一种文本的匹配方法、装置、设备及存储介质与流程
本说明书涉及自然语言处理,尤其涉及一种文本的匹配方法、装置、设备及存储介质。
背景技术:
1、目前,对医疗领域中的原始医学文本数据进行编码,以用于在医学候选文本体系中进行术语匹配,从而根据匹配到的候选文本进行学习研究,是医疗领域信息化进程中的重要内容。
2、而在医疗领域中的原始医学文本数据通常分为两类,一类为短文本,如:病历文本中的疾病、症状的名称等概念,这些短文本在医学候选文本体系中通常有含义完全相同的候选文本,只是不同的医护人员的书写习惯、俗称、简写不同而产生的。例如:原始医学文本中的“胃癌”对应的候选文本为“胃恶性肿瘤”。另一类为长文本,这些长文本主要是指医护人员在患者诊疗过程中记录的对某项临床过程或临床概念的详细描述。例如:患者的“手术经过”,也就是患者的手术操作过程的详细记录等。
3、在长文本中,每个词句的重要性是不同的,如果直接将整段文本的词句输入到语言模型中来确定该文本的语义向量,会导致大量无效信息的冗余,从而降低提取的语义向量的准确性较低,进而导致从医学候选文本体系中为长文本确定出与该长文本相匹配的候选文本的准确率较低。
4、因此,如何能够准确地从医学候选文本体系中为长文本确定出与该长文本相匹配的候选文本,则是一个亟待解决的问题。
技术实现思路
1、本说明书提供一种文本的匹配方法、装置、设备及存储介质,以部分的解决现有技术存在的上述问题。
2、本说明书采用下述技术方案:
3、本说明书提供了一种文本的匹配方法,包括:
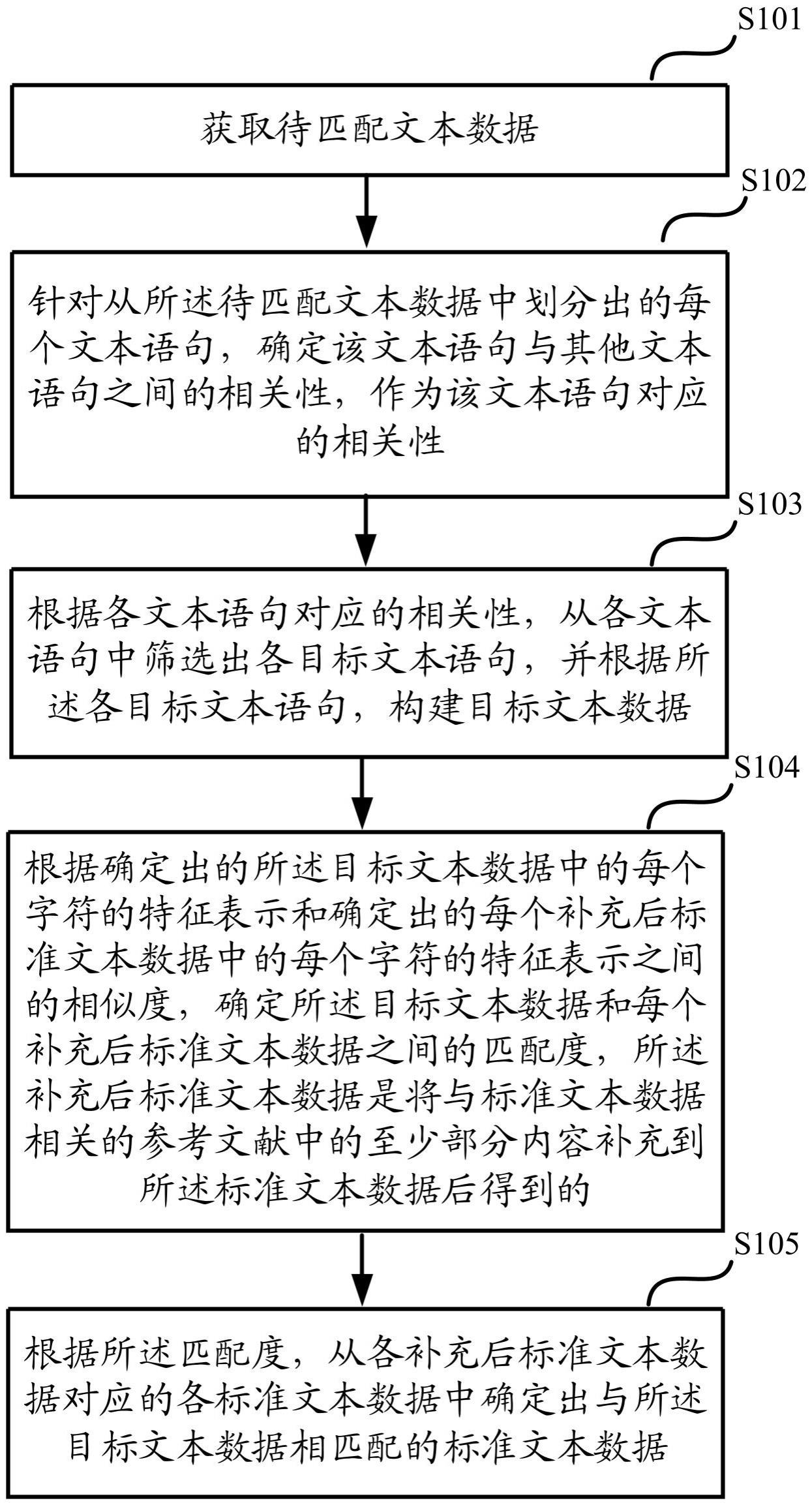
4、获取待匹配文本数据;
5、针对从所述待匹配文本数据中划分出的每个文本语句,确定该文本语句与其他文本语句之间的相关性,作为该文本语句对应的相关性;
6、根据各文本语句对应的相关性,从各文本语句中筛选出各目标文本语句,并根据所述各目标文本语句,构建目标文本数据;
7、根据确定出的所述目标文本数据中的每个字符的特征表示和确定出的每个补充后标准文本数据中的每个字符的特征表示之间的相似度,确定所述目标文本数据和每个补充后标准文本数据之间的匹配度,所述补充后标准文本数据是将与标准文本数据相关的参考文献中的至少部分内容补充到所述标准文本数据后得到的;
8、根据所述匹配度,从各补充后标准文本数据对应的各标准文本数据中确定出与所述目标文本数据相匹配的标准文本数据。
9、可选地,针对从所述待匹配文本数据中划分出的每个文本语句,确定该文本语句与其他文本语句之间的相关性,作为该文本语句对应的相关性,具体包括:
10、对所述待匹配文本数据进行分析,确定出所述待匹配文本数据包含的每个文本语句,并通过在所述待匹配文本数据中插入指定的分隔符,从所述待匹配文本数据中划分出各文本语句;
11、针对从所述待匹配文本数据中划分出的每个文本语句,确定该文本语句与其他文本语句之间的相关性,作为该文本语句对应的相关性。
12、可选地,根据各文本语句对应的相关性,从各文本语句中筛选出各目标文本语句,具体包括:
13、针对所述待匹配文本数据中包含的每个文本语句,生成该文本语句包含的每个字符以及分隔符的初始特征表示,通过多轮优化迭代,根据所述分隔符的所述初始特征表示与该文本语句包含的每个字符的所述初始特征表示之间的注意力权重,对该文本语句包含的每个字符以及分隔符的初始特征表示进行优化,得到该文本语句包含的每个字符以及分隔符的优化后特征表示,所述初始特征表示用于表征所述字符本身、所述字符在该文本语句中的位置、所述字符在所述待匹配文本数据中的位置;其中,
14、针对每轮优化迭代,确定该轮优化迭代中该文本语句包含的每个字符以及分隔符的基础特征表示,根据该轮优化迭代中该文本语句包含的分隔符以及该文本语句包含的每个字符之间的注意力权重,对该文本语句包含的分隔符的基础特征表示以及该文本语句包含的每个字符的基础特征表示进行优化,得到该轮优化迭代后该文本语句包含的每个字符的优化后特征表示以及该文本语句包含的分隔符的优化后特征表示,直到满足预设的终止条件为止,所述基础特征表示是将该文本语句包含的每个字符以及分隔符的初始特征表示优化迭代至上一轮后得到的;
15、根据该文本语句包含的每个字符以及分隔符的优化后特征表示,确定该文本语句的特征表示;
16、根据各文本语句对应的相关性,以及各文本语句的特征表示,从各文本语句中筛选出各目标文本语句。
17、可选地,根据各文本语句对应的相关性,以及各文本语句的特征表示,从各文本语句中筛选出各目标文本语句,具体包括:
18、针对所述待匹配文本数据中包含的每个文本语句,根据该文本语句与其他文本语句之间的相关性,确定该文本语句与其他文本语句之间的注意力权重,并根据该文本语句与其他文本语句之间的注意力权重,对该文本语句的特征表示进行优化,得到该文本语句的优化后特征表示;
19、根据该文本语句的优化后特征表示,确定出该文本语句对应的重要性权重,判断该文本语句对应的重要性权重是否超过预设阈值;
20、若是,则确定该文本语句为目标文本语句。
21、可选地,根据确定出的所述目标文本数据中的每个字符的特征表示和确定出的每个补充后标准文本数据中的每个字符的特征表示之间的相似度,确定所述目标文本数据和每个补充后标准文本数据之间的匹配度,具体包括:
22、通过预设的语言表征模型,提取出所述目标文本数据中的每个字符的特征表示,以及提取出每个补充后标准文本数据中的每个字符的特征表示;
23、确定出所述目标文本数据中的每个字符的特征表示和确定出的每个补充后标准文本数据中的每个字符的特征表示之间的相似度,以得到相似度矩阵;
24、将所述目标文本数据中的每个字符的特征表示与所述相似度矩阵进行融合,得到所述目标文本数据对应的特征表示;以及,
25、针对每个补充后标准文本数据,将该补充后标准文本数据中的每个字符的特征表示与所述相似度矩阵进行融合,得到该补充后标准文本数据对应的特征表示;
26、根据所述目标文本数据对应的特征表示和每个补充后标准文本数据对应的特征表示,确定所述目标文本数据和每个补充后标准文本数据之间的匹配度。
27、可选地,根据所述目标文本数据对应的特征表示和每个补充后标准文本数据对应的特征表示,确定所述目标文本数据和每个补充后标准文本数据之间的匹配度,具体包括:
28、将所述目标文本数据对应的特征表示和每个补充后标准文本数据对应的特征表示输入到预先训练的匹配度确定模型中,以通过所述匹配度确定模型,确定出所述目标文本数据和每个补充后标准文本数据之间的匹配度。
29、可选地,训练所述匹配度确定模型,具体包括:
30、获取历史文本数据以及所述历史文本数据对应的各补充后标准文本数据;
31、将所述历史文本数据对应的特征表示和所述历史文本数据对应的每个补充后标准文本数据对应的特征表示输入到匹配度确定模型中,以通过所述匹配度确定模型,确定出所述历史文本数据和所述历史文本数据对应的每个补充后标准文本数据之间的匹配度;
32、从所述历史文本数据对应的各补充后标准文本数据中,任意选取出两个补充后标准文本数据,并根据所述历史文本数据和该两个补充后标准文本数据中的每个补充后标准文本数据之间的匹配度,确定该两个补充后标准文本数据之间的排列顺序;
33、以最小化确定出的该两个标准文本数据之间的排列顺序,和该两个补充后标准文本数据之间实际对应的排列顺序之间的偏差为优化目标,对所述匹配度确定模型进行训练。
34、本说明书提供了一种文本的匹配装置,包括:
35、获取模块,用于获取待匹配文本数据;
36、筛选模块,用于针对从所述待匹配文本数据中划分出的每个文本语句,确定该文本语句与其他文本语句之间的相关性,作为该文本语句对应的相关性;
37、数据确定模块,用于根据各文本语句对应的相关性,从各文本语句中筛选出各目标文本语句,并根据所述各目标文本语句,构建目标文本数据;
38、匹配度确定模块,用于根据确定出的所述目标文本数据中的每个字符的特征表示和确定出的每个补充后标准文本数据中的每个字符的特征表示之间的相似度,确定所述目标文本数据和每个补充后标准文本数据之间的匹配度,所述补充后标准文本数据是将与标准文本数据相关的参考文献中的至少部分内容补充到所述标准文本数据后得到的;
39、匹配模块,用于根据所述匹配度,从各补充后标准文本数据对应的各标准文本数据中确定出与所述目标文本数据相匹配的标准文本数据。
40、本说明书提供了一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述文本的匹配方法。
41、本说明书提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述文本的匹配方法。
42、本说明书采用的上述至少一个技术方案能够达到以下有益效果:
43、在本说明书提供的文本的匹配方法,首选获取待匹配文本数据,针对从待匹配文本数据中划分出的每个文本语句,确定该文本语句与其他文本语句之间的相关性,作为该文本语句对应的相关性,从而根据各文本语句对应的相关性,从各文本语句中筛选出各目标文本语句,并根据各目标文本语句,构建目标文本数据,进而根据确定出的目标文本数据中的每个字符的特征表示和确定出的每个补充后标准文本数据中的每个字符的特征表示之间的相似度,确定目标文本数据和每个补充后标准文本数据之间的匹配度,其中,补充后标准文本数据是将与标准文本数据相关的参考文献中的至少部分内容补充到标准文本数据后得到的,最后根据匹配度,从各补充后标准文本数据对应的各标准文本数据中确定出与目标文本数据相匹配的标准文本数据。
44、从上述方法中可以看出,可以对待匹配文本数据中包含的各文本语句进行筛选,以对待匹配文本数据进行提炼,得到目标文本数据,并且,可以通过将与标准数据相关的参考文献中的至少部分内容补充到标准文本数据中,从而可以根据提炼出的目标文本数据从各补充后标准文本数据对应的标准文本数据中筛选出与目标文本数据相匹配的各标准文本数据,进而可以提升筛选出的各标准文本数据的准确性。
- 还没有人留言评论。精彩留言会获得点赞!