基于约束强化学习的流域水量水质联合调度方法与流程
本发明涉及智能环境水务,更具体的说,本发明涉及一种基于约束强化学习的流域水量水质联合调度方法。
背景技术:
1、在智慧环境水务领域的工作中,为了应对极端降雨天气情况,充分发挥已有水网的承载能力,实现流域内的防洪调峰,通常需要对流域内的流量实施精准调度。此外,为了确保考核断面水质达标,也需要对流域内的水量水质进行精准调度。
2、在部分地区,流域内水位-流量关系复杂多变,为了同时实现水质改善和防洪排涝的目标,通常需同步考虑河流水系的分布特征、区域降雨特性、防洪、治涝工程之间的联动性、制约性、独立性,再根据专家经验设计调度规则,实现流域内水量的动态调度。但在设计此类基于规则的调度方法时需要依赖大量人力,同时受限于规则的表示能力,当遭遇极端、复杂的天气环境时,基于规则的调度方法通常无法兼顾水质改善和防洪排涝等多项指标。
3、因此,针对这一问题,迫切需要研发一种能适用于极端、复杂环境的高效水量水质联合调度方法,以满足实际需要。
技术实现思路
1、为了克服现有技术的不足,本发明提供一种基于约束强化学习的流域水量水质联合调度方法,该方法改善了现有水量水质调度方法无法有效应对复杂极端情况下的问题。
2、本发明解决其技术问题所采用的技术方案是:一种基于约束强化学习的流域水量水质联合调度方法,其改进之处在于,该方法包括以下的步骤:
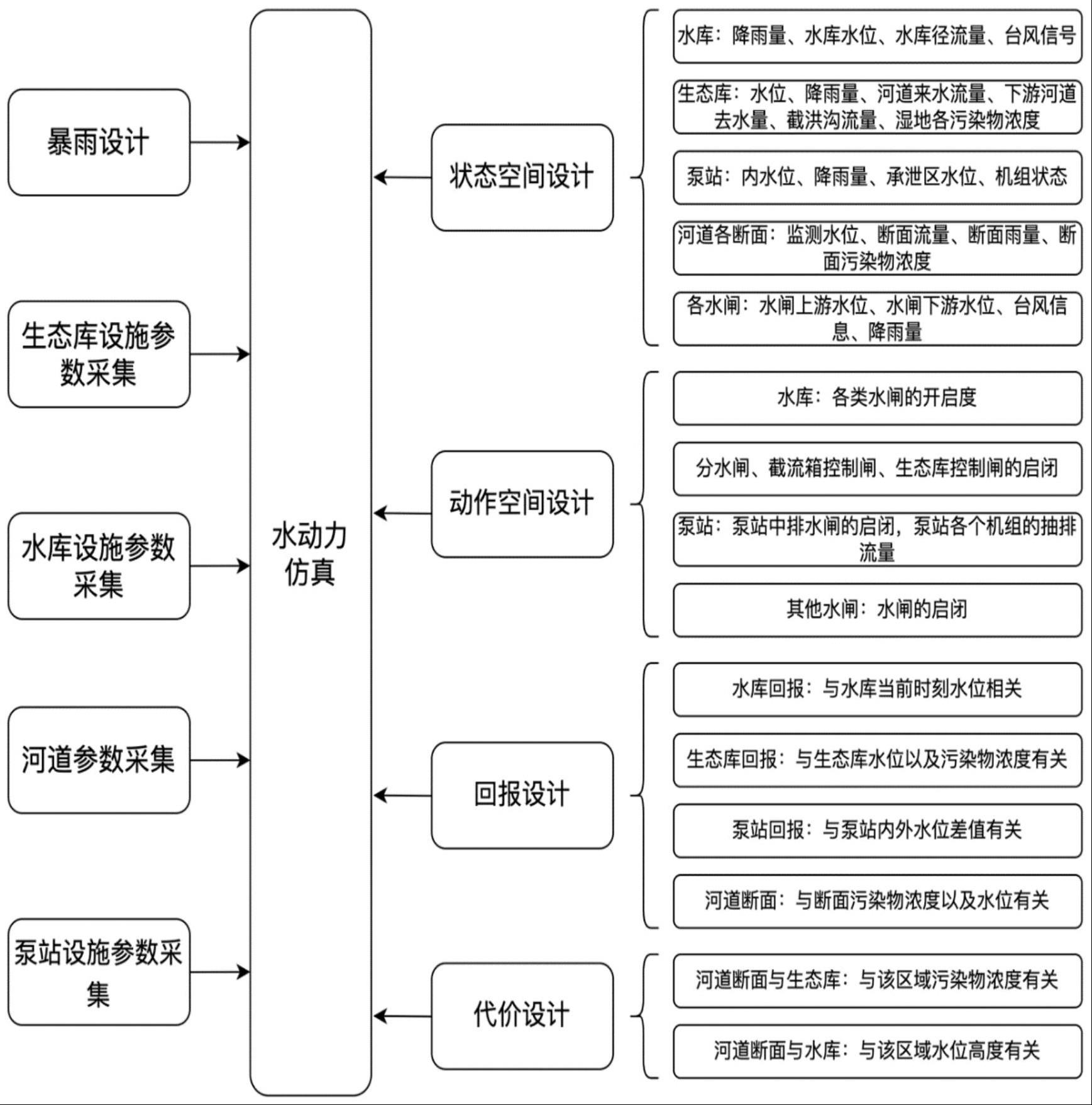
3、s10、水质耦合仿真模拟平台的构建,对水质耦合仿真模拟平台中的状态空间、动作空间、每时刻回报以及每时刻各类代价进行设计,并基于水动力学仿真平台,构建水质耦合仿真模拟平台;
4、s20、策略网络及评估网络的构建,采用神经网络表示调度策略,其策略网络的输入为当前时刻的系统状态,策略网络中的状态向量的组成与步骤s10中状态空间的设计相同,策略网络的输出为当前时刻应执行的动作,策略网络的动作向量的组成与步骤s10中动作空间的设计相同;
5、所述评估网络包括回报评估网络和多个针对不同代价指标的代价评估网络,回报评估网络的输入为系统当前的状态,输出为对当前调度策略所得的累计回报的估计;代价评估网络的输入为系统当前的状态,输出为对当前调度策略所得的累计代价的估计;
6、s30、交互式调度策略的优化,策略网络的优化目标是令调度策略满足代价约束的条件下最大化累计回报。
7、进一步的,步骤s10中,所述的状态空间包括水库、生态库、泵站、河道以及水闸中水量的各项参数,其内容如下:
8、水库:雨量、水位、当前库容、渗漏量、进出库流量、各类污染物浓度;
9、生态库:雨量、水位、进出库水量、截洪沟流量、各类污染物浓度;
10、泵站:雨量、内水位、承泄区水位、机组运行状态;
11、河道:雨量、水位、流量、断面各类污染物浓;
12、水闸:雨量、水闸上游水位、水闸下游水位。
13、进一步的,步骤s10中,所述动作空间包括水库、生态库、泵站以及水闸中闸门的各项参数,其内容如下:
14、水库:各类水闸的开启度,包括挡潮闸、分洪闸、节制闸、截污闸、景观闸;
15、生态库:分水闸、截流箱控制闸、生态库控制闸的启闭;
16、泵站:泵站中排水闸的启闭、泵站各个机组的抽排流量以及泵房应急处置措施,其中泵房应急处置措施包括堆积沙袋拦水高度;
17、水闸:水闸的启闭。
18、进一步的,步骤s10中,每时刻回报记为,由不同区域不同设施的该时刻回报组成,包括:
19、水库内的回报同水库的水位与水库汛限水位的差值相关,当水库水位小于汛限水位时回报高,反之回报低,其中 i 表示第 i 个水库;
20、生态库的回报同生态库内湿地水位以及各类污染物含量相关,污染物类型k的含量越低,其对应的回报越高;对湿度水位进行控制,其对应回报设计为与预期水位的差值的绝对值,则生态库的回报为这两项子回报的和:;
21、泵站的回报与内水位与设计水位的差值、以及有关泵站机组运行功率相关;若内水位大于设计水位则对应的回报为负值,用于对当前状态进行惩罚,反之回报为0;若泵站内机组运行功率越高则对应的回报越低,此回报用于尽量减少电量消耗,实现能量利用的最优化;泵站内的总汇报为上述回报之和:;
22、河道断面回报与河道断面的水位以及该断面各污染物指标相关;若河道水位小于设计水位则对应的回报为正值,反之该回报为负值;该河道断面的污染物类型k的含量越低,则对应的回报则越高;因此,河道断面的总回报为上述回报之和:
23、;
24、环境中t时刻的回报为上述所有回报之和,即:
25、。
26、进一步的,步骤s10中,每时刻各类代价的设计时的约束条件包括:
27、水位不超过设施的溢出水位;
28、各断面的各类污染物浓度不超度设计阈值。
29、进一步的,步骤s10中,每时刻各类代价的设计包括以下步骤:
30、河道断面以及生态库污染物浓度代价记为,其中k表示第k种污染物,i表示第i个设施;若污染物浓度越大,则代价越高;
31、河道以及水库断面的水位代价记为,其中i表示第i个设施;若水位越高,则代价越高;
32、代价的约束表示为:
33、;
34、;
35、其中表示第k种污染物指标的设置阈值,表示第i个设施的水位设置阈值;上述公式中表示,在某个河道断面上,所有时刻水位平均值要小于设计阈值,或所有时刻该断面某种污染物浓度的平均值小于设计阈值。
36、进一步的,所述步骤s10中,还包括对水质耦合仿真模拟平台中的暴雨设计的步骤:暴雨设计原则根据当地100年一遇的极端降水标准进行设计。
37、进一步的,所述步骤s30中,调度策略的网络优化目标由以下公式描述:
38、;
39、;
40、;
41、其中,表示调度策略网络;优化策略网络的步骤如下:
42、s301、流域仿真环境输出一个初始状态,令t=0,初始化数据库d;
43、s302、调度策略会根据t时刻,系统状态执行动作;
44、s303、流域仿真环境根据调度策略的动作,将系统状态转移到下一个时刻的状态,同时给出当前这一时刻的回报,以及各类代价;
45、s304、对这一步的交互数据进行储存,数据元组的格式为,将该数据存入数据库d;
46、s305、令,若距离上一次策略网络更新超过了p步,利用带约束的强化学习方法对调度策略进行优化,同时优化回报评估网络和代价评估网络,随后清空数据库d,当更新后策略收敛了则迭代结束,否则返回至步骤s302。
47、进一步的,所述的步骤s30中,还包括采用梯度下降法对于回报评估网络和代价评估网络优化的步骤,采用的损失函数如下:
48、;
49、;
50、;
51、其中示评估网络的权重,表示各个评估网络。
52、进一步的,所述步骤s305中,带约束的强化学习方法包括以下内容:
53、采用对偶乘子法处理带约束的强化学习问题,其目标函数如下:
54、;
55、其中,和分别为各个约束项的乘子系数,表示调度策略,t表示时间,表示惩罚系数,表示t时刻调度策略从仿真环境中得到的回报值,m表示具有m个不同的代价约束,表示t时刻调度策略从仿真环境中得到的不同的代价值,表示不同的代价值阈值;
56、带约束的强化学习方法包括步骤:
57、s3051、利用策略梯度方法对目标函数进行优化,更新调度策略网络;
58、s3052、更新对偶乘子,更新方式如下公式:
59、;
60、;
61、s3053、若调度策略网络未收敛则返回至步骤s3051,否则结束。
62、本发明的有益效果是:本发明提供一种基于约束强化学习的流域水量水质联合调度方法,该方法改善了现有水量水质调度方法无法有效应对复杂极端情况下的问题,使得调度策略实现对流域的流量的调度以及水域的水质保障。
- 还没有人留言评论。精彩留言会获得点赞!