一种基于监督学习的社交网络敏感委婉语检测方法
本发明涉及计算机科学与技术中的网络安全,具体为一种基于监督学习的社交网络敏感委婉语检测方法。
背景技术:
1、随着信息技术和移动互联网的不断发展,社交网络对人们的生活产生了越来越大的影响。社交网络已成为推动现实生活与虚拟空间融合的重要力量。互联网用户也越来越热衷于通过社交网络实现交流和信息共享。近年来国内非常流行的社交网络视频分享平台提供了用户创作平台,注册用户可以通过个人账号分享个人原创视频或转发视频,极具自由性和创新性。由于视频弹幕和评论数量众多,总体用户基数大且整体年龄较小,其内容创作容易包含涉及色情、暴力等有害内容。在社交网络视频分享平台的某些视频的评论和弹幕中,包含网络暴力、色情引诱等有害内容,不利于青少年的健康成长,也对我国的互联网内容安全造成了不良影响。虽然具有明显有害含义上的敏感内容容易被现有方法过滤,但是敏感委婉语,即通过委婉语表达敏感内容的语言,仍然大量存在于公共互联网平台。委婉语,即用来减弱或隐藏对受制于现实和互联网社会言论规范的敏感、不愉快或禁忌的话题的表达形式。本发明对于敏感委婉语的定义为:利用常用词汇的无害化含义进行伪装,通过恶意曲解(通过引申、借代、谐音等不同的委婉方式)的方式表达各类敏感内容(包含色情、暴力等),其中用于伪装的词汇称为敏感委婉词。
2、由于敏感委婉词利用的伪装词汇往往具有大量正常表达的语境,使得经典的基于敏感词检测的内容审核机制很难发现该类敏感内容。具体来说,一方面,内容审核者难以发现此类敏感委婉词,因为这类敏感委婉词常常夹杂在正常的无害化含义的句子语义中,通过委婉含义隐性表达敏感内容,所以很容易逃避审核。另一方面,从现实意义上,社交网络平台管理者不便于仅仅屏蔽敏感委婉词汇,因为这会导致大量正常词汇被禁止使用,将严重影响用户的正常表达。设置为敏感词进行封禁后,普通用户无法正常使用敏感委婉词的正常含义,对用户间正常交流造成困难;显而易见的是,更大比例的用户使用敏感委婉词的无害含义,而不是攻击其他用户的敏感含义。并且,即使屏蔽了某些敏感委婉词,恶意攻击者仍然可以利用类似的恶意曲解(通过引申、借代、谐音等不同的委婉方式)的方式,继续创造新的敏感委婉词,这将导致词汇屏蔽失效。现有的方法使用敏感词列表匹配来检测敏感词,并通过添加新识别的变形词来丰富敏感词库,但忽略了可变形词与原始词之间的相关性。对于敏感委婉语的检测而言,通过敏感词匹配的方式不能很好的解决敏感委婉词泛滥的现实问题。而现有的文本检测方法没有充分考虑情感信息和语义特征,且误判较多,准确率较低。
技术实现思路
1、针对上述问题,本发明的目的在于提供一种基于监督学习的社交网络敏感委婉语检测方法,更加精准,精确的实现对敏感委婉语的有效检测,为将来面向社交网络的敏感委婉语检测提供方法与思路。技术方案具体如下:
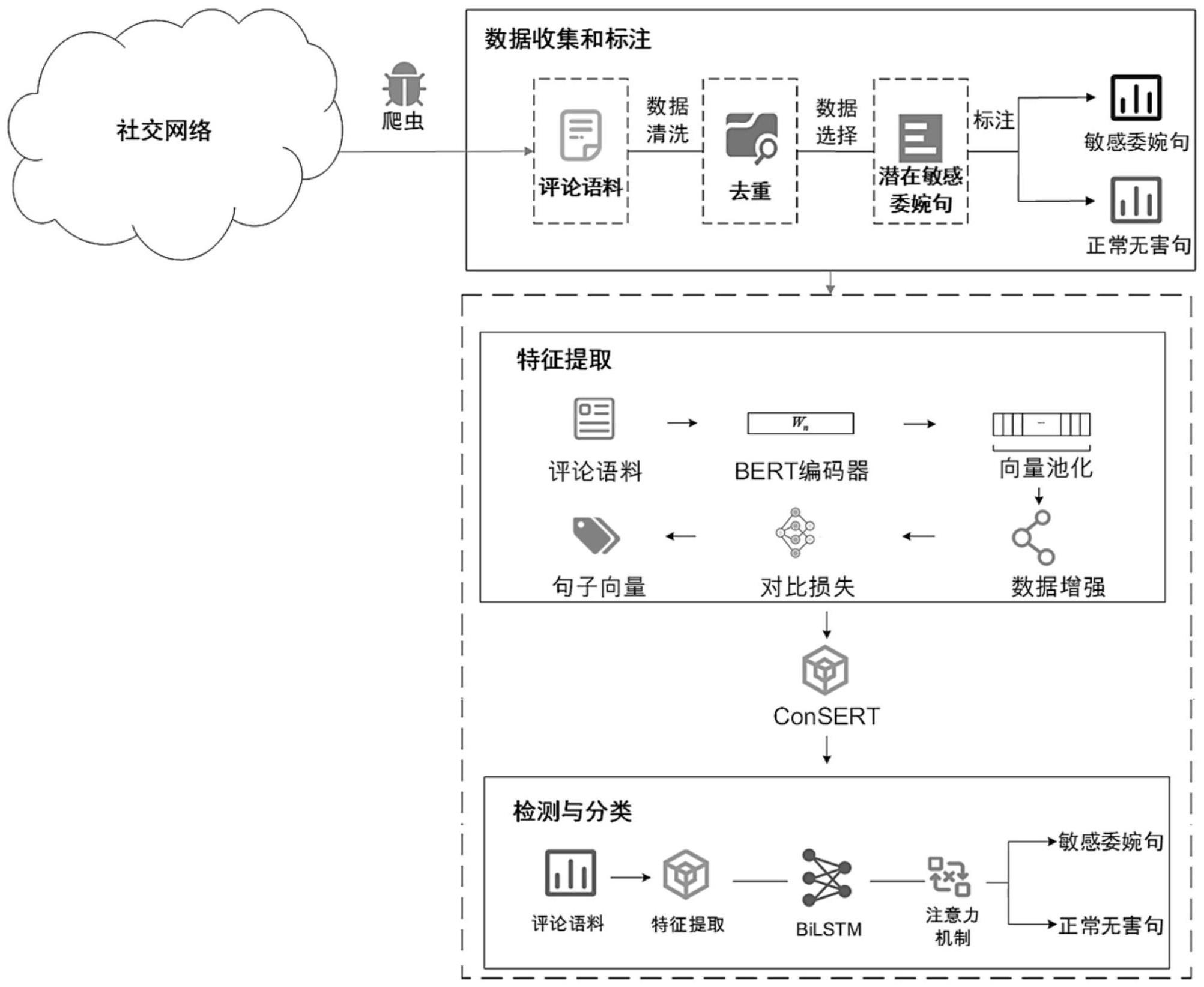
2、一种基于监督学习的社交网络敏感委婉语检测方法,包括以下步骤:
3、步骤1:数据收集与标注:采用web爬虫,对某社交网络平台上的数据进行采集,并对采集到的数据进行数据过滤和选择,再进行人工标注,从而构建敏感委婉语数据集;
4、步骤2:特征提取:在对输入句子进行初始化embedding以后生成初始句向量,通过不同的数据增强方式生成句向量的不同增强版本,再使用bert共享编码共享句向量生成参数,再采用对比学习层进行优化调整,使句向量的空间特征分布更加均匀,最终输出增强句向量;
5、步骤3:检测模型:基于consert模型构建的增强句向量,并结合bi-lstm和注意力机制构建敏感委婉句分类检测模型,将所述增强句向量输入至敏感委婉句分类检测模型中,基于句子特征向量对社交网络平台上的敏感委婉语进行检测。
6、进一步的,所述步骤1包括:
7、步骤1.1:设计支持计多进程运行的基于scrapy框架的web爬虫,用于对某社交网络平台上的视频评论和弹幕进行有针对性的采集;
8、步骤1.2:基于scrapy框架设计能够支持多进程运行的web爬虫,用于对某社交网络平台上的视频评论和弹幕进行有针对性的采集;
9、步骤1.3:将通过恶意曲解来表达敏感内容的无害化日常词汇定义为敏感委婉词,根据句子的表达内容和上下文关系,参照现有的敏感委婉词库,对可能表达与某些敏感词实际含义相似的敏感委婉句子进行人工标注。
10、更进一步的,所述人工标注敏感委婉句子的原则包括:
11、1)如果其中的敏感委婉词,按其无害化含义能够被合理解释,而按其敏感含义不能被合理解释,则该句子被视为只包含无害含义,标注为无害化句子,标签设置为0;
12、2)如果其中的敏感委婉词,按其无害化含义不能够被合理解释,而按其敏感含义能被合理解释,则该句子视为只包含敏感含义,标注为敏感委婉句子,标签设置为1;
13、3)如果一个句子的语义信息只包含辅助词汇和敏感委婉词,且既能被无害化含义解释,又能被敏感含义解释,则该句子视为同时包含敏感含义和无害含义,标注为敏感委婉句子,标签设置为1;
14、4)如果其中的敏感委婉词,按其无害化含义不能被合理解释,并且按其敏感含义也不能被合理解释,则该句子视为语义不清,被过滤掉,不设置标签。
15、更进一步的,步骤1中还包括对人工标注的标注效果进行评估,具体为:
16、采用两名标注者独立浏览数据集中的所有待标注句子,通过计算kappa系数来评估标注结果的一致性:
17、
18、其中,a为第一个标注者标注的句子集合,b为第二个标注者标注的句子集合;c为第一个标注者无法判别是否为敏感委婉句的句子集合,d为第二个标注者无法判别是否为敏感委婉句的句子集合。e是所有句子的集合,|·|是一个集合的大小。
19、更进一步的,所述步骤2具体包括:
20、步骤2.1:通过输入层输入经过预处理的数据文本i={i1,i2,...,in};
21、预处理后的句子ij包含n个字,n为设置的最大序列长度,将超过n字的部分舍去,不足则补0;
22、步骤2.2:通过调优后的bert模型对输入层的数据文本处理后生成初始句向量;
23、步骤2.2.1:利用所述社交网络平台上的视频评论和弹幕数据对bert-base-chinese模型进行预训练,并运用ses-dataset数据集对该模型进行微调,得到调优后的bert模型;
24、步骤2.2.2:将预处理后的数据文本i={i1,i2,...,in}标记化后得到标记文本i'={i1',i'2,...,i'n},将其输入至调优后的bert模型中,进行词嵌入提取后通过平均池化,从而得到句嵌入形式的优质语义特征w={w1,w2,...,wn};如下式:
25、i'=tokenize(i) (2)
26、w=bert(i') (3)
27、s=averagepooling(w1,w2,...,wn) (4)
28、其中,s为句向量;
29、步骤2.3:通过数据增强层根据不同的数据增强策略生成用于对比学习的样本对;
30、步骤2.4:通过对比损失层完成对比预测任务
31、给定一个集合包括一对正样例和对比预测任务的目的是对于一个给定的在中识别出
32、从同一增强集合t~t和t't中采样两个单独的数据增强算子,并应用于每个数据样例,以获得两个相关的样本对;利用得到的样本对,对一个基本编码器网络f(·)和一个投影神经网络g(·)进行训练,训练完成后,去掉投影头g(·),并将编码器f(·)和表示h用于下游任务;
33、通过随机抽取n批样本,并对于小批量的增强样本对,定义对比预测任务,得到2n个数据点;再给定一个正样本对,将一个小批中的其他2(n-1)增强样本视为负样本;
34、由此得到正样本对(a,c)的损失函数的定义,即正则化温度缩放交叉熵损失函数,如下式所示:
35、
36、其中,1[k≠a]∈{0,1}是一个当且仅当k≠a时取值为1的指标函数,τ代表温度参数;表示通过l2正则化后的za和zk的余弦相似度,za、zc和zk分别为样本a、样本c和样本k的向量。
37、更进一步的,所述步骤2.3中数据增强策略包括对抗攻击,具体如下:
38、设θ是一个模型的参数,x是模型的输入,y是与x相关联的目标,j(θ,x,y)是用于训练神经网络的损失;将损失函数围绕θ的当前取值做线性化处理,如下式:
39、η=εsign(▽xj(θ,x,y)) (6)
40、式中,η为改进损失值,ε为学习率或学习比例参数,▽x为梯度计算;
41、使用反向传播计算出所需的梯度,以训练一个单个模型p(y=1)=σ(wtx+b)来识别标签y∈{-1,1},σ(z)是sigmoid函数;则带梯度下降的训练过程如下:
42、
43、其中,为目标数据的梯度下降训练过程的符号表示,ζ(z)=log(1+exp(z))是softplus函数;w为权重系数,b为偏置系数;
44、梯度的符号只是-sign(ω),而ωtsign(ω)=||ω||1,ω为权重向量;则逻辑回归的对抗性版本是最小化以下式子:
45、
46、其中,||ω||1为预测概率为1时权重向量内积。
47、更进一步的,所述步骤2.3中数据增强策略包括位置打乱,具体如下:
48、通过操纵输入句子的位置和句嵌入来打乱输入句子,在通过bert对打乱的输入进行编码后,考虑上下文的嵌入c=[hcls,h0,...,hn-1,hsep],其对应于插入到输入序列中的ntoken个句子token,以及第一个[cls]token和最后一个[sep]token;将其传递给序列重构器,进行原句子排序的重构;
49、除了最后的[sep]tokenhsep外,c中的嵌入通过transformer解码器依次处理,以获得输出wi;同时考虑整个c和前面步骤中处理的嵌入每个处理后的输出将用于预测步骤i中的句子i,如下式所示:
50、
51、式中,ci为第i个句子的句嵌入;
52、使用指针网络计算句子表示上的概率分布,每个概率表示每个句子在第一步中出现的可能性,如下式所示:
53、pi=soft max(wict) (10)
54、计算一个交叉熵损失来匹配每个上下文的句子,其中嵌入预测顺序的概率分布与黄金位置;是句子j-1出现在位置i的预测概率,oi是步骤i中正确位置的一个标注向量;最后,将所有位置的损失平均为i=0,...,m,如下式所示:
55、
56、式中,γslm为平均交叉熵损失,m为句子位置数,oi,j为句子对应位置的标注向量,pi,j为句子j-1出现在位置i的预测概率;
57、模型只使用句子表示来找到原始序列,通过强制编码器将所有必要的信息嵌入到上下文的句子嵌入中,而不是将它们扩展到所有嵌入中,如式下所示:
58、γ=γslm+γmlm (12)
59、式中,γ为修改后的交叉熵损失,γmlm为最小交叉熵损失。
60、更进一步的,所述步骤2.3中数据增强策略包括cutoff和dropout;
61、cutoff具体为两种方式:使用token cutoff,随机选取token,将对应token的embedding整行置为零,或者使用feature cutoff,随机选取embedding的feature,将选取的feature维度整列置为零;
62、dropout具体为:以特定的概率在标记嵌入层中随机放置元素,并将它其值设置为零,且单独考虑每个元素。
63、更进一步的,所述步骤3具体包括:
64、步骤3.1:将提取到的句向量s输入至bi-lstm网络中,依托其记忆功能进一步学习上下文特征,从而得到一维的语义特征向量h={h1,h2,...,hhid};hid为网络中隐含节点的个数,hi的计算方式如下式所示:
65、
66、
67、
68、其中,是lstm上一个状态产生的隐含向量,是lstm下一个状态产生的隐含向量,wi为词向量;
69、步骤3.2:将经过bi-lstm层处理后的句向量投入到注意力机制中,对于特定的敏感委婉词汇会赋予更高的权重,以提升敏感委婉句检测的效果,如下式所示:
70、ui=tanh(ww·fi+bw) (16)
71、
72、
73、其中,ww和bw表示权重矩阵和偏置项,ui为输出向量fi的中间隐藏层向量;uw是一个随机初始化的向量,其已经在训练的过程中作为模型的参数进行了优化;权重αi由softmax函数实现,通过计算中间向量ui和uw的相似度,确定输出向量fi的权重αi;此外,fe为最终判断句子是否为敏感委婉句的向量,t为top层;tanh(·)表示缩放因子,是双曲正切函数;
74、步骤3.2:将经过bi-lstm网络和注意力机制训练后的句向量降维,放入到sigmoid函数中得到该句向量是敏感委婉句的概率,以此得到最终的分类结果,如下式所示:
75、pd=sigmoid(fe) (19)
76、其中,pd为句子为敏感委婉句的概率。
77、更进一步的,所述敏感委婉句分类检测模型的优化目标为最小化交叉熵损失函数,如下式所示:
78、
79、其中,d表示样本数据集,d表示样本,yd表示样本的真实值,pd为样本d预测为正类的概率,l为目标最小化交叉熵损失。
80、本发明的有益效果是:本发明基于对比学习的consert框架进行句子表征,并结合bi-lstm(bidirectional long short-term memory,双向长短期记忆网络)和注意力机制提出了sed(sensitive-euphemism-detection)模型,实现了对敏感委婉语的有效检测;实验评估结果表明sed模型在敏感委婉语检测问题上的效果优于常用的敏感内容检测方法;本发明的研究工作为将来面向社交网络的敏感委婉语检测提供了方法与思路。
- 还没有人留言评论。精彩留言会获得点赞!