di同步的方式上传到北京的数据中台;
7、步骤4,完成同步北京侧数据中台之后,再通过dataworks中的di同步方式将省级电网侧数据中台ads层中加工过后的增量数据同步至省级电网侧adb数据库;
8、步骤5,省级电网侧每日定时将省侧对应adb库中业务表create_time字段做为当日日期的增量数据通过省级电网侧的sg-uep工具同步至省级电网侧kafka平台;
9、步骤6,省级电网侧将当日加工过后的adb增量数据传输至kafka后由数据接收转发模块获取并打包数据传输至总部上海侧服务器;
10、步骤7,总部上海侧接收到省级电网侧上传的每日增量数据文件之后,总部上海侧将每日增量文件通过总部上海侧的数据接收转发模块传输至总部hive库、oracle库、gbase库对应的服务器上;
11、步骤8,将总部上海侧的gbase服务器中的增量文件移动至gbase数据库数据目录并采取load的方式将数据导入到gbase库;
12、步骤9,将总部上海侧hive服务器中的增量文件移动至hive数据库目录并采取load的方式将数据导入到hive库中的ods层;
13、步骤10,将总部上海侧oracle服务器中的增量文件移动至总部上海侧sg-uep服务器数据目录并采取数据输入和表输出的方式将数据导入到oracle查询库;
14、步骤11,数据完成3个库同步之后,对hive库的ods层业务数据进行清洗按照相关的数据质量标准剔除异常数据并汇入到dwd层表中,数据清洗完成之后对dwd层的业务数据以及相关的中间表进行关联匹配;
15、步骤12,总部上海侧hive数据完成计算之后可通过sg-uep的方式将新的数据模型同步至总部上海侧oracle查询库以及通过sftp的方式将数据传输至北京侧服务器;
16、步骤13,北京侧接受同步过来的数据之后通过etl工具完成入库操作,完成上海侧北京侧两端同步;
17、步骤14,后端开发通过调用jdbc连接的方式访问总部oracle查询库并在app上进行查询展示,通过jdbc的调用满足海量并发查询,其中查询效率取决于表的优化程度,数据同步至oracle查询库之后需要对表进行分区和索引的优化
18、优选地,步骤2中,增量表按天、小时、分钟三级分区,不设置生命周期,采取定期人工删除增量数据(默认半年)。
19、优选地,步骤3中,数据中台在将数据加工去除不符合数据质量规范的业务数据并得到上一天新的数据放置在省级电网侧数据中台ads层,ads层为增量数据层存放每日的增量数据并通过di同步的方式上传到北京总部的数据中台供北京侧环境使用。
20、优选地,步骤6中,对kafuka中对应topic的消费数据进行采集并以500m一个文件的标准打包数据。
21、优选地,步骤7中,总部服务器接收到上传的文件之后,通过sftp的模式将文件传输到不同的服务器上。
22、优选地,步骤13中,北京侧接收同步过来的数据后,通过etl中的文件输入-表输出的方式将数据导入到北京侧的oracle数据库。
23、优选地,步骤14中,数据同步至oracle查询库后将进一步对表进行分区和索引的优化。
24、还包括sg-uep的调度监控模块,该模块可以前台显示数据同步的进度和状态,可以用来实时监控,自研数据接收转发模块能够实现数据的文件备份和补传,以及上传状态进度的监控。
25、一种基于国网营销采集系统的数据同步链路系统,其中包括省级电网侧营销采集单元、总部北京侧数据处理单元、总部上海侧数据处理单元,其特征在于:
26、所述数据同步链路系统包括省级电网侧同步数据确认模块、省级电网侧数据同步上传模块、省级电网侧增量链路模块、省级电网侧全量生成模块、省级电网侧增量和全量结合模块、省级电网侧增量上传模块、省级电网侧数据上传监控备份模块、总部上海侧数据接收模块、总部上海侧数据备份监控模块、总部上海侧数据增量数据同步模块、总部上海侧数模计算同步模块、总部上海侧数据文件传输模块、总部北京侧数据接收模块、总部北京侧数据备份监控模块等。
27、其中所有数据同步模块均为连续且可控的,通过省级电网侧同步数据确认模块将需要同步的数据表文件提炼出来并通过省级电网侧数据同步上传模块将采集到的数据传输至省级电网侧数据中台中的增量表,并将增量表按照一定的数据质量规则与全量表进行汇总实现省级电网侧增量和全量结合模块,数据汇总完成以后通过省级电网侧增量上传模块、省级电网侧数据上传监控备份模块、总部上海侧数据接收模块来完成两级交互的数据同步,总部上海侧数据文件接收完成以后通过总部上海侧数据增量数据同步模块、总部上海侧数模计算同步模块完成总部上海侧增量数据的插入和汇总计算,完成同步和计算之后在通过总部上海侧数据文件传输模块、总部北京侧数据接收模块、总部北京侧数据备份监控模块完成北京和上海侧两级的数据同步链路。
28、本发明的有益效果在于,与现有技术相比:
29、1、能够有效解决大批量增量数据的同步,将数据采用增量与全量的结合方式实现增量数据的传输和历史数据的备份,通过设计不同的数据链路模块来优化整个同步链路做到每一个模块都是可控可维护的,并且能够做到实时监控和备份功能,在数据同步过程中某一模块出现问题可以及时定位和处理异常情况,对运维人员及开发人员使用起到了至关重要的作用。
30、2、本发明方法对大数据量的数据同步和数据处理起到了非常重要的帮助,能够提高数据同步的效率,也能够节省流转的时间,资源占用方面合理分配,能够实现多个数据库的无缝衔接,对数据的的可靠传输提供了一种方法。
- 还没有人留言评论。精彩留言会获得点赞!