基于特征融合与注意力机制的医疗问答文本情感分析方法
本发明涉及医疗文本情感分析的,尤其涉及基于特征融合与注意力机制的医疗问答文本情感分析方法。
背景技术:
1、医疗是人类生存的重要保障之一,而随着互联网和移动互联网的普及,越来越多的人选择通过网络咨询医生和搜索医疗信息来获取帮助和解决问题。医疗问答平台和应用已经成为了人们获取医疗知识和服务的主要渠道之一。但是,对于这些医疗问答数据,如何准确地对其情感进行分析,可以更好地理解患者的需求和情感倾向,有助于医生更好地回答问题、提供更好的服务,同时也可以帮助患者更好地了解和管理自己的健康状况。
2、情感分析是自然语言处理的一个重要应用领域,旨在对文本中所表达的情感进行分析和判断。在医疗问答领域中,情感分析可以帮助医生更好地了解患者的需求和情感状态,更好地进行诊断和治疗。同时,情感分析还可以帮助医疗平台和应用提供更好的推荐服务和个性化建议,从而提高患者的满意度和体验。因此,医疗问答文本情感分析的研究具有重要的意义和应用前景。
技术实现思路
1、鉴于上述现有存在的问题,提出了本发明。
2、因此,本发明目的是提供基于特征融合与双向注意力机制的医疗问答文本情感分析方法,解决现阶段对医疗问答文本语义完整复杂性缺乏研究以及对于医疗问答文本患者问题文本和医生答案文本之间存在情感交互信息缺乏考虑的问题。
3、为解决上述技术问题,本发明提供如下技术方案:
4、第一方面,本发明实施例提供了基于特征融合与双向注意力机制的问答文本情感分析,包括:
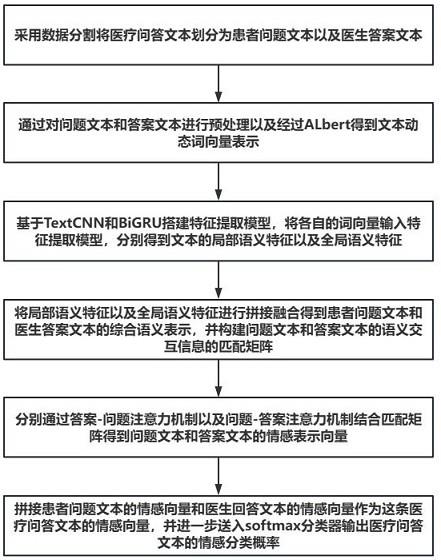
5、将医疗问答文本通过数据分割划分为患者问题文本和医生答案文本,并进行预处理;
6、将预处理后的患者问题文本和医生答案文本分别经过albert预训练模型得到各自对应的文本表示向量;
7、将患者问题文本以及医生答案文本的文本表示向量分别输入到textcnn和bigru中得到各自文本的局部特征向量和全局特征向量;
8、将局部特征向量和全局特征向量拼接得到患者问题文本和医生答案文本的综合语义表示向量并构建问答文本语义交互信息的匹配矩阵;
9、通过双向注意力机制结合所述匹配矩阵得到问题文本和答案文本的情感表示向量,将问题文本和答案文本的情感表示向量拼接得到最终医疗问答文本的情感表示向量;
10、将最终医疗问答文本情感表示向量输入到softmax分类器中进行情感分类,得到医疗问答文本的情感分类的概率。
11、作为本发明所述的基于特征融合与注意力机制的医疗问答文本情感分析方法,其中:将患者问题文本以及医生答案文本的文本表示向量输入到textcnn中得到各自文本的局部特征向量包括,
12、嵌入层embeddinglayer:将输入的单词序列转换为单词向量表示;
13、卷积层convolutionlayer:使用多个不同大小的卷积核对单词向量序列进行卷积操作,提取局部的特征,对于每个卷积核,会生成一组卷积特征图,表示不同的局部特征,具体公式如下:
14、;
15、其中, x i+j为从输入序列中取出的一个长度为k的子序列, w j为卷积核的权重,b为偏置, f为激活函数;
16、池化层poolinglayer:对于每个卷积特征图,使用max-pooling操作对特征值进行汇总,得到一个固定长度的向量表示,具体公式如下:
17、 v j=max({ h i,j| i∈[1, n- k+1]})
18、其中, h i,j为卷积特征图j中第i个位置的特征值,n为输入序列的长度,k为卷积核的大小。
19、作为本发明所述的基于特征融合与注意力机制的医疗问答文本情感分析方法,其中:将患者问题文本以及医生答案文本的文本表示向量输入到bigru中得到各自文本的全局特征向量包括,
20、输入序列中的每个单词向量经过bigru的正向传播和反向传播,得到正向和反向的隐藏状态向量;
21、将正向和反向的隐藏状态向量拼接,得到当前时间步的全局特征向量;
22、重复拼接正向和反向的隐藏状态向量直到处理完整个输入序列,得到所有时间步的全局特征向量。
23、作为本发明所述的基于特征融合与注意力机制的医疗问答文本情感分析方法,其中:所述匹配矩阵包括,
24、患者问题文本和医生答案文本之间的语义交互信息;
25、通过以下公式计算得到问题文本和答案文本的语义交互信息的匹配矩阵:
26、 m=( h q) t×( h a)
27、其中,m为包含了语义交互信息的匹配矩阵, h q为问题文本的综合语义表示, h a为答案文本的综合语义表示。
28、作为本发明所述的基于特征融合与注意力机制的医疗问答文本情感分析方法,其中:所述双向注意力机制包括答案-问题注意力机制以及问题-答案注意力机制。
29、作为本发明所述的基于特征融合与注意力机制的医疗问答文本情感分析方法,其中:所述答案-问题注意力机制包括,
30、所述答案-问题注意力机制的具体公式如下:
31、 u r=tanh( w r× m t)
32、 a r=softmax( w r t× u r)
33、其中, a r为衡量问题文本中词语情感重要程度的权重, w r和 w r为注意力机制的参数,tanh为非线性激活函数;
34、通过 h q和情感权重 a r,计算患者问题文本中包含情感信息的情感向量 v r。
35、作为本发明所述的基于特征融合与注意力机制的医疗问答文本情感分析方法,其中:所述问题-答案注意力机制包括,
36、所述问题-答案注意力机制的具体公式如下:
37、 u c=tanh( w c× m)
38、 a c=softmax( w c t× u c)
39、其中, a c为衡量答案文本中词语情感重要程度的权重, w c和 w c为注意力机制的参数;
40、通过 h a和情感权重 a c,计算医生答案文本中包含情感信息的情感向量 v c。
41、第二方面,本发明实施例提供了一种基于特征融合与注意力机制的医疗问答文本情感分析系统,包括,
42、划分模块,用于将医疗问答文本通过数据分割划分为患者问题文本和医生答案文本,并进行预处理;
43、训练模块,用于将预处理后的患者问题文本和医生答案文本分别经过albert预训练模型得到各自对应的文本表示向量;
44、特征融合模块,用于将患者问题文本以及医生答案文本的文本表示向量分别输入到textcnn和bigru中得到各自文本的局部特征向量和全局特征向量,将局部特征向量和全局特征向量拼接得到患者问题文本和医生答案文本的综合语义表示向量,构建匹配矩阵,通过双向注意力机制结合所述匹配矩阵得到问题文本和答案文本的情感表示向量,将问题文本和答案文本的情感表示向量拼接得到最终医疗问答文本的情感表示向量;
45、输出模块,用于将最终医疗问答文本情感表示向量输入到softmax分类器中进行情感分类。得到医疗问答文本的情感分类的概率。
46、第三方面,本发明实施例提供了一种计算设备,包括:
47、存储器和处理器;
48、所述存储器用于存储计算机可执行指令,所述处理器用于执行所述计算机可执行指令,当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如本发明任一实施例所述的基于特征融合与双向注意力机制的问答文本情感分析。
49、第四方面,本发明实施例提供了一种计算机可读存储介质,其存储有计算机可执行指令,该计算机可执行指令被处理器执行时实现所述基于特征融合与双向注意力机制的问答文本情感分析。
50、本发明的有益效果:本发明提出的方法能够很好的解决现阶段对医疗问答文本复杂性研究缺乏,以及很好的捕抓医疗问答文本的全局特征和局部特征,极大的丰富了医疗问答文本的语义表示完整性,进一步的由于此前缺乏对于医疗问答文本患者问题文本和医生答案文本之间存在情感交互信息的考虑,通过构建患者问题文本和医生答案文本之间语义交互信息的匹配矩阵,并应用双向注意力机制即答案-问题注意力机制和问题-答案注意力机制,来捕抓问题文本和答案文本中词语的情感权重,得到医疗问答文本的情感表示向量,提高了医疗问答文本情感分类准确率,医疗问答文本的情感分析相比较于传统的文本存在很大差异,该方法能够很好的处理医疗问答文本的情感分类任务。
- 还没有人留言评论。精彩留言会获得点赞!