一种网页利益相关方名称提取方法及装置与流程
本发明涉及数据提取,具体的说是一种网页利益相关方名称提取方法及装置。
背景技术:
1、随着技术的发展,数据等同于财富。通常情况下,普通用户可以从网页上获得他们想要的数据;然而,当研究人员和数据分析师想要获得大量的数据用于研究目的时,研究人员在浩如烟海的网页数据中获取包含特定关键词的数据是相当困难的。为了解决这个问题,去验证文章/报道/博客中存在的利益相关方或特定关键词,是一种较好的数据清洗方法;与此同时,社会舆论对于企业的发展至关重要:企业需要快速判断互联网中是否存在与自身休戚相关的报道,以快速反应和应对社会舆论;对个人而言,在个人需要判断自身信誉状况或者个人评价时,从互联网之中筛选与自身相关的信息无疑是一种慢而难的事。
2、现有的技术中对利益相关人信息提取存在以下痛点:
3、(1)基准确度不高。由于目前对于利益相关人的信息提取主要基于数据库全匹配,如果表现为企业缩写,那么全匹配工具则无法奏效;同样的痛点对于个人名称更是如此。
4、(2)费时费力.企业或者个人名称数据库需要长时间的维护,这将是一笔极高的时间以及经济成本。
5、(3)提取支持较少。目前的利益相关方提取方式主要从正文之中提取,而对于可能存在于非正文的元素没有进行提取。
技术实现思路
1、本发明针对目前技术发展的需求和不足之处,提供一种网页利益相关方名称提取方法及装置。
2、首先,本发明的一种网页利益相关方名称提取方法,解决上述技术问题采用的技术方案如下:
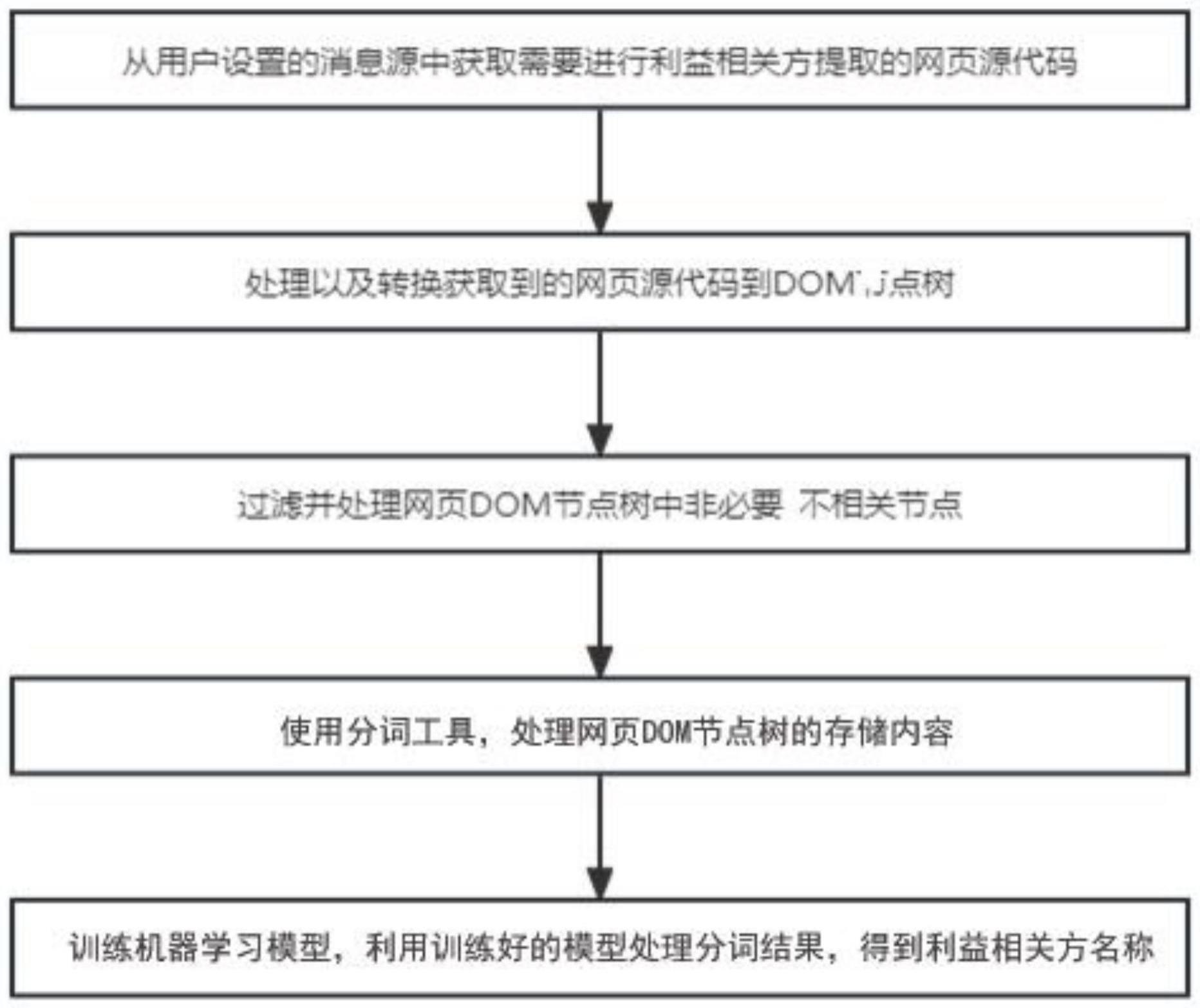
3、一种网页利益相关方名称提取方法,包括如下步骤:
4、s1、从用户设置的消息源中获取需要进行利益相关方提取的网页源代码;
5、s2、根据html本身半结构化特性,处理以及转换获取到的网页源代码到dom节点树;
6、s3、过滤网页dom节点树中非必要/不相关节点,提升后续分类分词速度;
7、s4、使用分词工具,处理网页dom节点树的存储内容;
8、s5、使用利益相关方名称预先训练机器学习模型,利用训练好的机器学习模型处理步骤s4的分词结果,得到利益相关方名称。
9、可选的,步骤s1从用户设置的消息源中获取需要进行利益相关方提取的网页源代码,进一步包括:
10、从服务器或者本地机器中获取网页源代码;
11、根据网页源代码的信息特征,识别出所需网页类型入口网址;
12、甄别网页本身编码方式,并根据网页的编码方式读取网页源代码。
13、可选的,步骤s2根据html本身半结构化特性,处理以及转换获取到的网页源代码到dom节点树,进一步包括:
14、将网页源代码转换为dom节点树的形式;
15、封装并提供数据处理方法,以对dom节点树的数据进行处理。
16、可选的,步骤s3过滤网页dom节点树中非必要/不相关节点,提升后续分类分词速度,进一步包括:
17、通过dom节点树的节点内含信息,删除dom节点树中的非必要/不相关节点,具体包括垃圾信息、导航栏、正文内广告、空节点;
18、删除dom节点树中的文字加粗节点、下划线节点,并将删除节点中的内容和父节点进行整合;
19、整理/合并/转换dom节点树中的多个同类型tag,方便后续进行数据处理;
20、对待提取网页中存在语法错误的节点进行纠错,以获取修正后的dom节点树。
21、可选的,步骤s4中使用分词工具jieba2,处理网页dom节点树的存储内容,进一步包括:
22、定制分词工具jieba2所使用的分词数据集,以切分dom节点树内容为词组;
23、设置分词工具jieba2的切分粒度,以确保利益相关方名称不被拆分理解。
24、可选的,步骤s5使用利益相关方名称预先训练机器学习模型,利用训练好的机器学习模型处理步骤s4的分词结果,得到利益相关方名称,进一步包括:
25、从互联网数据中提取利益相关方名称,组成数据集;
26、使用指定的编码方式,将数据集的利益相关方名称编码为可以被机器学习模型理解的数据类型;
27、使用编码后的数据训练机器学习模型;
28、使用k-fold方式,计算验证机器学习模型的准确率、召回率、精确度和f1-score,在验证结果超出设定阈值后,输出机器学习模型;
29、使用机器学习模型从步骤s4的分词结果中提取利益相关方名称,将提取内容以指定的编码导出到文本文档或存储介质中。
30、其次,本发明的一种网页利益相关方名称提取装置,解决上述技术问题采用的技术方案如下:
31、一种网页利益相关方名称提取装置,包括:
32、代码读取模块,用于从用户设置的消息源中获取需要进行利益相关方提取的网页源代码;
33、处理转换模块,用于根据html本身半结构化特性,处理以及转换获取到的网页源代码到dom节点树;
34、节点过滤模块,用于过滤网页dom节点树中非必要/不相关节点,提升后续分类分词速度;
35、分词处理模块,用于使用分词工具,处理网页dom节点树的存储内容;
36、训练模块,用于使用利益相关方名称预先训练机器学习模型,训练好的机器学习模型处理分词处理模块输出的分词结果,得到利益相关方名称。
37、可选的,用户设置的消息源包括在线网页和本地网页;
38、代码读取模块基于消息源的类型识别出所需网页类型入口网址,随后甄别网页本身编码方式,并根据网页的编码方式读取网页源代码;
39、处理转换模块根据html本身半结构化特性,首先将代码读取模块读取的网页源代码转换为dom节点树形式,随后封装并提供数据处理方法,以对dom节点树的数据进行处理。
40、可选的,节点过滤模块过滤网页dom节点树中非必要/不相关节点,提升后续分类分词速度,具体包括:
41、节点过滤子模块,用于基于dom节点树的节点内含信息,删除dom节点树中的非必要/不相关节点,具体包括垃圾信息、导航栏、正文内广告、空节点;
42、节点删除子模块,用于删除dom节点树中的文字加粗节点、下划线节点,并将删除节点中的内容和父节点进行整合;
43、节点转换归类子模块,用于整理/合并/转换dom节点树中的多个同类型tag,方便后续进行数据处理;
44、节点树纠错子模块,用于对待提取网页中存在语法错误的节点进行纠错,以获取修正后的dom节点树。
45、可选的,分词处理模块首先定制分词工具jieba2使用的分词数据集,以切分dom节点树内容为词组,随后设置分词工具jieba2的切分粒度,以确保利益相关方名称不被拆分理解,最后使用分词工具jieba2,处理网页dom节点树的存储内容;
46、训练模块使用从互联网数据中提取的利益相关方名称作为数据集,将数据集按照指定编码方式编码后训练机器学习模型,机器学习模型训练完成后,使用k-fold方式计算验证机器学习模型的准确率、召回率、精确度和f1-score,在验证结果超出设定阈值后,将完成机器学习模型从分词处理模块输出的分词结果中提取利益相关方名称,并将提取结果输出到文本文档或存储介质中。
47、本发明的一种网页利益相关方名称提取方法及装置,与现有技术相比具有的有益效果是:
48、本发明可以高效提取网页中指定的利益相关方名称,还可以提取其他种类的关键词,可以用于舆情系统,站内导航等功能。
- 还没有人留言评论。精彩留言会获得点赞!