一种基于PF-MADDPG的多智能体任务决策方法
本发明涉及任务规划决策领域,具体涉及一种基于pf-maddpg的多智能体任务决策方法。
背景技术:
1、由于许多序列决策问题涉及多个智能体,随着智能程度的提高和人工智能技术的快速发展,多智能体系统得到了广泛应用。与单智能体系统相比,多智能体系统具有效率高、成本低、灵活可靠等优点,能够成功处理单个智能体无法解决的复杂问题。多智能体系统由多个同构或异构的智能体组成,在系统中各智能体之间相互形成竞争或合作关系,从而使得更高阶的复杂智能出现。
2、多智能体学习主要研究多智能体之间的策略学习问题。它的主要学习方法是强化学习、鲁棒学习、学习动力学和策略学习。强化学习是一种利用经验来不断试错的学习方式。随着计算能力和存储能力的极大提高,深度学习得以被广泛应用。深度强化学习是深度学习和强化学习的结合,最近在序列决策问题上取得了重大进展,包括任务规划、智能空战和策略游戏等等。多智能体深度强化学习是开发多智能体系统的一种有效方法,它将深度强化学习的概念和方法应用于多智能体系统的学习和控制。然而,将深度强化学习应用于多智能体系统存在许多困难,如非唯一学习目标、非静态环境、部分可观察性、算法稳定性和收敛性等。
3、深度强化学习在多智能体系统中的应用已经取得了一定的进展。j.n.foerster等提出的深度分布式递归q网络算法(deep distributed recursive q algorithm,ddrqn)有效地解决了多智能体部分可观测问题和部分马尔可夫决策过程(partially observablemarkov decision process,pomdp)问题。该方法的缺点是假定所有智能体都将选择相同的行动路线,无法解决异构多智能体最优控制问题。随后,该团队又提出了一种反拟多智能体策略梯度算法(counterfactual multi-agent policy gradients,coma),该算法通过使用全局奖励函数来评估所有当前的动作和状态,从而提高了智能体协作的能力,但缺点是局限于离散的运动空间。此外,多智能体协同控制强化学习算法主要包括宽松深度q学习网络(lenient deep q-network,ldqn)算法、q学习混合网络(qmix)算法、多智能体深度确定性策略梯度(multi-agent deep deterministic policy gradient,maddpg)算法等。
4、与其他算法相比,maddpg算法采用集中式训练、分布式执行的结构,是目前应用较为广泛的多智能体强化学习算法结构。maddpg算法可以处理多种任务场景,包括同构或异构多智能体之间的竞争与合作。在整个训练过程中,可以使用其他智能体的观测数据进行集中训练,提高算法效率。
5、公开号为cn113589842a的发明中提出了一种基于多智能体强化学习的无人集群任务协同方法,基于unity搭建面向多无人系统任务规划的强化学习仿真环境;使用gym将获取到的仿真环境的信息搭建成符合规范的强化学习环境;对无人机集群对抗环境建模;使用tensorflow深度学习库搭建多智能体强化学习环境;使用协作深度确定性策略梯度方法求解多智能体强化学习问题;输出无人集群任务规划结果。该发明对现有技术进行了较大改进,能够得到更为良好的多无人系统协同任务规划结果。该发明更新了强化学习奖励规则,传统方法直接使用环境得到的外部奖励作为自身奖励,这样难以学习到协作的策略,该发明将其他智能体的奖励的平均值作为外部奖励,将环境交互获得的奖励作为内部奖励,两者加权,可以更好反应队友的策略的影响,有利于协作。然而,由于其算法中引入其他智能体的局部状态平均值和其他智能体动作的平均,该算法无法应用于异构多智能体场景。
6、虽然势函数早有应用,例如公开号为cn110134140b的发明中提出了一种环境信息未知连续状态下基于势函数奖赏dqn的无人机路径规划方法,其中采用了势函数奖赏,然而,该发明只考虑了单个无人机避障的任务场景,并未将势函数奖励应用至多智能体对抗博弈中,该方法是否能解决多智能体情况下的路径规划问题还有待研究。
技术实现思路
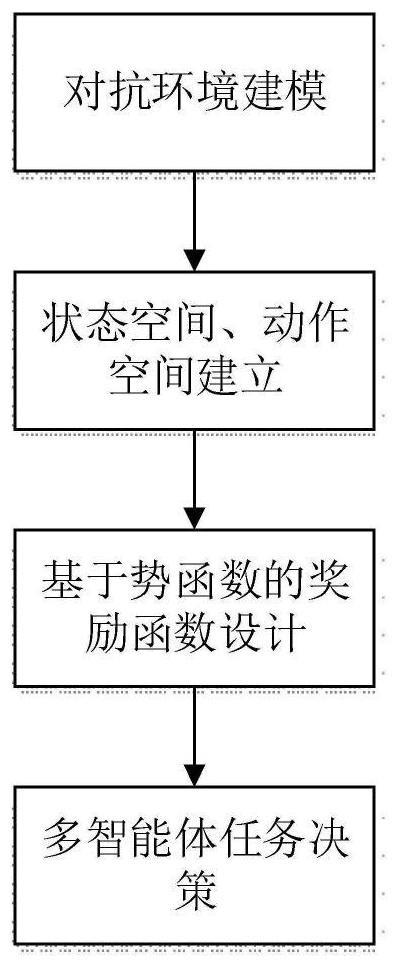
1、针对上述现有技术的不足,本发明公开了一种基于pf-maddpg的多智能体任务决策方法,首先根据多智能体攻防对抗环境,建立深度强化学习算法所需二维环境模型;其次,设计智能体的连续状态空间、动作空间、基于势函数的奖励函数,将学习的过程描述为马尔可夫决策过程;最后进行学习训练,得到多智能体任务决策网络。本发明使用基于pf-maddpg的强化学习算法,具有集中式学习和分布式执行的特点,允许智能体在学习时使用全局信息,但是在应用决策的时候只使用局部信息,能够使多智能体在环境未知的前提下,进行高效的任务决策,同时,该方法还采用势函数设计奖励函数,使得整个网络的收敛速度提升,并且可以实现多智能体攻防对抗自主决策的目的。
2、为实现上述技术目的,本发明采取的技术方案为:
3、一种基于pf-maddpg的多智能体任务决策方法,所述多智能体任务决策方法包括以下步骤:
4、步骤1:设定攻防对抗环境中存在若干个攻击者、若干个防御者和若干个静止目标区域,在环境中随机生成各智能体和目标区域的位置,构建一个多智能体攻防对抗环境;
5、步骤2:建立智能体的状态空间,每个智能体i的状态空间由智能体在各个时刻的状态构成,每一个智能体的状态包括其自身的速度和位置、其他智能体的速度和相对位置以及其与目标区域的相对位置;
6、步骤3:建立智能体的动作空间,每个智能体i的动作空间由智能体在各个时刻的采取的动作构成;
7、步骤4:建立智能体的奖励函数;具体包括以下子步骤:
8、定义进攻智能体碰撞奖励函数rcol,att和防御智能体碰撞奖励函数rcol,def:
9、
10、
11、对于进攻智能体与目标,基于势函数构建其所对应的距离奖励函数如下:
12、
13、式中,分别表示进攻智能体和目标之间在t时刻和t+1时刻的距离,λ为智能体的移动步长;
14、对于进攻智能体和防御智能体,基于势函数构建其所对应的距离奖励函数如下:
15、
16、式中,分别表示进攻智能体和防御智能体之间在t时刻和t+1时刻的距离;
17、计算得到进攻智能体的奖励函数为:
18、ratt=rcol,att+rat;
19、计算得到防御智能体的奖励函数为:
20、rdef=rcol,def+rad
21、步骤5:建立与训练基于pf-maddpg算法的多智能体任务决策网络模型,其中,获取训练多智能体任务决策网络模型所需的经验池的过程包括:
22、根据步骤4的进攻智能体和防御智能体的奖励函数计算状态改变后智能体得到的奖励,获得每个智能体的状态转移序列<st,at,rt,st+1>,st为智能体在时刻t的状态,st+1为智能体在时刻t+1的状态,at为智能体在时刻t的状态st下采取的动作,rt为智能体在时刻t的状态st下采取动作at后获得的奖励值;将每个智能体的状态转移序列存储空间定义为一个经验池,将每一时刻得到的状态转移序列存储到经验池中;
23、步骤6:使用训练完成的多智能体任务决策网络模型实现多智能体的任务决策。
24、进一步地,步骤2中,智能体i在t时刻的状态si,t定义为:
25、si,t={vself,x,vself,y,xself,yself,vother,x,vother,y,xother,yother};
26、其中vself,x和vself,y分别为智能体i在t时刻的x、y轴的速度分量,xself和yself分别为智能体i在t时刻的x、y轴的位置坐标;vother,x和vother,y分别为其他智能体t时刻在x、y轴的速度分量,xother和yother为智能体i在t时刻与其他智能体的相对位置坐标;
27、假设训练时间为t0至tt,智能体i的状态空间由智能体si在各个时刻的状态构成:
28、
29、进一步地,步骤2中,步骤3中,建立智能体的动作空间的过程包括以下子步骤:
30、将智能体i的状态si作为策略网络的输入,输出智能体i动作策略ai:
31、ai=μi(si)+nnoise
32、其中nnoise为环境噪声,μi为智能体i的策略;
33、采用策略集成的方法得到二维加速度向量
34、
35、其中和分别为智能体在左、右、上、下方向上的加速度分量;η是和加速度有关的灵敏度系数,用于限制加速度的范围;
36、计算得到瞬时速度向量的值:
37、
38、智能体经过δt时间后移动到下一个位置,位置的更新由如下公式得到:
39、
40、智能体i的动作空间由智能体在各个时刻的采取的动作构成。
41、进一步地,步骤2中,步骤5中,建立与训练基于pf-maddpg算法的多智能体任务决策网络模型的过程包括以下子步骤:
42、步骤5-1:初始化步骤1中建立的多智能体攻防对抗环境;
43、步骤5-2:各智能体随机选择动作,使得各智能体的状态发生变化,从而使得对抗环境发生改变;
44、步骤5-3:根据步骤4的智能体奖励函数计算状态改变后智能体得到的奖励,获得每个智能体的状态转移序列<st,at,rt,st+1>,st为智能体在时刻t的状态,st+1为智能体在时刻t+1的状态,at为智能体在时刻t的状态st下采取的动作,rt为智能体在时刻t的状态st下采取动作at后获得的奖励值;
45、步骤5-4:每个智能体的状态转移序列存储空间定义为一个经验池,将步骤5-3中每一时刻得到的状态转移序列存储到经验池中;
46、步骤5-5:每个智能体的控制网络采用actor-critic结构,actor网络和critic网络也采用双网络结构,各自有target网络和eval网络;
47、步骤5-6:随机从经验池中取出一批不同时刻的经验,组成经验包<s,a,r,s′>,其中s为智能体在当前时刻的状态集合,s′为智能体在下一时刻的状态集合,a为智能体在当前时刻的状态集合s下采取的动作集合,r为智能体在当前时刻的状态集合s下采取动作集合a中的动作后获得的奖励值集合;
48、步骤5-7:将下一时刻的状态集合s′输入智能体的actor网络,输出下一时刻智能体动作集合a′,将s′和a′作为critic网络的输入,计算每个智能体对下一时刻估计的目标q值;
49、步骤5-8:定义critic网络的损失函数为:
50、
51、其中,n为所有智能体的数量,m为训练时抽取的经验数;是一个以所有智能体的动作以及一些状态信息xj作为输入的q值,xj由所有智能体的观测(o1,o2,...on)组成,也可以包含其他状态信息;表示智能体i的第j条经验目标q值,其计算公式为:
52、
53、其中表示智能体i的第j条经验获得的奖励值,γ是折扣因子,是一个以所有智能体下一步动作以及一些下一时刻状态信息x′j作为输入的q值;
54、步骤5-9:通过最小化步骤5-8中的损失函数loss更新critic网络中的eval网络;
55、步骤5-10:定义策略梯度计算公式:
56、
57、步骤5-11:通过策略梯度计算公式更新actor网络中的eval网络;
58、步骤5-12:间隔固定时间通过软更新的方法更新actor网络和critic网络中的target网络;
59、步骤5-13:重复步骤5-2到步骤5-12,达到最大训练次数设定值时停止重复。
60、与现有技术相比,本发明的有益效果如下:
61、第一,本发明的基于pf-maddpg的多智能体任务决策方法,将基于势函数的奖励函数与maddpg算法结合,相比传统的深度强化学习算法,具有更高的学习效率和更快的收敛速度,并且可以实现多智能体攻防对抗自主决策的目的;
62、第二,不同于需要精确模型信息的控制方法,本发明提供的pf-maddpg算法无需精确建模,利用经验不断试错来学习和训练,可以更好地应用于多智能体系统;
63、第三,本发明的基于pf-maddpg的多智能体任务决策方法,在未知的环境下也可以高效的进行决策,克服了已有技术中只能在已知或静态环境下进行任务决策的缺陷。
- 还没有人留言评论。精彩留言会获得点赞!