一种基于样本重放和知识蒸馏的终身学习方法与流程
本发明属于人工智能领域,具体涉及一种基于样本重放和知识蒸馏的终身学习方法。
背景技术:
1、传统的深度学习模型要求在训练前取得所有训练样本以进行离线训练,并且在训练结束后无法继续更新。然而,在开放动态环境中,训练样本往往以数据流的形式到来,或因存储、隐私等问题仅在一段时间内可以获得。理想情况下的深度学习模型应当能够仅利用数据流中的新样本更新模型,而无需耗费大量计算资源进行重新训练。然而,当深度学习模型从原来的批量学习模式转变为序列学习模式时,很容易出现对旧知识的遗忘,这意味着,在使用新数据更新模型后,模型在先前学习的任务中所达到的性能会急剧下降,出现灾难性遗忘。因此,如何在模型持续学习新数据的同时抵抗对旧数据的灾难性遗忘便成为终身学习问题的研究重点。
2、目前终身学习技术主要有基于样本重放的方法、基于知识蒸馏的方法和基于正则化的方法。
3、基于样本重放的方法通过获取存储在内存缓冲区中的先前任务数据子集并与当前任务数据集联合训练来解决灾难性遗忘。早期工作提出了经验重放(experiencereplay,er),即在训练批次中交错旧样本和当前数据。最近的一些研究直接扩展了这一想法:元体验重放(mer)将重放视为元学习问题,以最大化过去任务的迁移,同时最小化干扰;基于梯度的样本选择(gss)引入了er的变体,将最优选择的示例存储在内存缓冲区中;后见锚定学习(hal)补充了重放的额外目标,以限制对关键学习数据点的遗忘。另一方面,梯度情景记忆(gem)和它的轻量级变种(a-gem)利用旧的训练数据来构建当前更新步骤所满足的优化约束。然而,当任务的训练集样本较多时,这些改进工作并不总是优于er,因此本发明在er的基础上继续研究,提出的kd2er在整个训练轨迹上采样,通过计算黑暗知识(即由已经训练好的模型对未标注数据各个类别的概率信息)来提取过去的经验。
4、基于知识蒸馏的方法通过知识蒸馏手段,以旧模型作为老师模型,以新模型作为学生模型进行知识蒸馏,进而维持模型在旧类别上的判别能力。learning wi thoutforgett ing(lwf)中的知识蒸馏损失通过最小化新旧模型输出的概率分布之间的kl散度,最大限度地减少训练期间的漂移。icarl中利用了样本重放和知识蒸馏的组合技术,通过对齐新旧模型在旧类上的预测概率,使得新模型在旧类上保持了和旧模型一致的判别能力,从而抵抗灾难性遗忘。
5、基于正则化的方法通过在训练新任务时向损失函数中添加正则项减少参数的巨幅改变以此保留旧知识,典型的工作有ewc,si,imm,mas和rw。
6、本发明方法和lwf都利用了知识蒸馏,但它们采用了截然不同的方法。后者不会重放过去的样本,它只会鼓励新旧模型对当前任务数据点的反应之间的相似性。虽然本发明和icarl都利用过去任务的样本去克服灾难性遗忘,但后者利用每个任务结束时指定的网络作为唯一的教师网络;相反,本方法存储在先前所有任务样本的输出概率信息,这相当于有多个不同的教师网络同时指导新模型的训练。
技术实现思路
1、(一)要解决的技术问题
2、本发明要解决的技术问题是如何提供一种基于样本重放和知识蒸馏的终身学习方法,以解决深度学习模型中灾难性遗忘问题。
3、(二)技术方案
4、为了解决上述技术问题,本发明提出一种基于样本重放和知识蒸馏的终身学习方法,该方法包括:
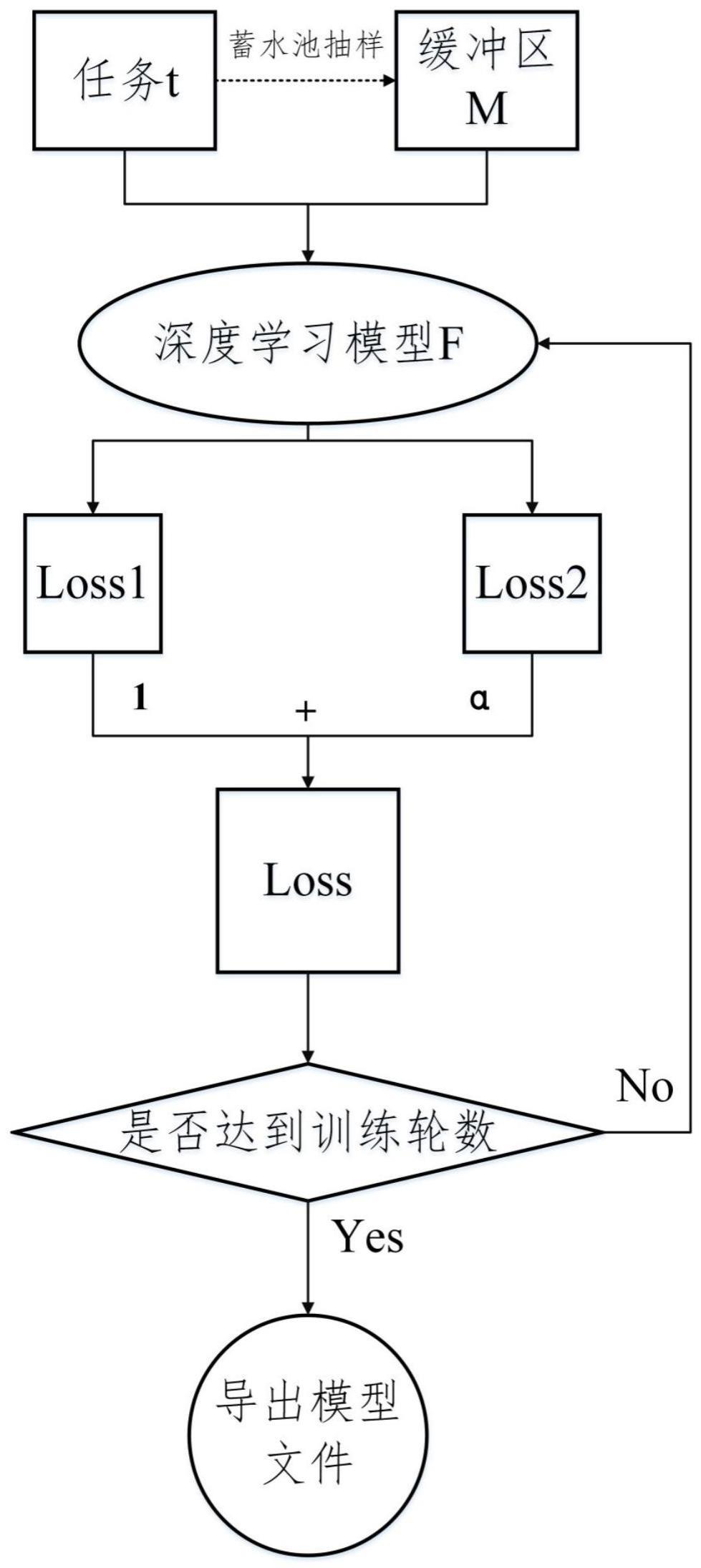
5、任务t代表将要处理的任务数据集,缓冲区m存放了过去任务的部分数据集以及旧模型的概率输出信息,当前任务的样本通过蓄水池抽样算法选择性地加入到缓冲区m中;
6、在训练时,首先选择一种深度学习模型f,设置epochs和batch_size,模型f在任务t上训练损失记为loss1,模型f在缓冲区m上的损失记为loss2,其中hθ(x)表示模型f对样本x的类概率预测输出,z为旧模型在样本x上的类概率预测输出,表示z和hθ(x)的欧氏距离,z和hθ(x)越相似,欧氏距离越小;
7、总损失为loss=loss1+α*loss2,α是loss1和loss2之间平衡的超参数;
8、此时判断是否达到训练总轮数epochs,如果达到则导出训练好的模型文件,否则反向传播更新权重并再次计算loss。
9、(三)有益效果
10、本发明提出一种基于样本重放和知识蒸馏的终身学习方法,本发明与现有技术相比的优点在于:
11、本发明提供了一种简单、高效且有效的终身学习方法,此算法时间复杂度不随任务数量增多而增大,可以应用于任何分类任务的深度学习模型。在持续迭代优化中,该方法可以在不遗忘旧任务的知识基础上,有效学习新任务知识,从而缓解神经网络灾难性遗忘的难题。本发明方法无需事先知道任务的数量、任务标签和样本数量,可以实现通用终身学习的要求。
技术特征:
1.一种基于样本重放和知识蒸馏的终身学习方法,其特征在于,该方法包括:
2.如权利要求1所述的基于样本重放和知识蒸馏的终身学习方法,其特征在于,模型f为resnet18。
3.如权利要求1所述的基于样本重放和知识蒸馏的终身学习方法,其特征在于,模型f为efficientnet。
4.如权利要求1所述的基于样本重放和知识蒸馏的终身学习方法,其特征在于,loss1为交叉熵损失。
5.如权利要求1所述的基于样本重放和知识蒸馏的终身学习方法,其特征在于,欧氏距离为kl欧氏距离。
6.如权利要求1所述的基于样本重放和知识蒸馏的终身学习方法,其特征在于,旧模型作为教师模型,新模型作为学生模型,通过正则化损失函数实现教师模型对学生模型的指导。
7.如权利要求1所述的基于样本重放和知识蒸馏的终身学习方法,其特征在于,m是总缓冲区,存储了过去任务1,2,...,tc-1中样本x的属性特征及对应的概率预测信息z,tc-1为任务编号。
8.如权利要求1所述的基于样本重放和知识蒸馏的终身学习方法,其特征在于,一个终身学习分类问题被划分为t个任务,在每个任务t∈{1,2,...,t}中,输入样本x及其对应的真实值标签y服从分布dt;
9.如权利要求1-8任一项所述的基于样本重放和知识蒸馏的终身学习方法,其特征在于,所述蓄水池抽样算法过程为:
10.如权利要求9所述的基于样本重放和知识蒸馏的终身学习方法,其特征在于,蓄水池抽样在不事先知道数据流s长度的情况下,从输入流中随机抽取|m|个样本,以保证它们存储在缓冲区中的概率|m|/|s|相同。
技术总结
本发明涉及一种基于样本重放和知识蒸馏的终身学习方法,属于人工智能领域。本发明中,任务t代表将要处理的任务数据集,缓冲区M存放了过去任务的部分数据集以及旧模型的概率输出信息,当前任务的样本通过蓄水池抽样算法选择性地加入到缓冲区M中;在训练时,选择一种深度学习模型F,模型F在任务t上训练损失记为Loss1,模型F在缓冲区M上的损失记为Loss2,总损失为Loss=Loss1+α*Loss2;判断是否达到训练总轮数epochs,如果达到则导出训练好的模型文件,否则反向传播更新权重并再次计算Loss。本发明是一个通用的终身学习训练策略,适用于任何分类任务的深度学习模型,可以缓解神经网络灾难性遗忘问题,使深度学习模型具备持续学习的能力。
技术研发人员:刘朋杰,刘洪宇,王浩枫
受保护的技术使用者:北京计算机技术及应用研究所
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!