一种环境水务监测采样异常数据快速识别方法与流程
本发明涉及水务数据处理,具体的,本发明涉及一种环境水务监测采样异常数据快速识别方法。
背景技术:
1、在环境水务领域的工作中,通常会在某一水域中采集大量数据,例如,实时流量、温度、溶解氧、藻类、有机碳、有机磷、有机氮、氨氮等数据,这些数据可用于分析水域的水动力学特征及水域污染状况、污染程度以及污染机制。因此,采集数据这一步骤对水域防洪排涝、污染治理起着至关重要的作用。然而,在野外采集的数据通常会因为各种原因导致数据发生异常,例如传感器损坏、采集人员操作不当、设备中存在累计误差等。因此,从大量数据中,自动化识别异常数据则尤为关键,对于确保环境水务分析工作有着非常重要的意义。
2、经检索,公开号为cn109160550a 公开了一种城市污水处理信息管理系统,其中采用了基于故障树的专家系统对污水处理过程中的异常部分进行识别。然而,此类方法并未充分考虑同种数据类型之间的时空连续性关系,也未考虑不同数据类型之间的以微分方程表示的机理关系。该方法中只是单纯的考虑数据大小的异常(过高或者过低),并参照故障树来判断系统中的异常。此类专家系统的特征为简单、高效,但无法识别复杂的、潜在的系统故障。此外,公开号为cn111830871a的中国发明专利,公开了利用设备数据的频域分析方法对水务监测设备进行异常识别,但该方案存在以下的缺陷:在频域上表示数据特征通常表示能力不足,难以表征不显著的异常,导致难以发现潜在的数据异常。
3、上述的已公开的方案,均存在对水务数据的异常进行识别时不可靠、不准确的问题,为了能够提高异常识别能力,使其能够识别复杂、潜在的异常,发明提供了一种新的方案,以实现环境水务中更可靠、更准确的数据异常识别,以满足实际需要。
技术实现思路
1、为了克服现有技术的不足,本发明提供了一种环境水务监测采样异常数据快速识别方法,以解决上述的技术问题。
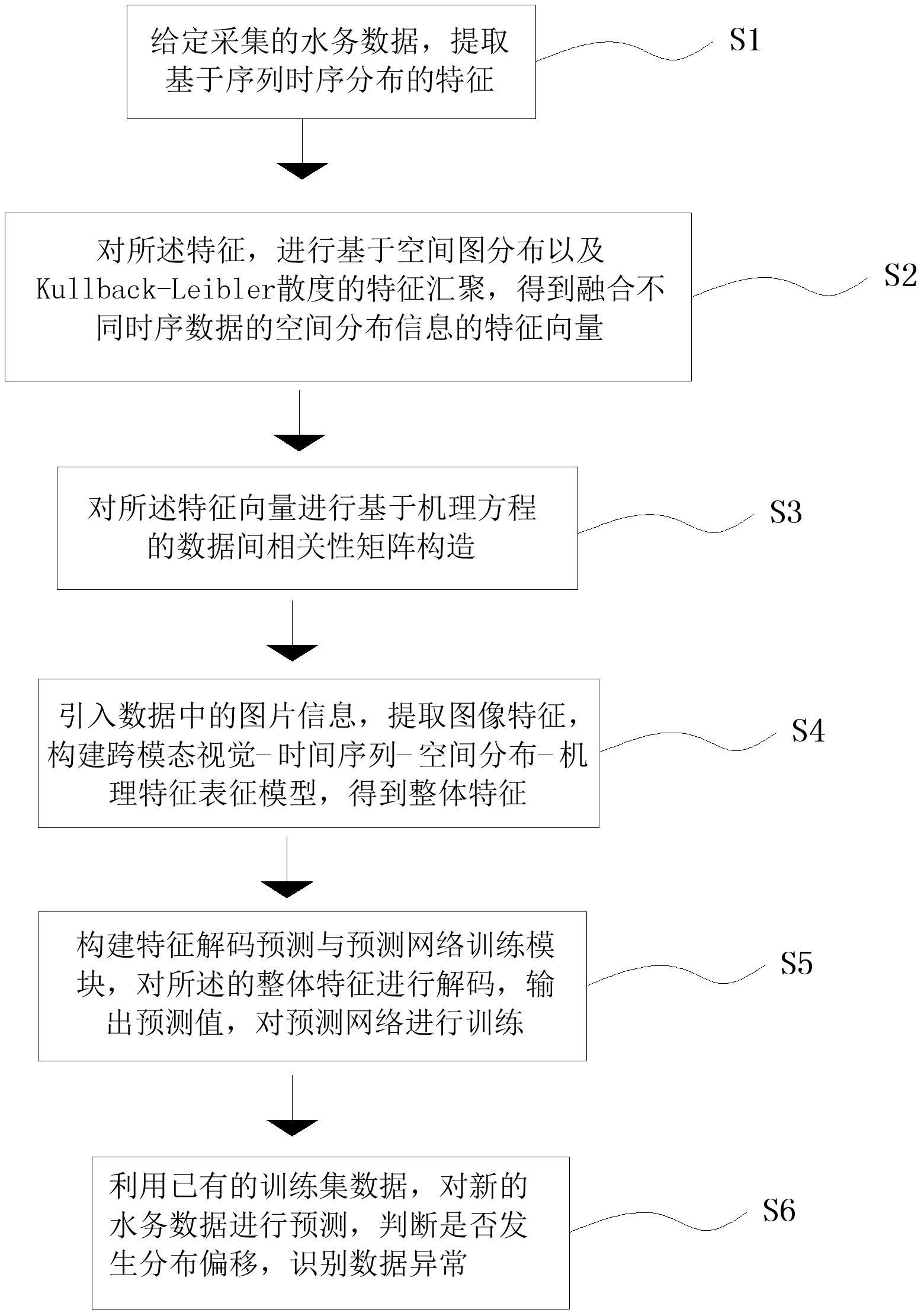
2、本发明解决其技术问题所采用的技术方法是:一种环境水务监测采样异常数据快速识别方法,其改进之处在于:包括以下的步骤:s1、给定采集的水务数据,提取基于序列时序分布的特征;s2、对所述特征,进行基于空间图分布以及kullback-leibler散度的特征汇聚,得到融合不同时序数据的空间分布信息的特征向量;s3、对所述特征向量进行基于机理方程的数据间相关性矩阵构造;s4、引入数据中的图片信息,提取图像特征,构建跨模态视觉-时间序列-空间分布-机理特征表征模型,得到整体特征;s5、构建特征解码预测与预测网络训练模块,对所述的整体特征进行解码,输出预测值,对预测网络进行训练;s6、利用已有的训练集数据,对新的水务数据进行预测,判断是否发生分布偏移,识别数据异常。
3、在上述方法中,所述步骤s1,包括以下的步骤:
4、s11、给定采集的数据,其中m、n表示该数据在空间位置(m,n)处被采集,t表示该数据在t时刻被采集,k代表该数据的类型;
5、s12、每一个数据类别k,均构造一个基于transformer的时序特征提取网络;
6、s13、将同一地点同种类别的数据聚合在一起,构造一条序列数据,利用所述的时序特征提取网络对所有序列数据的特征进行提取。
7、在上述方法中,所述步骤s13中,对所有序列数据的特征进行提取,采用赋权时序注意力机制,公式表示如下
8、
9、其中。
10、在上述方法中,得到对应的基于时间序列的注意力权重矩阵为
11、。
12、在上述方法中,所述步骤s2,包括以下的步骤:
13、s21、将所得到的同一类别的数据所构造的特征,按照数据的地理位置分布,进行排列,构造为一个特征图,特征图中的节点为一条时序数据的特征向量,两个节点之间的边的权重计算方式为:将地理位置为的图节点构造成一个均值为,协方差为的高斯分布;特征图中相邻两个节点的边的权重根据两个高斯分布间的kullback-leibler散度进行计算
14、;
15、s22、采用图网络对特征图中基于空间排列的数据时序特征向量进行赋权特征汇聚。
16、在上述方法中,所述步骤s3,包括以下的步骤:
17、s31、依据水动力、水质和藻类生消变化机制,构造不同数据类别间的重要性分数;
18、s32、依据该分数构造不同数据类型间的邻接矩阵,其中邻接矩阵中元素表示打出的数据类之间的分数,构造数据间的相关性矩阵,构造方式为
19、。
20、在上述方法中,所述步骤s4,包括以下的步骤:
21、s41、引入数据中的图片信息,采用vision transformer对图片信息特征进行提取;
22、s42、将该图片信息特征与所述的特征向量进行拼接;
23、s43、利用所述的相关性矩阵对拼接后的特征进行赋权,构建跨模态视觉-时间序列-空间分布-机理特征表征模型,得到整体特征。
24、在上述方法中,所述步骤s5,包括以下的步骤:
25、s51、对所述的整体特征进行解码,输出对未知点处(m,n,t,k)数据的预测值;
26、s52、对原始数据中的随机数据进行屏蔽,对该屏蔽数据进行位置编码、时间编码以及数据种类编码,利用预测网络对屏蔽的数据进行预测,预测目标为该屏蔽数据的真实值以及预测值之间的欧式距离,构造梯度信息,对预测网络进行训练。
27、在上述方法中,所述步骤s51中,对所述的整体特征进行解码,采用多层multi-head 注意力网络作为解码器。
28、在上述方法中,所述步骤s6,包括以下的步骤:
29、s61、利用已有的训练集数据,在新数据的邻域中抽取q批数据,循环的将这q批数据作为预测网络的输入,对所述的未知点处(m,n,t,k) 的数据进行预测,输出预测均值和预测标准差,得到q个对该未知点的预测值和预测标准差;
30、s62、根据所预测的均值和预测方差,构建q个高斯分布;
31、s63、以新数据作为高斯分布中的一个样本点,计算该样本点在这q个高斯分布中的概率密度;
32、s63、当该样本点在其中一个高斯分布中时,且所述的新数据的概率密度低于设定的阈值,则识别该样本点异常。
33、本发明的有益效果是:融合了数据间时间序列关系、数据间空间分布关系以及基于机理的相关性模块,并且采用了跨模态的大模型对水务数据进行提取,能够更加有效的对数据中的潜在特征进行捕获,从而提高了水务数据中对数据异常识别的可靠性和准确性;数据特征表示中,同时融合了数据间的时序关系、基于图表示的空间分布关系、以及机理关系,使得对数据的特征表示更加准确,解决了一般数据异常识别中因特征能力表示不足而导致的识别不准确的问题;采用对数据进行先预测后识别的方式进行数据的异常识别,即先利用邻域的数据对待判定的数据进行多轮预测(不同邻域抽样),若在多轮预测中预测结果的方差较大,则认定该数据异常,数据异常的识别稳定性更强。
- 还没有人留言评论。精彩留言会获得点赞!