用于小型掩码自动编码器预训练的非对称掩码蒸馏方法与流程
本发明涉及计算机视觉,尤其涉及用于小型掩码自动编码器预训练的非对称掩码蒸馏方法。
背景技术:
1、近年来自监督学习取得了巨大的成功,并超越了许多监督学习的方法。从损坏的图像中恢复原始图像最近被引入作为一种有效的预训练范例。早期的工作采用类似的方法进行图像去噪或图像修复。随着变压器(transformer)在计算机视觉领域的成功,最近的工作尝试将视觉变压器(vision transformer,vit)应用于掩码自动编码器(mae)。随着自然语言处理领域中提出生成任务作为预训练目标的成功,最近工作提出了基于vit的掩码图像建模,它将图像块视为单词。这种简单的掩码和重建框架在图像分类、目标检测、语义分割和动作识别等下游任务中表现出了出色的性能。重建目标可以分为高层特征和低层特征。在高层特征重建中执行两阶段过程,因为重建目标是离散令牌,需要预训练的令牌生成器。在低级重建方面,有工作提出了以定向梯度直方图为重建目标的单阶段预训练方法。mae的重建目标是像素,这项里程碑工作提出了一种非对称自动编码器结构,该结构利用高掩码率来减少计算开销,并使可扩展性成为可能。由于mae出色的可扩展性,最近的工作将mae从图像扩展到视频。视频掩码自动编码器(videomae)将管式掩码策略应用于视频数据,并在transformer块中采用联合时空注意力来提取视频特征,这在人类日常生活数据集(something-in-something v2数据集)上表现出色。
2、掩码自动编码框架仍然存在一些问题。首先,编码器通常对一小部分具有高掩码率的可见标记进行操作(例如图像为75%,视频为90%)。这种高掩码可能会增加预训练任务的难度,并可能鼓励编码器捕获更有用的高级信息以进行重建。这种高掩码率也可能会丢失一些重要和详细的结构信息,导致预训练模型捕获不完整和有偏见的视觉信息。其次,掩蔽自动编码通常需要高容量的vit主干(例如,vit-l和vit-h)来释放掩码预训练的力量。这些大模型在对下游任务进行微调时会产生高计算成本和内存消耗,这种高成本对于视频输入来说尤其严重,因为视频转换器将多个帧作为输入。
3、知识蒸馏是一种压缩模型的有效方法,由hinton等人首次提出。一种常见的蒸馏技术是利用教师模型的分类预测输出作为传递知识的媒介。为了从教师模型那里引入更多的暗知识,引入了温度因子来使软标签与kullback-leibler散度损失对齐。然而,基于分类预测输出的蒸馏方法只能应用于微调模型,这会损害无监督预训练模型的泛化能力。除了利用教师模型的分类预测输出,研究人员还利用模型的中间特征进行特征蒸馏。vitkd将分类预测输出对齐与特征对齐结合使用,并在使用监督信息的微调模型上表现良好。最近的工作已经成功地将特征对齐应用于基于对比学习的自监督学习方法。通过分析优化友好属性得出结论,mae几乎无法通过直接特征蒸馏获益。语言辅助表示的掩码图像预训练(milan)利用对比语言-图像预训练(clip)的高语义信息进行特征对齐,并为mae设计了一种改进的掩码策略。
4、掩码自编码器支持高效的知识蒸馏器(dmae)在学生模型预训练期间采用基于mae的对称掩码方法进行特征对齐蒸馏,并且仅仅只在图像数据集上进行了技术验证。dmae采用的是对称的掩码策略,即教师模型和学生模型应用相同的掩码方式。dmae允许学生模型和教师模型接收对称的未屏蔽图像块,以便可以直接对齐特征,并降低教师模型的计算复杂度。但是教师和学生的相同掩码限制了教师模型从样本中收集更多的上下文信息,并且面临信息泄露的风险。
技术实现思路
1、为解决现有技术中的上述问题中的至少一部分问题,本发明提供一种用于小型掩码自动编码器预训练的非对称掩码蒸馏方法,包括:
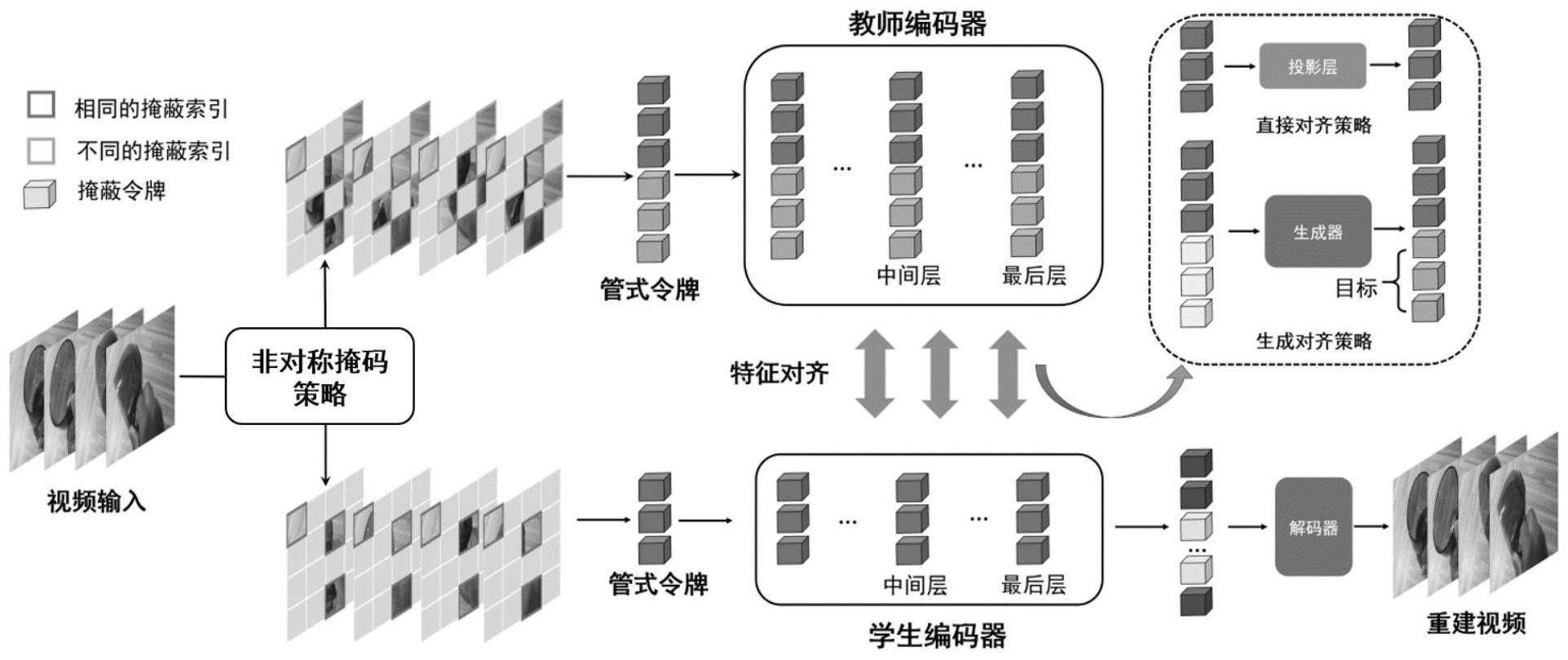
2、对学生编码器和教师编码器的视频输入进行非对称掩码,得到多个管式令牌作为特征输入教师编码器和学生编码器,其中教师编码器的视频输入的掩码率小于学生编码器的视频输入的掩码率;以及
3、进行学生编码器与教师编码器之间的特征对齐。
4、进一步地,多个管式令牌组成输入序列,教师编码器的输入序列的长度大于输入学生编码器的输入序列的长度;以及
5、学生编码器的特征是教师编码器的特征的子集。
6、进一步地,所述对学生编码器和教师编码器的视频输入进行非对称掩码包括:
7、为学生编码器和教师编码器生成掩码矩阵,然后得到学生编码器的可见令牌索引和教师编码器的可见令牌索引其中是学生编码器的令牌索引,是教师编码器的令牌索引,是学生编码器的输入序列的长度,是教师编码器的输入序列的长度,n是整个输入样本的管式令牌个数。
8、进一步地,学生编码器的可见令牌索引是教师编码器的可见令牌索引的子集
9、进一步地,使用串行对齐方法进行学生编码器与教师编码器之间的特征对齐,其中所述串行对齐方法包括顺序进行的直接对齐和生成对齐,其中对于学生编码器和教师编码器共有的特征使用直接对齐来进行特征对齐,对于存在于教师编码器但不存在于学生编码器的特征使用生成对齐来进行特征对齐。
10、进一步地,所述使用串行对齐方法进行学生编码器与教师编码器之间的特征对齐包括:
11、对于学生编码器的特定层l,教师编码器对应的层是l*,学生编码器和教师编码器的特征分别提取为
12、直接对齐的第一步是将投影函数φ(·)应用于学生编码器以对齐教师编码器的特征维度,其中使用了一个线性投影层,获得了学生编码器的投影特征用于直接对齐;以及
13、连续使用学生编码器的投影特征通过生成器来生成特征进行生成对齐。
14、进一步地,所述通过生成器来生成特征包括:
15、其中zm表示掩码令牌,pe为一维位置编码。
16、进一步地,在对齐多层特征时,直接对齐损失函数为:
17、其中φl表示第l层的投影函数,是学生编码器的输入序列的长度,z(p)表示从输入序列中提取的第p个令牌作为特征;以及
18、在对齐多层特征时,生成对齐损失函数为:
19、其中表示第l层的生成器,是教师编码器比学生编码器多输入的序列长度,z(p)表示从输入序列中提取的第p个令牌作为特征。
20、进一步地,还包括在进行特征对齐的同时,解码器重建视频被掩蔽部分的像素值,其中特征对齐任务和重建视频任务的整体损失函数为:ltotal=lrecon+ldir+lgen,其中lrecon是重建视频的损失函数,ldir是直接对齐的损失函数,lgen是生成对齐的损失函数。
21、进一步地,利用并行对齐方法代替串行对齐方法,其中并行对齐包括同时进行的直接对齐和生成对齐,直接对齐过程中使用线性投影层获得了学生编码器的特征映射进行对齐,生成对齐过程中使用线性投影层获得了学生编码器的特征映射,并通过这些特征映射生成特征,以对齐教师编码器独有的特征,直接对齐的线性投影层与生成对齐的线性投影层的参数不共享。
22、本发明还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序在被处理器执行时执行根据上述方法的步骤。
23、本发明至少具有下列有益效果:本发明公开的一种用于小型掩码自动编码器预训练的非对称掩码蒸馏方法,对于学生编码器和教师编码器应用非对称掩码方案,教师编码器的视频输入的掩码率小于学生编码器的视频输入的掩码率,学生编码器的未屏蔽图像块是教师编码器的子集。这种不对称掩码蒸馏在预训练过程中为学生保持了重建任务的难度,也允许教师接收更多可以传递给学生的上下文信息。
24、在学生编码器和教师编码器之间应用非对称掩码方案,因此特征分为两种类型,一种对学生编码器和教师编码器都具有的特征,另一种只教师编码器具有的特征。使用串行对齐方法来对齐这两种类型的特征,对于第一类特征,使用直接对齐方法进行对齐,对于第二类特征,将学生编码器的投影特征提供给类似解码器的生成器来生成特征,将生成的特征与仅教师编码器可见的特征对齐。生成器的输入序列长度是基于教师编码其可见令牌的数量,这意味着学生编码器不需要像解码器那样生成所有掩码令牌。由于在生成特征时加入了位置编码,生成器保证了学生的预测能力,同时减少了计算开销。这种串行对齐可以适当降低生成对齐任务的难度。
25、利用该非对称掩码蒸馏方法可以构建更高效和有效的小型模型,这些模型可以有效地适应下游任务,小型模型相对于大模型的计算成本和内存消耗均有降低。
- 还没有人留言评论。精彩留言会获得点赞!