利用生成网络对低光照图像增强的方法、生成网络的训练方法及设备与流程
本发明涉及图像处理领域,更具体地,本发明涉及一种利用生成网络对低光照图像增强的方法、生成网络的训练方法及设备。
背景技术:
1、低光照图像是指在低照射度条件下获取到的图像,其质量较低,辨识性能差,含有大量噪声,难以辨别其中的细节,使用价值较低。低光照图像由于不充分的光照导致较低的视觉质量,在对低光照图像进行应用或处理时,影响诸多计算机视觉系统的性能。低光照增强是指对低光照图像进行处理的过程,目的在于提升低光环境下所采集图像的感知质量,使其基本达到充足光照图像的视觉感知效果。
2、针对低光照图像增强的方案包括:传统图像方法和基于深度学习的方法,其中,传统图像方法包括基于he直方图均衡化的方法和基于retinex理论模型的方法。
3、he直方图均衡化理论认为,常规光照强度图像的三通道rgb像素值在整个动态范围上是等概率出现的,除了个别像素值较为突出之外,整个三通道rgb像素值分布近似于均匀分布,这样的图像具备较大的色彩动态范围和较高的对比度。基于此,在得到输入图像的直方图信息后,可以通过一个变换函数作用在输入图像上,使得原始输入图像三通道rgb像素分布更接近于均匀分布,从而完成he直方图均衡化,实现低光照图像增强。但是该方法增强的图像的某些区域会被过度增强,并且生成图像有很多噪点。
4、retinex理论是以物体颜色恒定性为准则,认为物体的色彩是由物体对不同波段光线即不同波段呈现的颜色不同的反射能力来决定的,而不是由反射光线强度来决定的,具有颜色恒定性。retinex理论的基本假设是:原始图像,是由图像光照成分和图像反射率成分的乘积。基于retinex理论的图像增强方法是从原始图像成分中估计出光照成分,从而分解出图像反射率成分,该方法通常可以对不是特别暗的图像进行一定程度自适应的增强。但是retinex理论先验地将图像反射率成分作为增强结果不是很合理,尤其是不同的环境光线条件下,这样的先验假可能导致不切实际的增强,比如特征细节的失真和色彩的错误。而且,retinex理论模型中常常忽视噪声的影响,随之而来的一个问题是这些噪声在增强后的图像中被放大。
5、近年来,基于深度学习的算法在低光照图像增强任务上得到了诸多应用。基于深度学习的低光照图像增强的解决方法主要涉及:有监督学习(supervised learning,sl),无监督学习(unsupervised learning,ul)。但是,在实际场景中,由于很难获得同一场景下低光照和充足光照的成对图像,导致有监督学习在低光照图像增强方面的应用受到一定限制。对于无监督学习,其泛化能力有限并且仍然存在网络不稳定、网络结构复杂、学习效率低下、增强后的图像局部细节不真实等问题。
6、基于此,低光照图像增强的技术有待进一步改进。
技术实现思路
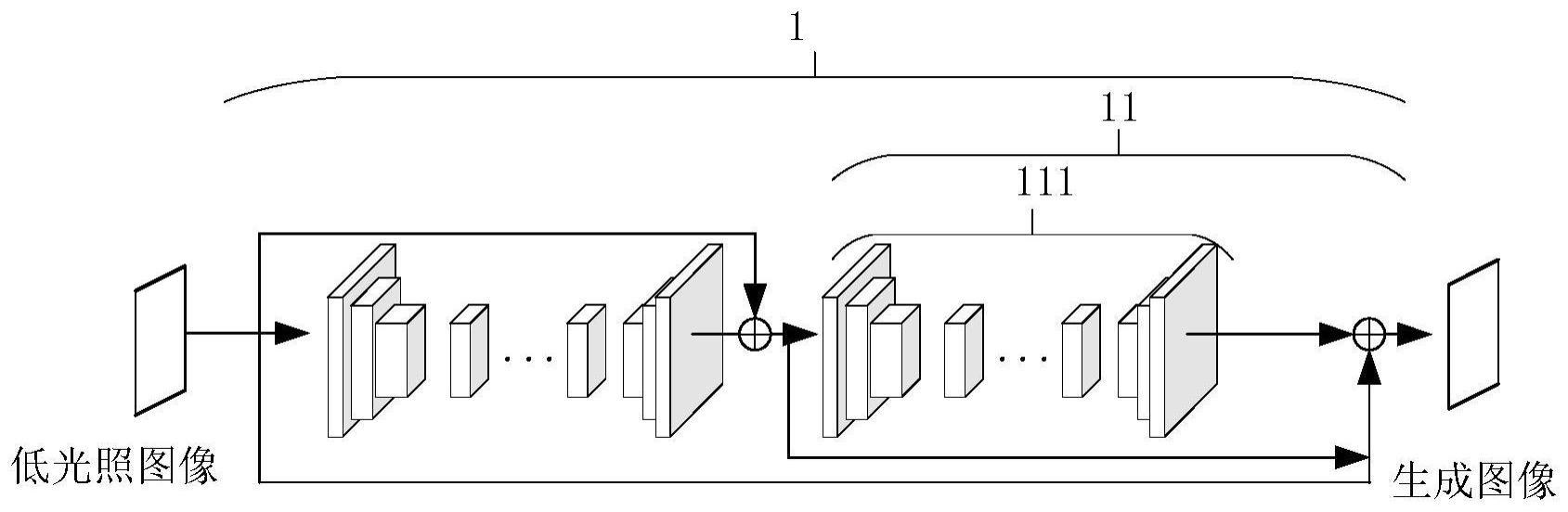
1、为了解决上述低光照图像增强方法中存在的问题,本发明提供了一种利用生成网络对低光照图像增强的方法,包括,将低光照图像输入生成网络1;所述生成网络1增强所述低光照图像,得到生成图像;所述生成网络1输出所述生成图像;所述生成网络1采用残差结构,所述生成网络1的主分支生成低光照图像与生成图像之间的残差,所述生成网络1的捷径分支将低光照图像传输至所述生成网络1的主分支的输出端与所述残差相加,得到生成图像;其中,所述生成网络1的主分支为级联设置的至少两个残差学习单元11,各残差学习单元逐步递进生成所述残差。
2、根据本发明的一个实施方式,残差学习单元11采用残差结构,所述残差学习单元11的主分支为生成器111,所述残差学习单元11的捷径分支连接生成器111的输入端和输出端。
3、根据本发明的一个实施方式,生成网络1还包括通道注意力分支,通道注意力分支连接第一级生成器的输入端和最后一级生成器111的输出端;所述通道注意力分支将低光照图像的rgb三通道取出后取反,再分别和最后一级生成器111的输出按通道顺序依次相乘。
4、根据本发明的一个实施方式,生成器111采用编码器-残差块-解码器架构,包括下采样层1111、残差块1112和上采样层1113和降维层1114,编码器和解码器对称设置。
5、根据本发明的一个实施方式,生成器111包括三个下采样层1111,九个残差块1112,两个上采样层1113和一个降维层1114;三个下采样层1111构成解码器,两个上采样层1113和一个降维层1114构成编码器;所述下采样层1111为cbr结构;所述上采样层1113为tbr结构。
6、根据本发明的另一方面,提供了一种基于无监督生成对抗网络训练生成网络的方法,包括,获取低光照图像和充足光照图像作为训练样本,低光照图像和充足光照图像的语义内容无需严格一致;将所述低光照图像输入生成网络,得到生成图像;将所述生成图像和充足光照图像输入判别网络,得到判别结果;迭代调整生成网络或判别网络的参数,直至生成网络和判别网络达到纳什均衡;其中,基于低光照图像与生成图像之间的语义一致性损失,生成图像与充足光照图像之间的对抗损失调整生成网络的参数;基于对抗损失调整判别网络的参数;其中,所述生成网络采用残差结构,所述生成网络1的捷径分支连接生成网络1的输入端和输出端;所述生成网络1的主分支为级联设置的至少两个残差学习单元11;所述残差学习单元11采用残差结构,所述残差学习单元11的主分支为生成器111,所述残差学习单元11的捷径分支连接生成器111的输入端和输出端。
7、根据本发明的一个实施方式,采用vgg19特征的一致性维持语义内容不偏移,语义内容一致性损失lossvgg定义如下:
8、
9、wh表示图像的宽度与长度;wi表示宽度方向上的第i个像素点;hj表示长度方向上的第j个像素点;表示输入的低光照图像的vgg特征;表示增强后的生成图像的vgg特征;|| ||2表示l2范数衡量。
10、根据本发明的一个实施方式,对抗损失定义如下:
11、
12、
13、
14、其中,是全局尺度下的判别器的损失函数;是局部尺度下的判别器的损失函数;是全局尺度下生成器的损失函数;是局部尺度下生成器的损失函数;xr~real表示输入图像服从真实图像域的分布;xg~generate表示输入图像服从生成图像域的分布;d表示判别器网络;|| ||2表示l2范数衡量;e表示期望;局部判别器采用平均n个随机子块的判别器结果,n为大于1的整数。
15、根据本发明的一个实施方式,n=6。
16、对于本发明中的生成网络,通过设置通道注意力机制,帮助生成网络从输入中自动关注于需要被增强的区域的信息。通过设置判别网络的局部尺度,使得在对生成网络进行训练时自适应地增强输入的低光照图像中需要被增强的区域。通过生成网络的架构和生成网络的训练过程两方面的设置,增加了生成网络进行图像增强时对需要被增强的区域的侧重,提高生成图像的质量。
17、在本发明中,对于生成网络,通过设置残差结构,分解了生成残差的任务,减少了各生成器的任务,在训练时更容易达到训练目的。通过设置级联结构,每个生成器仅负担部分任务,进一步减轻了生成难度和学习难度。
- 还没有人留言评论。精彩留言会获得点赞!