基于改进YOLOv3的智能网联汽车行人检测方法
本发明属于车联网技术,具体涉及一种基于改进yolo v3的智能网联汽车行人检测方法。
背景技术:
1、随着计算机科学技术的发展,以及社会生活质量的逐步提高,道路上的车辆数目也在不断上升,行人检测作为自动驾驶和车辆辅助驾驶领域中一项关键的技术,在道路行车安全中起着重要的作用。但是,在道路交通复杂的背景下,驾驶员可能会因为视线受限等因素,来不及反应,从而导致交通事故的发生。使用计算机视觉技术提高行人的检测率,有利于辅助驾驶员提前了解道路行人情况,预留充足的时间调整行车方向;使用边缘计算节点可以提升行人检测的实时性;使用云服务器协同边缘计算节点进行模型训练,弥补了边缘计算节点算力不足的问题;同时,在智能网联汽车中也可以使控制系统捕获到更多的行人信息,以正确的规划行车方向,从而提高道路行驶的安全性。
技术实现思路
1、发明目的:本发明的目的在于解决现有技术中存在的不足,提供一种基于改进yolo v3的智能网联汽车行人检测方法,通过本发明能够解决汽车行车过程中驾驶员由于视力受限、视线受阻等因素忽略行人而引发事故的问题。
2、技术方案:本发明的一种基于改进yolo v3的智能网联汽车行人检测方法,包括以下步骤:
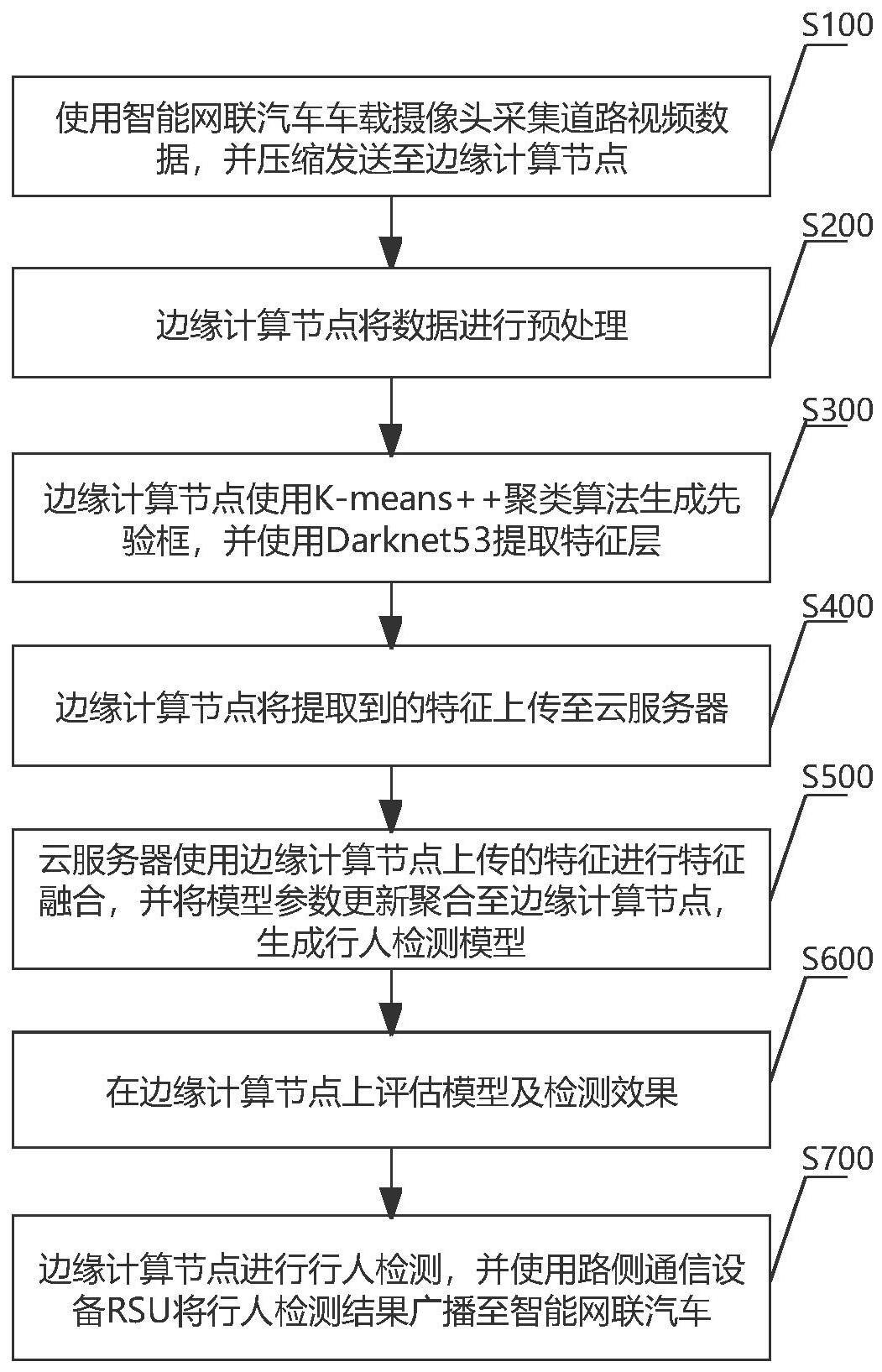
3、步骤s100、向边缘计算节点发送道路视频数据;
4、步骤s200、边缘计算节点将收到的道路视频数据进行预处理得到相应rgb图片数据集,并将rgb图片数据集上传至云服务器;
5、步骤s300、边缘计算节点使用k-means++聚类算法生成先验框;
6、步骤s400、生成行人检测模型,具体过程为:
7、步骤s401、对yolo v3模型网络进行改进,改进后yolo v3模型网络包括27个cbl模块、3个上采样模块、3个特征融合模块、7个cbam模块和4个检测头;
8、步骤s402、对改进的yolo v3模型网络进行分割,将分割后的改进的yolo v3模型网络分别部署在边缘计算节点和云服务器;其中,在边缘计算节点上构建用于特征提取的输入层、1个cbl模块和1个残差块;在云服务器上构建用于特征提取和特征融合的4个残差块和27个cbl模块;
9、步骤s403、使用边云协同基于迁移学习进行模型训练:在云服务器基于道路行人数据集(例如caltech行人数据集)进行多次训练获得最优权重,作为基础模型并部署到边缘计算节点,同时在边缘计算节点上使用基础模型作为初始参数进行训练;将云服务器训练所得最优权重聚合在边缘计算节点并生成行人检测模型;
10、步骤s500、在边缘计算节点上评估步骤s403所得行人检测模型及检测效果:
11、步骤s501,在边缘计算节点上使用行人检测模型在测试集上进行行人检测,根据pascal voc标准计算模型检测精准度;
12、步骤s502,使用检测精度最高的权重用于行人检测;
13、步骤s600、边缘计算节点进行行人检测,并使用路侧通信设备rsu将行人检测结果广播至智能网联汽车。
14、进一步地,所述步骤s100的详细过程为:
15、步骤s101、使用智能网联汽车车载摄像头在道路行驶中拍摄道路视频数据;
16、步骤s102、智能网联汽车将采集的道路视频数据进行压缩;
17、步骤s103、智能网联汽车将压缩后的道路视频数据使用车-互联网v2n技术(vehicle-to-network)发送至边缘计算节点。
18、进一步地,所述步骤s200的详细过程包括:
19、步骤s201、边缘计算节点使用rtsp协议接收道路视频数据;
20、步骤s202、边缘计算节点将道路视频数据格式转为pascal voc格式的图片数据;
21、步骤s203、边缘计算节点使用中值滤波和梯度法进行图像预处理将步骤s202所得图片数据进行去噪、亮度调节和转化为rgb图片;
22、步骤s204、边缘计算节点将处理后的rgb图片数据集上传至云服务器,进行数据的存储。
23、进一步地,所述步骤s300中基于k-mens++聚类算法聚类获得12个先验框,然后采用真实框和边界框的交并比函数iou作为距离度量,采用准确度达到83.20%的距离度量结果作为最终先验框的取值,即[6,14],[8,17],[8,23],[10,20],[11,25],[11,34],[14,29],[15,38],[18,47],[23,58],[33,87]和[62,158];
24、所述距离度量的计算方式如下:
25、distance(box,centroid)=1-iou(box,centroid) (1)
26、上式中,box表示bounding boxes;centroid表示anchor boxes,即边界框的簇中心;iou表示bounding boxes与anchor boxes的交并比;
27、所述iou为真实框和簇内中心的交并比,计算方式如下:
28、
29、上式中gt(ground truth)表示目标的真实框,dr(detection result)表示目标的预测框。
30、本发明中k-mens++算法的逻辑为:
31、(1)选择距离足够远的k个点作为聚类中心;
32、(2)计算数据集中每个点和聚类中心的距离;
33、(3)轮盘法选出下一个聚类中心;
34、(4)求每一个簇iou均值,并更新聚类中心。
35、进一步地,对于步骤s401改进后的yolo v3模型网络,
36、每个cbl模块均包括二维卷积(darknet conv2d)结构、批处理归一化(batchnormalization)和非线性激活函数(leaky relu)卷积;
37、每个上采样模块均使用3×3和1×1的卷积改变特征层的大小;
38、所述3个特征融合模块将主干网络倒数第二个残差块的输出特征层和第一个上采样模块的输出特征层进行堆叠、将倒数第三个残差块的输出特征层和第二个上采样模块的输出特征层进行堆叠,以及将倒数第四个残差块的输出特征层和第三个上采样模块的输出特征层进行堆叠;
39、所述7个cbam模块采用混合域注意力机制同时对通道注意力和空间注意力进行打分,从而减少有效信息的丢失;
40、所述4个检测头依次为13×13×18、26×26×18、52×52×18和104×104×18的输出特征层。
41、上述改进后yolo v3模型网络的backbone主干网络在darknet53的基础上,增加了混合域注意力机制cbam,包括:空间注意力机制和通道注意力机制;具体为在主干网络中的残差块之间直接插入所述cbam模块,增加特征提取的表现力;其中,输入cbam的特征层分别为208×208×64、104×104×128、52×52×256和26×26×512;backbone主干网络增加一次上采样,将52×52×128的特征层变为104×104×64的特征层,并将主干网络第二个残差块输出的104×104×128特征层与104×104×64的特征进行类似fbn的融合,再经过卷积,使得最终输出四个检测头;在backbone部分中的特征融合输出后,增加三个cbam模块提高特征提取的精度。
42、进一步地,所述步骤s403边缘计算节点和云服务器进行边云协同训练的详细过程为;
43、首先,将数据进行数据增强,并在边缘计算节点上进行卷积运算得到208×208×64的残差块;(前述数据增强的方式为:将图片以416×416为基准,将图片在小范围内随机获得两个比例作为新生成的图片的宽和高;将其放到416×416的画布上,采用灰条填充空白处)
44、然后,将卷积的结果上传至云服务器,完成darknet53的特征提取和三次特征融合;训练过程分批次将训练集输入改进的yolo v3模型,进行前向传播,计算参数的损失值;
45、最后,输出4个检测头,又通过反向传播调整训练参数。
46、此处计算参数的损失值包括:预测框损失、置信度损失和类别损失;而预测框损失采用误差平方和损失、所述置信度损失和类别损失采用二元交叉熵,公式如下:
47、
48、上式中,λcoord是坐标预测的惩罚系数,λnoobj是不具目标时置信度的惩罚系数,s×s是网格所划分的数量,m是每个网格预测的边界框的数量,tx、ty、tw和th代表预测目标中心的横坐标、纵坐标、宽和高,t′x、t′y、t′w和t′h代表真实目标中心的横坐标、纵坐标和宽高,代表第j个候选框目标边框所在位置的第i个网格检查该物品,第j个候选框目标边框所在位置的第i个网格不检查该物品,ci代表属于某一类别的预测置信度,ci′代表属于某一类别的真实置信度,pi(c)表在第i个网格中的目标属于某一类别的预测概率数,pi′(c)表示第i个网格中目标属于某一类别的真实概率值,c表示类别,classes表示类别总数。
49、此处进行前向传播时采用leaky relu作为激活函数,通过leaky relu激活函数将上一层特征层的输出做非线性的转化,leaky relu表达式如下:
50、
51、上式中,α是(0,1)内的固定参数,x是输出值;
52、目标检测结果采用非极大抑制nms根据置信度参数进行结果的过滤。
53、进一步地,所述步骤s501的pascal voc标准包括:
54、map、precision、recall、f1,计算方法为:
55、
56、
57、其中,是时的precision。
58、
59、其中,true positive(tp):正样本被预测为正样本;false negative(fn):正样本被预测为负样本;false positive(fp):负样本被预测为正样本;true negative(tn):负样本被预测为负样本。
60、
61、调和平均数
62、进一步地,所述步骤s502的详细方法为:
63、选择map结果最高的模型作为行人检测的结果;
64、行人检测的步骤依次包括:(1)读取模型参数;(2)输入检测数据;(3)将k-means++聚类的先验框作为行人检测的初始框,进行目标框解码,获得行人中心点坐标和宽高参数;
65、其中,目标框解码的方法为:将图片进行不失真的resize处理;对图片进行归一化;生成先验框参数(x,y,w,h);生成先验框调整参数;返回输出结果作为预测框。
66、有益效果:本发明利用改进的yolo v3模型使用边云协同训练的方式,有效地解决了智能网联汽车场景下行人检测速度慢、检测模型准确度不高的问题。使用边缘计算节点可以提升行人检测的实时性;使用云服务器协同边缘计算节点进行模型训练,弥补了边缘计算节点算力不足的问题;同时,在智能网联汽车中也可以使控制系统捕获到更多的行人信息,以正确的规划行车方向,从而提高道路行驶的安全性。本发明中对yolo v3算法的改进,可以提升行人检测的精度,降低小行人漏检、误检的问题。
- 还没有人留言评论。精彩留言会获得点赞!