一种基于相似度计算的元数据字段中文名补全方法、存储介质及系统与流程
本发明涉及数据处理,特别涉及一种基于相似度计算的元数据字段中文名补全方法、存储介质及系统。
背景技术:
1、数据平台的元数据模块中,存在部分元数据字段具有英文名但缺少中文名的情况,导致这些元数据字段的使用场景及价值难以确定,故需对这些元数据字段进行中文名补全。元数据字段缺少中文名的原因一般是英文名错录入为非英文词汇而无法翻译成中文名。传统的元数据字段中文名补全方法是通过人工方式梳理需补全中文名的元数据字段的英文名资料,先人工将英文名匹配为英文词汇再对应补全中文名,这涉及大量线下的元数据文档资料,需投入大量的人力资源成本和时间,并且人工梳理容易出错导致补全的元数据字段中文名不准确,进而影响元数据字段的使用与分析。
技术实现思路
1、本发明要解决的技术问题是如何便捷准确地补全元数据字段的中文名。
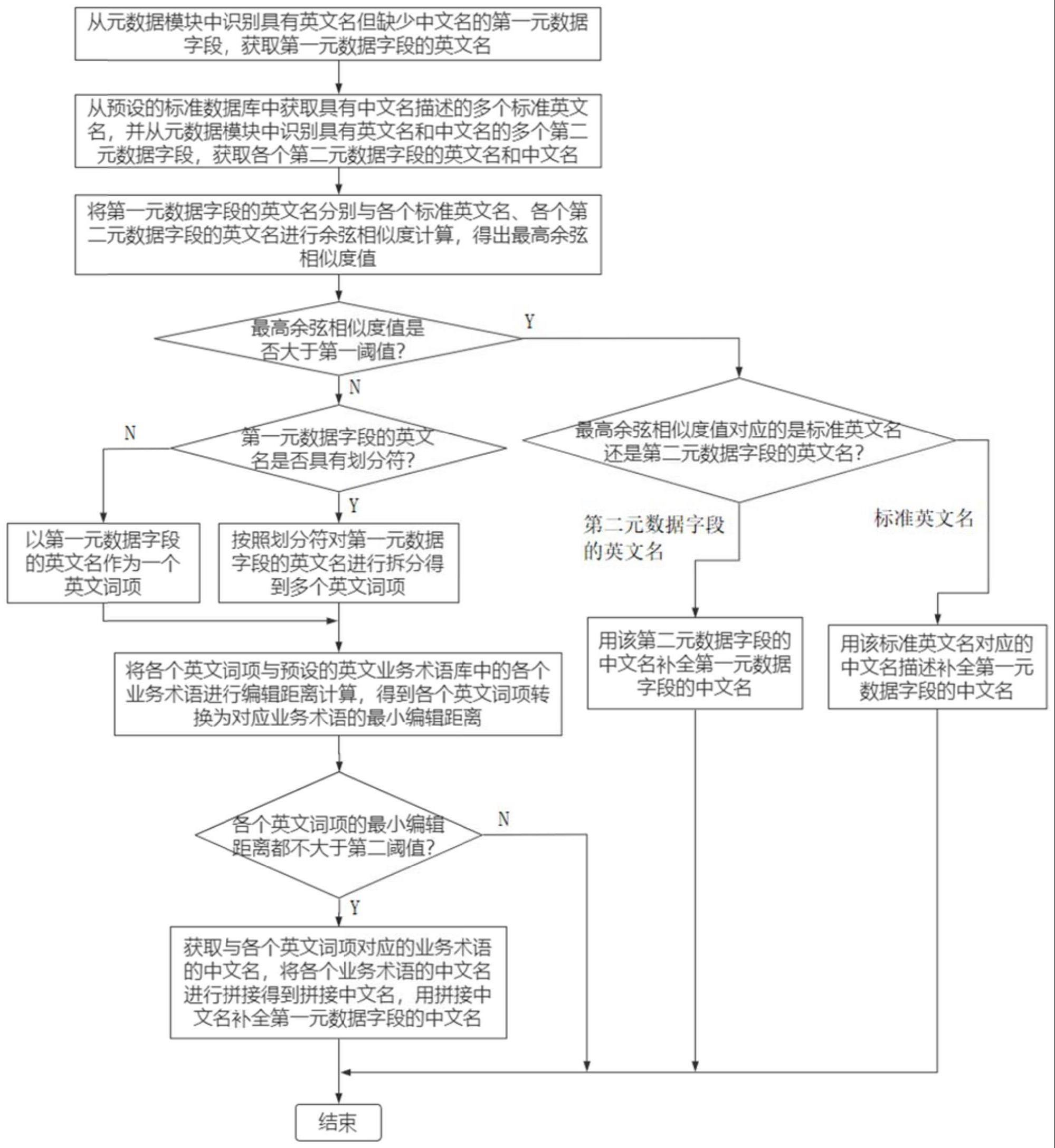
2、为解决上述技术问题,本发明提供一种基于相似度计算的元数据字段中文名补全方法,包括如下步骤:
3、a.从元数据模块中识别具有英文名但缺少中文名的第一元数据字段,获取所述第一元数据字段的英文名;
4、b.从预设的标准数据库中获取具有中文名描述的多个标准英文名,并从所述元数据模块中识别具有英文名和中文名的多个第二元数据字段,获取各个第二元数据字段的英文名和中文名;
5、c.将所述第一元数据字段的英文名分别与各个标准英文名、各个第二元数据字段的英文名进行余弦相似度计算,得出最高余弦相似度值;
6、d.判断所述最高余弦相似度值是否大于第一阈值,若大于则执行下述步骤e,若不大于则执行下述步骤f、g;
7、e.识别所述最高余弦相似度值对应的是标准英文名还是第二元数据字段的英文名,若是标准英文名则用该标准英文名对应的中文名描述补全所述第一元数据字段的中文名,若是第二元数据字段的英文名则用该第二元数据字段的中文名补全所述第一元数据字段的中文名;
8、f.识别所述第一元数据字段的英文名是否具有划分符,若有则按照所述划分符对所述第一元数据字段的英文名进行拆分得到多个英文词项,若没有则以所述第一元数据字段的英文名作为一个英文词项;
9、g.将各个英文词项与预设的英文业务术语库中的各个业务术语进行编辑距离计算,得到各个英文词项转换为对应业务术语的最小编辑距离,若各个英文词项的最小编辑距离都不大于第二阈值,则执行下述步骤h,若存在至少一个英文词项的最小编辑距离大于第二阈值,则不执行下述步骤h;
10、h.获取与各个英文词项对应的业务术语的中文名,将各个业务术语的中文名进行拼接得到拼接中文名,用所述拼接中文名补全所述第一元数据字段的中文名。
11、优选地,所述步骤c中,先将第一元数据字段的英文名、标准英文名与第二元数据字段的英文名转换为字符串向量,再通过计算两个字符串向量夹角的余弦值来得到余弦相似度值。
12、优选地,所述步骤c中,将第一元数据字段的英文名、标准英文名与第二元数据字段的英文名转换为字符串向量,具体先将第一元数据字段的英文名、标准英文名与第二元数据字段的英文名进行分词操作,再列出所有分词,然后计算第一元数据字段的英文名、标准英文名与第二元数据字段的英文名的词频,然后基于各个分词的词频得出对应的字符串向量。
13、优选地,所述步骤c中,余弦相似度计算的具体公式为:
14、
15、其中,cos(θ)表示两个字符串向量x、y之间的夹角余弦值,等价于两个字符串向量x、y的余弦相似度值;x表示第一元数据字段的英文名的字符串向量,y表示标准英文名或第二元数据字段的英文名的字符串向量,xi表示第一元数据字段的英文名的字符串向量中的字符,yi表示标准英文名或第二元数据字段的英文名的字符串向量中的字符,n表示字符串向量中的字符数量。
16、优选地,所述步骤d中,所述第一阈值为90%。
17、优选地,所述步骤f中,所述划分符为下划线。
18、优选地,所述步骤g中,编辑距离计算的算法具体为:
19、
20、其中,leva,b(i,j)表示字符串a的前i个字符与字符串b的前j个字符的编辑距离,字符串a和字符串b分别指代英文词项和业务术语;max(i,j)表示i与j这两者当中的最大值;min(i,j)表示i与j这两者当中的最小值;表示leva,b(i-1,j)+1、leva,b(i,j-1)+1、leva,b(i-1,j-1)+1(a≠b)这三者当中的最小值,其中leva,b(i-1,j)+1、leva,b(i,j-1)+1、leva,b(i-1,j-1)+1(a≠b)分别表示对字符串a或b执行删除、插入、替换操作;1(a≠b)是指示函数,其含义是指当a与b不相同时该指示函数为1,否则为0。
21、优选地,所述步骤g中,所述第二阈值为2。
22、本发明还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上任一项所述的元数据字段中文名补全方法中的步骤。
23、本发明还提供一种基于相似度计算的元数据字段中文名补全系统,包括相互连接的计算机可读存储介质和处理器,计算机可读存储介质如上所述。
24、本发明具有以下有益效果:本发明在识别具有英文名但缺少中文名的第一元数据字段之后,将第一元数据字段的英文名分别与各个标准英文名、各个第二元数据字段的英文名进行余弦相似度计算,得出最高余弦相似度值,若该最高余弦相似度值大于第一阈值则用对应的中文名补全第一元数据字段的中文名,若该最高余弦相似度值不大于第一阈值则对第一元数据字段的英文名进行拆分得到多个英文词项,再将各个英文词项输入到预设的英文业务术语库中进行匹配,得到分别对应各个英文词项的业务术语,然后将各个英文词项与对应的业务术语进行文本编辑距离计算,若各个英文词项的最小编辑距离都不大于第二阈值则获取与各个英文词项对应的业务术语的中文名并将各个业务术语的中文名进行拼接得到拼接中文名,然后用拼接中文名补全第一元数据字段的中文名。在此过程中无需人工梳理需补全中文名的元数据字段的英文名资料,节省人力资源成本和时间,并能避免人工梳理导致的容易出错问题。
技术特征:
1.一种基于相似度计算的元数据字段中文名补全方法,其特征是,包括如下步骤:
2.根据权利要求1所述的基于相似度计算的元数据字段中文名补全方法,其特征是,所述步骤c中,先将第一元数据字段的英文名、标准英文名与第二元数据字段的英文名转换为字符串向量,再通过计算两个字符串向量夹角的余弦值来得到余弦相似度值。
3.根据权利要求2所述的基于相似度计算的元数据字段中文名补全方法,其特征是,所述步骤c中,将第一元数据字段的英文名、标准英文名与第二元数据字段的英文名转换为字符串向量,具体先将第一元数据字段的英文名、标准英文名与第二元数据字段的英文名进行分词操作,再列出所有分词,然后计算第一元数据字段的英文名、标准英文名与第二元数据字段的英文名的词频,然后基于各个分词的词频得出对应的字符串向量。
4.根据权利要求3所述的基于相似度计算的元数据字段中文名补全方法,其特征是,所述步骤c中,余弦相似度计算的具体公式为:
5.根据权利要求1所述的基于相似度计算的元数据字段中文名补全方法,其特征是,所述步骤d中,所述第一阈值为90%。
6.根据权利要求1所述的基于相似度计算的元数据字段中文名补全方法,其特征是,所述步骤f中,所述划分符为下划线。
7.根据权利要求1所述的基于相似度计算的元数据字段中文名补全方法,其特征是,所述步骤g中,编辑距离计算的算法具体为:
8.根据权利要求7所述的基于相似度计算的元数据字段中文名补全方法,其特征是,所述步骤g中,所述第二阈值为2。
9.一种计算机可读存储介质,其上存储有计算机程序,其特征是,所述计算机程序被处理器执行时实现如权利要求1至8任一项所述的元数据字段中文名补全方法中的步骤。
10.一种基于相似度计算的元数据字段中文名补全系统,包括相互连接的计算机可读存储介质和处理器,其特征是,计算机可读存储介质如权利要求9所述。
技术总结
本发明提供一种基于相似度计算的元数据字段中文名补全方法、存储介质及系统,该方法包括:将第一元数据字段的英文名分别与各个标准英文名、各个第二元数据字段的英文名进行余弦相似度计算,若最高余弦相似度值大于第一阈值则用对应的中文名描述补全第一元数据字段的中文名,若不大于则对第一元数据字段的英文名进行拆分得到多个英文词项,将其与预设的业务术语进行编辑距离计算,若各个英文词项的最小编辑距离都不大于第二阈值,则将对应的各个业务术语的中文名进行拼接得到拼接中文名来补全第一元数据字段的中文名。在此过程中无需人工梳理需补全中文名的元数据字段的英文名资料,节省人力资源成本和时间,并能避免人工梳理导致的容易出错问题。
技术研发人员:邹文景,徐欢,杨秋勇,段琳,张冠豫
受保护的技术使用者:云南电网有限责任公司信息中心
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!