一种面向机器学习模型的自然公平性测试用例生成方法
本发明涉及一种面向机器学习模型的自然公平性测试用例生成方法,属于机器学习。
背景技术:
1、作为一种新兴的技术工具,机器学习模型在简历筛选、信用评分和医疗诊断等诸多关键决策领域中得到广泛应用。尽管机器学习模型取得了出色的性能表现,但它也可能在无意中引入社会偏见,这违反了软件设计的公平性要求。最近的研究和实践表明,一些机器学习模型可能在性别等敏感属性上表现出歧视性决策。例如,亚马逊使用的招聘模型对男性候选者表现出强烈的偏好,但对女性候选者的简历给出较低的评分。因此,进行详尽的测试来检测机器学习模型的歧视性行为,并且进一步提高机器学习模型的公平性至关重要,这可以缓解机器学习模型在敏感决策领域应用中的公平性问题。
2、为了测试公平性,已有许多研究提出生成违反公平性要求的测试用例,从而揭示机器学习模型的歧视行为。一般来说,现有的研究主要可以分为两类:个人公平和群体公平。个体公平要求对相似的个体做出相似的决定,而群体公平要求对按敏感属性分组的群体给予平等对待。在现有技术中,主要在两阶段生成框架中生成歧视性用例。具体来说,他们首先通过随机抽样或基于梯度的搜索构建一组个体歧视用例作为全局种子;然后进行迭代过程搜索全局种子附近的用例。但是,生成的测试用例的自然性并不令人满意(即生成用例往往偏离原始数据分布),这阻碍了实际应用中机器学习模型的公平性测试。例如,现有方法生成许多年龄为10岁的测试用例来检测用户的驾驶行为,但该年龄段的人群没有独立驾驶机动车的权利。这些测试用例违反了现实世界的约束条件,并可能错误地估计模型的公平性。
3、在专利号为zl 202011403188.6的中国发明专利中,公开了一种深度神经网络模型公平性测试方法,包括获取若干样本,并查询待测试神经网络模型得到各样本的预测结果,利用已知预测结果的样本进行聚类为样本簇,并分别训练替代模型,在每个样本簇上基于对应的替代模型,生成新的种子样本集合,并对取出的种子施加扰动,进而使其在很大概率上变成违反公平性条件的样本,并基于对当前发现的违反公平性的样本施加多次扰动,来发现更多的违反公平性条件的样本,用来充分验证深度神经网络模型公平性。
技术实现思路
1、本发明所要解决的技术问题在于提供一种面向机器学习模型的自然公平性测试用例生成方法。
2、为了实现上述目的,本发明采用以下的技术方案:
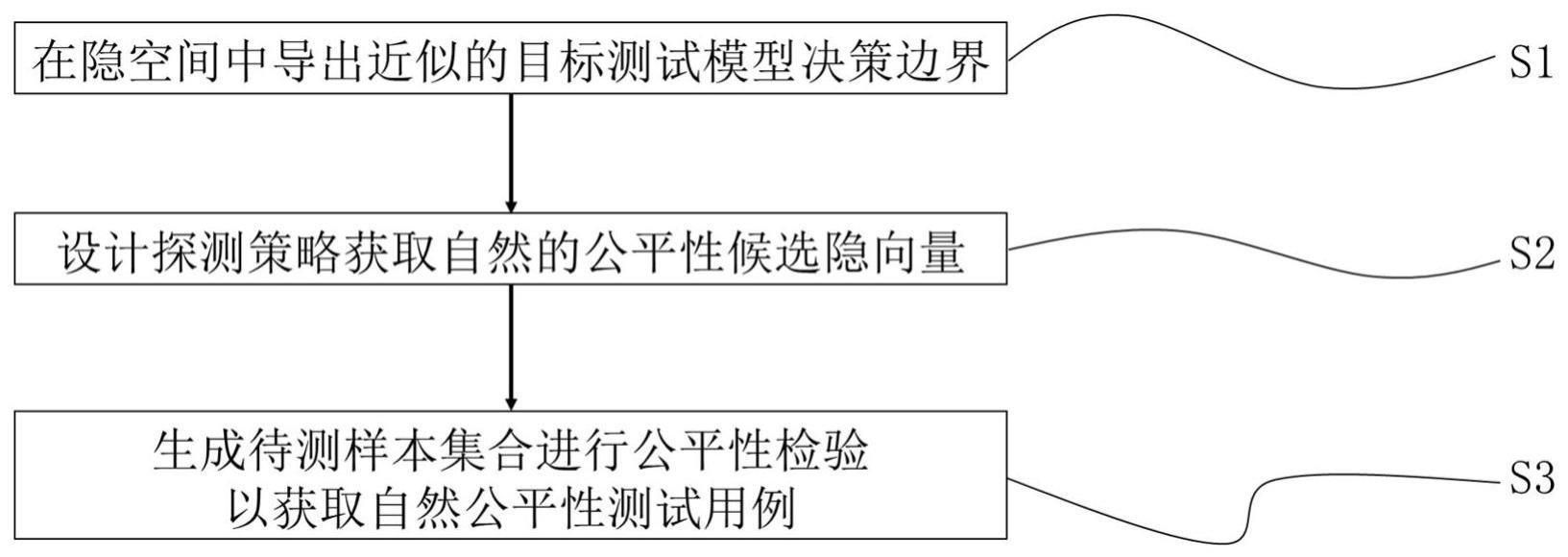
3、一种面向机器学习模型的自然公平性测试用例生成方法,包括如下步骤:
4、模拟机器学习模型在隐空间上的决策过程,通过在隐空间中随机采样隐向量样本,使用生成对抗网络生成在原始数据输入空间的实例样本,并使用机器学习模型对这些实例样本进行预测,构建隐向量样本与预测标签的辅助数据集,并使用线性超平面近似出在隐空间上的代理决策边界;
5、利用机器学习模型在决策边界上的不鲁棒性质,设计隐向量候选者探测策略,首先通过向量运算求解位置在代理决策边界上的隐向量,之后根据设定的步长控制超参数在其两侧各选取一个候选隐向量,构成一个候选者三元组,并重复指定次数的探测过程以构成候选隐向量集合;
6、使用生成对抗网络对候选隐向量集合进行推导生成,得到待测试样本集合,检验机器学习模型在这些测试样本上的表现;当有一个候选者在候选者三元组中被确认为公平性测试用例,则将其加入公平性测试用例集合,并跳出三元组的循环过程去检验下一个三元组,最终构成的公平性测试用例集合即为生成的自然公平性测试用例。
7、其中较优地,在真实数据集上训练生成对抗网络学习原始数据分布;
8、在生成对抗网络的隐空间中随机采样一定数量的隐向量样本,作为隐空间中的初始隐向量样本集合;
9、使用生成对抗网络对采样的隐向量集合进行推导过程,生成在原始输入域上的初始实例样本集合;
10、使用机器学习模型对初始实例样本进行预测得到实例样本对应的标签,构建隐向量与标签的辅助数据集;
11、使用线性超平面区分该辅助数据集,用于近似机器学习模型的决策边界。
12、其中较优地,构造辅助数据集将机器学习模型在原始输入域上的决策空间映射到隐空间上。
13、其中较优地,在辅助数据集上训练一个支持向量机,拟合机器学习模型的决策边界,形式化表述为:
14、h:wtz+b=0
15、其中,w表示该线性超平面的法向量,z代表隐空间中的隐向量,b表示截距。
16、其中较优地,通过如下步骤获取符合自然规律的公平性测试候选隐向量:
17、探测位置处于代理决策边界上的隐向量候选者;
18、探测分别位于代理决策边界两侧的隐向量候选者;
19、生成探测的候选隐向量集合。
20、其中较优地,通过如下步骤探测位置处于代理决策边界上的隐向量候选者:
21、从初始隐向量样本出发,计算移动到代理决策边界上的操作距离,将初始隐向量样本移动到代理决策边界上得到隐向量z0,移动公式如下:
22、
23、其中,是单位法向量,同样的,是单位截距。
24、其中较优地,通过如下步骤探测分别位于代理决策边界两侧的隐向量候选者:
25、在隐向量z0两侧根据设定超参数各选取一个候选隐向量,计算公式如下:
26、z+=z0+λ·wu
27、z-=z0-λ·wu
28、其中,λ为超参数,控制在wu方向上的移动步长;
29、重复上述过程,将生成的候选隐向量按照三元组的形式构成集合。
30、其中较优地,生成三元组待测试样本集合进行三元组公平性测试以获取自然公平性测试用例:
31、使用生成对抗网络对候选隐向量集合进行推导过程,生成在原始输入域上的测试用例样本集合;
32、对测试用例样本进行敏感属性的修改扰动,检验其是否能揭示公平性缺陷,将能揭示公平性缺陷的测试用例加入最终的自然公平性测试用例集合中。
33、其中较优地,通过如下步骤生成三元组待测试样本集合:
34、使用对抗生成网络中的生成器对候选隐向量集合进行推导,输出在原始输入域上的初始数据样本集合用三元组的形式表述如下:
35、
36、其中较优地,通过如下步骤进行三元组公平性测试:
37、通过修改所选的敏感属性的值来检查中的测试用例是否为个体歧视性用例;其中,对每个三元组,一旦(g(z0),g(z+),g(z-)中任意一个候选样本被确定为歧视性用例,将该候选样本添加到个体歧视性用例集合中,并立即停止对该元组中剩余样本的测试;
38、对集合重复上述过程,直到迭代完所有的三元组,最后得到的即为自然公平性测试用例集合。
39、与现有技术相比较,本发明通过构造数据集模拟机器学习模型在隐空间中的决策过程,导出近似的代理决策边界。进而,利用模型在决策边界上的不鲁棒性质,设计隐向量候选者探测策略,在代理决策边界附近生成符合自然规律的公平性测试用例,能帮助我们更好地测试机器学习模型在真实场景下的公平性特点,并有助于提高机器学习模型的公平性和可信性。本发明可以用于结构化数据如表格、非结构化数据如图像场景的自然公平性测试用例生成方法中,具有较好的应用价值和实际效果。
- 还没有人留言评论。精彩留言会获得点赞!