一种基于BIM技术的深基坑模型快速建模方法及系统与流程
本发明涉及数据处理,具体涉及一种基于bim技术的深基坑模型快速建模方法及系统。
背景技术:
1、现有的通过bim技术对深基坑模型进行建模时,由于勘探点数据的距离往往较远,难以满足构建模型所需精度要求,因此首先需要对数据进行插值,通过插值后的数据进行建模,但由于勘探点数据较多,现有方法将所有数据作为采样点进行插值导致建模速度较慢。基于此,本发明提出了一种基于bim技术的深基坑模型快速建模方法及系统,通过对突变点,即难以用函数关系拟合的勘探点附近进行较多的采样,对于规律性较强的勘探点进行较少的采样,在提高建模精度的同时,避免了采样点数量过多导致插值计算量较大,建模速度慢的问题,有效提高了建模速度。
技术实现思路
1、本发明提供一种基于bim技术的深基坑模型快速建模方法及系统,以解决现有的问题。
2、本发明的一种基于bim技术的深基坑模型快速建模方法采用如下技术方案:
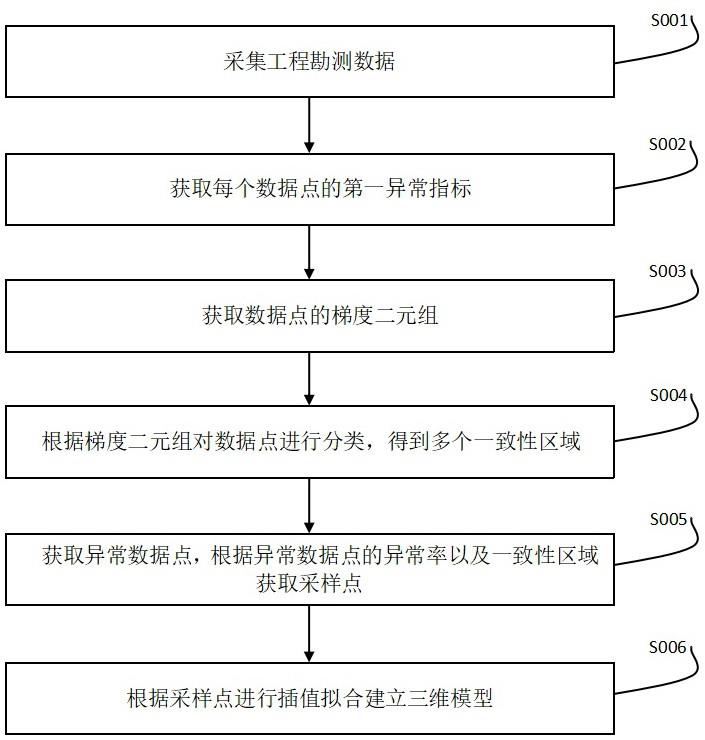
3、本发明一个实施例提供了一种基于bim技术的深基坑模型快速建模方法,该方法包括以下步骤:
4、采集工程勘测数据,得到多个数据点;
5、根据所有数据点的坐标获取三角网结构,每个数据点作为三角网结构中一个顶点;根据三角网络结构中所有顶点以及第一预设阈值,获取中心点;过中心点作360条直线作为中心线;将每条中心线包含的所有数据点的高度构成一个高度序列,根据高度序列获取中心线上每个数据点的第一异常指标;
6、根据三角网结构中所有数据点的高度获取每个数据点的所有邻域范围梯度值;根据每个数据点的所有邻域范围梯度值,获取每个数据点的梯度二元组;
7、根据每个数据点的梯度二元组对数据点进行分类;将一个类别中直接相邻或间接相连的数据点划分为一个一致性区域;根据一致性区域内数据点的个数从小到大的顺序对所有一致性区域进行排序,得到一致性区域序列;计算一致性区域序列中每个一致性区域的分割率,根据分割率获取异常数据点以及异常区域;将异常区域从一致性区域序列中剔除;
8、获取每个异常数据点的第二异常指标,将每个异常数据点的第一异常指标与第二异常指标的乘积作为每个异常数据点的异常率;
9、根据一致性区域序列中一致性区域中包含的数据点的个数以及每个异常数据点的异常率获取第一采样点集合以及每个数据点的第二采样点集合;
10、分别对第一采样点集合、每个第二采样点集合中的所有采样点进行插值拟合,将所有插值拟合结果叠加,得到插值拟合后的数据;根据插值拟合后的数据建立深基坑的三维模型。
11、优选的,所述根据三角网络结构中所有顶点以及第一预设阈值,获取中心点,包括的具体步骤如下:
12、获取所有数据点的横坐标均值和纵坐标均值作为预估初始中心点的横坐标和纵坐标值;计算所有数据点到预估初始中心点的欧式距离,将到预估初始中心点的欧式距离最小的数据点作为初始中心点;
13、获取三角网结构中和初始中心点相连的顶点作为预估顶点,计算预估顶点的高度与初始中心点的高度之间的差值的绝对值,若差值的绝对值小于第一预设阈值,将对应的顶点作为中心区域顶点,并记为第一层顶点;获取三角网结构中与第一层顶点相连但与初始中心点不相连的顶点作为新的预估顶点,计算新的预估顶点的高度与初始中心的高度的差值的绝对值,若差值绝对值小于第一预设阈值,则将对应的顶点作为中心区域顶点,并记为第二层顶点;依次类推获取第三层顶点、第四层顶点、...,直到不存在满足条件的某一层顶点时停止迭代;
14、获取所有中心区域顶点的横坐标均值以及纵坐标均值,作为预估中心点的横坐标以及纵坐标;计算每个数据点到预估中心点的欧式距离,将到预估中心点的欧式距离最小的数据点作为中心点。
15、优选的,所述根据高度序列获取中心线上每个数据点的第一异常指标,获取所有中心区域顶点,包括的具体步骤如下:
16、对高度序列进行分解得到一个残差分量,将残差分量上所有点的值的方差作为残差分量的方差值,将残差分量的方差值作为高度序列对应的中心线的异常概率;将每条中心线上的异常概率作为每条中心线上包含的每个数据点的第一异常指标。
17、优选的,所述根据三角网结构中所有数据点的高度获取每个数据点的所有邻域范围梯度值,包括的具体步骤如下:
18、获取三角网结构中与每个数据点相连的顶点,作为每个数据点的1邻域顶点;将每个数据点的每个1邻域顶点的高度减去每个数据点的高度,得到每个数据点的第一差值;将每个数据点的每个第一差值除以所有数据点的第一差值中的最大第一差值实现对每个数据点的每个第一差值的归一化;将每个数据点所有归一化后的第一差值的均值作为每个数据点的1邻域范围梯度值;
19、将每个数据点的所有1邻域顶点的1邻域范围梯度值的均值作为每个数据点的2邻域范围梯度值;将每个数据点的所有1邻域顶点的2邻域范围梯度值的均值作为每个数据点的3邻域范围梯度值,以此类推,获取每个数据点的所有邻域范围梯度值。
20、优选的,所述根据每个数据点的所有邻域范围梯度值,获取每个数据点的梯度二元组,包括的具体步骤如下:
21、对每个数据点的多个邻域范围梯度值按照邻域范围大小进行排序,得到每个数据点的梯度值序列;利用每个数据点的梯度值序列中第一个梯度值与第二个梯度值中较小的梯度值除以较大的梯度值,得到每个数据点的第一比值;当数据点的第一比值大于或等于第二预设阈值时,计算数据点的梯度值序列中第三个梯度值与第一个梯度值以及第二个梯度值的比值,将得到的两个比值的均值作为数据点的第二比值;当数据点的第二比值大于第二预设阈值t时,计算数据点的梯度值序列中第四个梯度值与前三个梯度值的比值的均值,作为第三比值,以此类推,直到得到的结果小于第二预设阈值或数据点的梯度值序列已遍历完成时停止迭代,当得到的结果小于第二预设阈值时,将得到的结果对应的倒数第二个梯度值与倒数第二个梯度值对应的邻域范围大小构成数据点的梯度二元组;当梯度值序列已遍历完成时,将梯度值序列中最后一个梯度值以及该梯度值对应的邻域范围大小构成数据点的梯度二元组。
22、优选的,所述根据每个数据点的梯度二元组对数据点进行分类,包括的具体步骤如下:
23、将两个数据点的梯度二元组中第一个元素的比值第一相似度,将两个数据点的梯度二元组中第二个元素的比值作为第二相似度;当第一相似度与第二相似度均大于第三预设阈值时,将两个数据点划分为同一个类别;
24、将两个数据点之间的第一相似度与第二相似度的均值作为两个数据点的相似度;将每个数据点与一个类别中所有数据点的相似度之和作为数据点和类别的相似度;
25、获取每个类别和其他类别的交集,得到交集数据点,将交集数据点从所属类别中去除,实现每个类别的第一次更新;对于每个交集数据点,计算交集数据点与更新后每个类别的相似度,将交集数据点加入相似度最大的类别,实现每个类别的第二次更新。
26、优选的,所述计算一致性区域序列中每个一致性区域的分割率,根据分割率获取异常数据点以及异常区域,包括的具体步骤如下:
27、对于一致性区域序列中第i个一致性区域,计算第i个一致性区域数据点个数与一致性区域序列中第i个一致性区域之前的所有一致性区域中包含的数据点个数之和,将所述数据点个数之和除以所有数据点的个数,所得的结果作为第i个一致性区域的分割率;
28、获取分割率最接近第四预设阈值的一致性区域作为分割区域,将一致性区域序列中分割区域以及分割区域之前的所有一致性区域作为异常区域,将异常区域中的数据点作为异常数据点。
29、优选的,所述获取每个异常数据点的第二异常指标,包括的具体步骤如下:
30、获取每个一致性区域内所有数据点的梯度二元组中第一个元素的均值,作为每个一致性区域的梯度值;获取每个异常数据点最接近的两个一致性区域的梯度值的差值绝对值作为每个异常数据点的第二差值,将每个异常数据点的第二差值除以所有异常数据点的第二差值中的最大第二差值实现对每个异常数据点的第二差值的归一化;将归一化后的第二差值作为对应异常数据点的第二异常指标。
31、优选的,所述根据一致性区域序列中一致性区域中包含的数据点的个数以及每个异常数据点的异常率获取第一采样点集合以及每个数据点的第二采样点集合,包括的具体步骤如下:
32、设置一个基本采样数量n,对于一致性序列中第一个一致性区域,在该一致性区域范围内进行数量为n的均匀采样,得到n个数据点,作为采样点;对于一致性区域中第二个一致性区域,首先利用第二个一致性区域中数据点的数量除以第一个一致性区域内数据点的数量,得到第二个一致性区域中数据点的数量与第一个一致性区域内数据点的数量的比值m2,在第二个一致性区域范围内进行数量为的均匀采样,得到个数据点,作为采样点;对于一致性区域中第三个一致性区域,首先利用第三个一致性区域中数据点的数量除以第一个一致性区域内数据点的数量,得到第三个一致性区域中数据点的数量与第一个一致性区域内数据点的数量的比值,在第三个一致性区域范围内进行数量为的均匀采样,得到个数据点,作为采样点;依次类推,对每个一致性区域进行采样,得到多个采样点;将对所有一致性区域采样获得的所有采样点构成第一采样点集合;
33、对于每个异常数据点,将异常数据点作为采样点,获取距离每个异常数据点欧式距离最近的个数据点,作为采样点,其中q为异常数据点的异常率;将根据每个异常数据点得到的采样点构成每个异常数据点的第二采样点集合。
34、本发明还提出一种基于bim技术的深基坑模型快速建模系统,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现任意一项所述一种基于bim技术的深基坑模型快速建模方法的步骤。
35、本发明的技术方案的有益效果是:本发明根据所有数据点获取中心点,根据过中心点的中心线获取数据点的第一异常指标,使得最终筛选的采样点与深基坑形状的贴合度较高,提高了插值拟合结果的数据质量;本发明根据三角网结构中数据点的高度获取数据点的所有邻域范围梯度值,进一步得到数据点的梯度二元组,根据梯度二元组将数据点划分为多个一致性区域,根据一致性区域内数据点的个数获取异常数据点以及异常区域,获取异常数据点的第二异常指标,进一步得到异常数据点的异常率,对一致性区域进行均匀采样并拟合,可以达到使用较少采样点数据达到较高插值精度的目的,相较于传统方法用所有数据点进行插值拟合计算,大大减小了插值拟合计算所需计算量,提高了建模速度;根据异常数据点的异常率进行采样,并与一致性区域分开拟合,避免了传统方法中为了对异常数据点和正常区域数据点的高度进行精准拟合导致计算量较大,有效提高了建模精度和速度,在建模速度较快的同时,建模精度较高,得到的深基坑模型与原始的深基坑的贴合程度更大。
- 还没有人留言评论。精彩留言会获得点赞!