语言处理方法、训练方法、装置、设备、介质及程序产品与流程
本技术涉及自然语言处理,具体涉及一种语言处理方法、训练方法、装置、设备、介质及程序产品。
背景技术:
1、自然语言处理(natural language processing,nlp)是计算机科学领域与人工智能领域中的一个重要方向,它以语言为对象,利用计算机技术来分析、理解和处理自然语言,应用于机器翻译、自动摘要、观点提取、文本分类、问题回答、文本语义对比等方面。
2、自然语言处理任务的实现前提是使得计算机能够理解文本的语义,即需要对文本的语义进行表征,然而在目前的相关技术中,通常利用预训练的语言模型来对文本进行语义的表征,然而,这类语言模型的表征存在各向异性的问题,即表征位于表示空间的一个狭小子集中,不太具有区分性,捕获不同文本的语义差异的能力较差,进而导致自然语言处理的效果较差。
技术实现思路
1、本技术实施例提供一种语言处理方法、模型训练方法、语言处理装置、电子设备、计算机可读存储介质以及计算机程序产品,可以提高语言处理模型的语言处理能力。
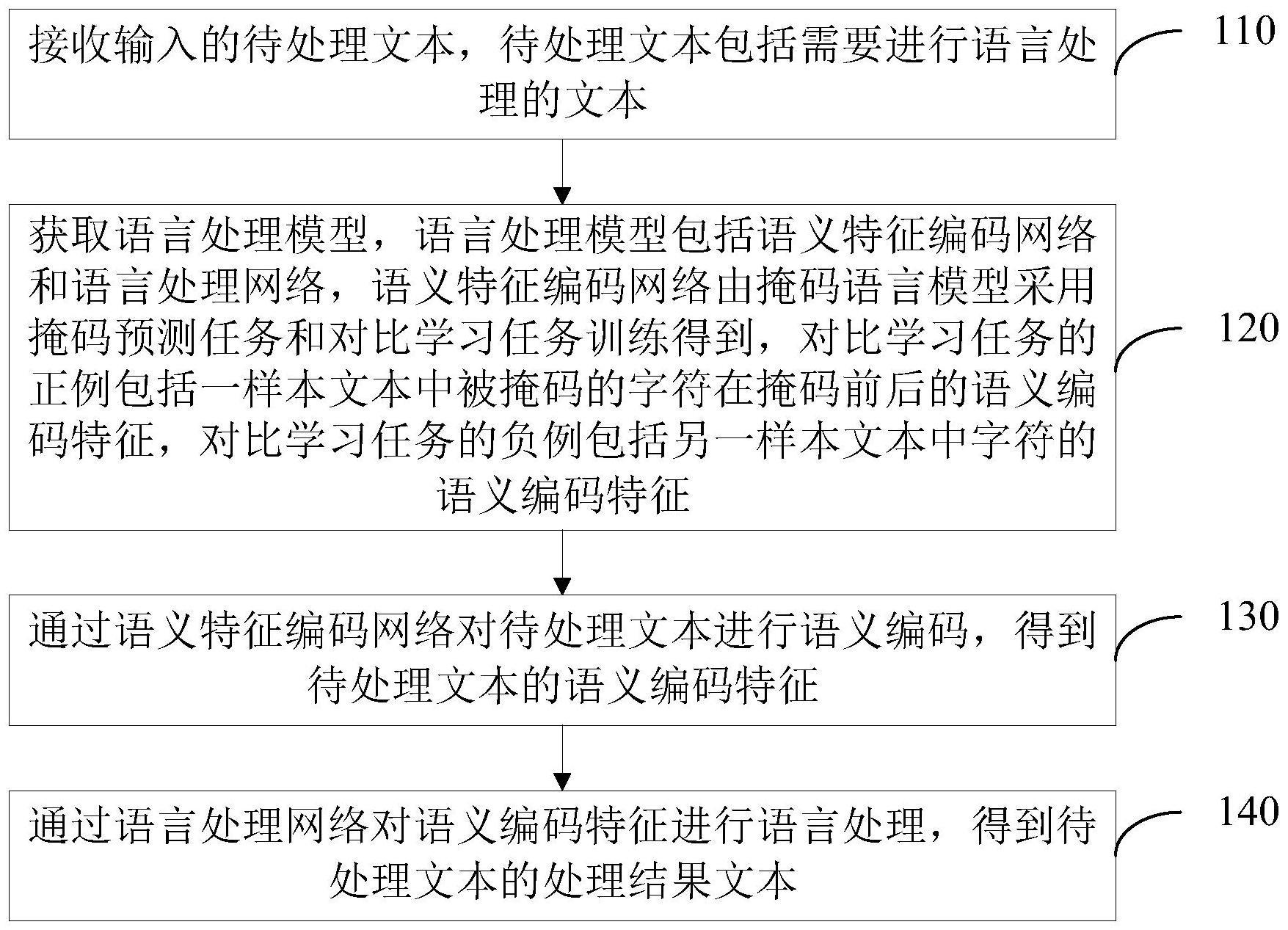
2、第一方面,本技术提供的语言处理方法,包括:
3、接收输入的待处理文本,待处理文本包括需要进行语言处理的文本;
4、获取语言处理模型,语言处理模型包括语义特征编码网络和语言处理网络;
5、通过语义特征编码网络对待处理文本进行语义编码,得到待处理文本的语义编码特征;
6、通过语言处理网络对语义编码特征进行语言处理,得到待处理文本的处理结果文本;
7、其中,语义特征编码网络由掩码语言模型采用掩码预测任务和对比学习任务训练得到,对比学习任务的正例包括一样本文本中被掩码的字符在掩码前后的语义编码特征,对比学习任务的负例包括另一样本文本中字符的语义编码特征。
8、第二方面,本技术提供的语言处理装置,包括:
9、文本获取模块,用于接收输入的待处理文本,待处理文本包括需要进行语言处理的文本;
10、模型获取模块,用于获取语言处理模型,语言处理模型包括语义特征编码网络和语言处理网络;
11、语义编码模块,用于通过语义特征编码网络对待处理文本进行语义编码,得到待处理文本的语义编码特征;
12、语言处理模块,用于通过语言处理网络对语义编码特征进行语言处理,得到待处理文本的处理结果文本;
13、其中,语义特征编码网络由掩码语言模型采用掩码预测任务和对比学习任务训练得到,对比学习任务的正例包括一样本文本中被掩码的字符在掩码前后的语义编码特征,对比学习任务的负例包括另一样本文本中字符的语义编码特征。
14、在一可选的实施例中,语言处理装置还包括模型训练模块,用于获取掩码语言模型,掩码语言模型包括语义特征编码网络和掩码预测网络;获取对应掩码预测任务的n个原始文本,并对n个原始文本进行掩码处理,得到n个第一类样本文本;通过语义特征编码网络分别对n个原始文本和n个第一类样本文本进行语义编码,得到n个原始文本的n个第一样本语义编码特征、n个第一类样本文本的n个第二样本语义编码特征;通过掩码预测网络对n个第二样本语义编码特征进行掩码预测,得到n个预测文本;根据任一第一类样本文本对应的第一样本语义编码特征和第二样本语义编码特征,以及其它第一类样本文本对应的第一样本语义编码特征和第二样本语义编码特征,获取对比学习任务的对比损失;根据n个预测文本和n个原始文本,获取掩码预测任务的预测损失;根据对比损失和预测损失,对语义特征编码网络和掩码预测网络的网络参数进行联合更新,直至满足第一预设更新停止条件。
15、在一可选的实施例中,模型训练模块用于确定目标掩码比例,并根据目标掩码比例确定n个原始文本的待掩码字符;将n个原始文本中的待掩码字符替换为预设掩码字符,得到n个第一类样本文本。
16、在一可选的实施例中,模型训练模块用于选取n个第一类样本文本中的任一第一类样本文本,并从选取的第一类样本文本所对应的原始文本中选取目标待掩码字符;根据选取的第一类样本文本所对应的第一样本语义编码特征,确定目标待掩码字符的字符编码特征;根据选取的第一类样本文本所对应的第二样本语义编码特征,确定目标待掩码字符对应的预设掩码字符的正例字符编码特征;从其它第一类样本文本及其它第一类样本文本对应的原始文本中选取负例字符,并根据其它第一类样本文本对应的第一样本语义编码特征和第二样本语义编码特征,确定负例字符的负例字符编码特征;获取字符编码特征与正例字符编码特征之间的第一相似度,以及字符编码特征与负例字符编码特征之间的第二相似度;根据第一相似度和第二相似度获取对比损失。
17、在一可选的实施例中,模型训练模块用于获取对应对比损失的加权权重,并根据加权权重对对比损失进行加权计算,得到加权损失;融合加权损失和预测损失,得到融合损失;根据融合损失,对语义特征编码网络和掩码预测网络的网络参数进行联合更新,直至满足第一预设更新停止条件。
18、在一可选的实施例中,模型训练模块还用于获取对应不同语言处理类型的第二类样本文本,以及对应第二类样本文本的第一处理结果文本标签;构建对应每一语言处理类型的语言处理网络;针对每一语言处理类型,将对应的第二类样本文本输入语义特征编码网络进行语义编码,得到第三样本语义编码特征,并将第三样本语义编码特征输入对应的语言处理网络进行语言处理,得到第一样本处理结果文本,以及根据第一样本处理结果文本和对应的第一处理结果文本标签,获取每一语言处理类型的语言处理损失;根据每一语言处理类型的语言处理损失,对每一语言处理类型的语言处理网络的网络参数进行更新,直至满足第二预设更新停止条件。
19、在一可选的实施例中,模型获取模块用于确定对应待处理文本的目标语言处理类型;获取目标语言处理类型对应的语言处理网络,以及获取语义特征编码网络;将语义特征编码网络、目标语言处理类型对应的语言处理网络,组合为语言处理模型。
20、第三方面,本技术提供的模型训练方法,包括:
21、获取预训练的语义特征编码网络,语义特征编码网络由掩码语言模型采用掩码预测任务和对比学习任务训练得到,对比学习任务的正例包括一样本文本中被掩码的字符在掩码前后的语义编码特征,对比学习任务的负例包括另一样本文本中字符的语义编码特征;
22、获取对应语言处理任务的o个第三类样本文本,以及对应o个第三类样本文本的o个第二处理结果文本标签;
23、构建对应语言处理任务的语言处理网络;
24、将o个第三类样本文本输入语义特征编码网络进行语义编码,得到o个第四样本语义编码特征;
25、将o个第四样本语义编码特征输入语言处理网络进行语言处理,得到o个第二样本处理结果文本;
26、根据o个第二样本处理结果文本和o个第二处理结果文本标签,获取语言处理损失;
27、根据语言处理损失,对语言处理网络的网络参数进行更新,直至满足第三预设更新停止条件;
28、将满足第三预设更新停止条件的语言处理网络和语义特征编码网络,组合为对应语言处理任务的语言处理模型。
29、第四方面,本技术提供的电子设备,包括存储器和处理器,存储器存储有计算机程序,处理器用于运行存储器内的计算机程序,实现本技术所提供的语言处理方法中的步骤,或者实现本技术所提供的模型训练方法中的步骤。
30、第五方面,本技术提供的计算机可读存储介质,存储有多条指令,该指令适于处理器进行加载,实现本技术所提供的语言处理方法中的步骤,或者实现本技术所提供的模型训练方法中的步骤。
31、第六方面,本技术提供的计算机程序产品,包括计算机程序或指令,该计算机程序或指令被处理器执行时实现本技术所提供的语言处理方法中的步骤,或者实现本技术所提供的模型训练方法中的步骤。
32、本技术中,首先获取到需要进行语言处理的待处理文本,此外还获取语言处理模型,该语言处理模型包括语义特征编码网络和语言处理网络,其中,该语义特征编码网络由掩码语言模型采用掩码预测任务和对比学习任务训练得到,对比学习任务的正例包括一样本文本中被掩码的字符在掩码前后的语义编码特征,对比学习任务的负例包括另一样本文本中字符的语义编码特征。然后,通过语义特征编码网络对待处理文本进行语义编码,得到待处理文本的语义编码特征,并进一步通过语言处理网络对语义编码特征进行语言处理,得到待处理文本的处理结果文本。相较于相关技术,语义特征编码网络在训练阶段采用一样本文本中被掩码的字符在掩码前后的语义编码特征作为正例,能够拉近被掩码字符在掩码前后的语义表征,同时采用另一样本文本中字符的语义编码特征作为负例,使得语义特征编码网络学习的语义表征更具区分性,提升语义特征编码网络的语义表征能力,进而提升由语义特征编码网络结合下游语言处理任务的语言处理网络得到的语言处理模型的语言处理能力。
- 还没有人留言评论。精彩留言会获得点赞!