一种基于节点贡献聚类的公平联邦学习方法
本发明涉及计算机应用,尤其涉及一种基于节点贡献聚类的公平联邦学习方法。
背景技术:
1、联邦学习是一种新的机器学习方法,用于分布式数据集进行训练。传统的机器学习方法通过将所有的数据收集到集中的服务器进行训练,这种方式使得所有参与用户的数据面临着严重的隐私泄露问题。联邦学习的基本框架的核心思想就是:数据拥有者之间在不共享原始私有数据的前提下,基于多种加密机制交换和优化模型参数或者梯度,并依赖于中央参数服务器进行聚合维护一个全局共享模型。联邦学习能够使参与用户使用本地的数据进行本地模型训练,在传输的过程中只传输模型参数的更新,避免将原始数据传输到中心服务器中。通过这种方式,联邦学习不仅能实现高效的通信交流和模型训练,为各参与用户提供高质量服务,同时也能够降低隐私泄露的风险。
2、在实际场景中,联邦学习具有不同的公平性描述和定义。根据研究目标的不同,现有的联邦学习公平性研究可以划分为:
3、(1)公平性目标使每个参与客户端的模型具有相同性能(称之为基于平均分配的联邦公平学习)。
4、(2)公平性目标使参与客户端本地模型的性能与其在训练过程中的实际贡献相匹配(称之为基于按劳分配的联邦公平学习)。
5、平均分配的理论旨在使每个参与联邦学习的客户端具有相同的性能。传统的联邦学习并没有考虑公平性的问题,聚合后的模型可能会偏向某些属性或客户端,特别是当客户端的训练数据自身就存在偏见时。这种情况可能会使性能较差的客户端模型越来越差,造成客户端模型之间性能的不平衡。基于平均分配理论的联邦公平学习研究目标是减少客户端之间的差异,同时保持合理的平均性能,通过算法优化等方法以更小的代价保证联邦学习的公平性。平均分配理论的研究目标是减小联邦学习客户端之间的性能差异,促进每个参与者最终模型具有相同的性能,同时还需要在模型精度效率和公平性之间进行权衡。具有代表性的方法是本地训练阶段的模型优化方法和全局聚合阶段的聚合规则修改。然而,在实际情况中通过提高性能较差设备的重要程度来提升其模型性能,从而使所有设备具有相同性能的方法并不能解决联邦学习中所有的公平问题。这类方法没有考虑到贡献度高的客户端,并会潜在地搁置高质量客户端的模型优化和性能,导致贡献高的客户端无法得到公平的对待,最终可能不愿进行数据共享和联邦学习。
6、按劳分配的理论旨在使参与客户端的最终性能与其在联邦学习中的实际贡献相匹配。在实际的数据异构场景中,部分参与者可能促进全局优化过程,而部分参与者可能会损害全局优化过程,导致模型的贡献和性能在不同客户端之间会有很大差异。这种情况下若还是以平均分配理论的思想使每个客户端具有相同的性能,则其对于在训练过程中贡献更多的客户端是不公平的,这样会极大地损害他们参与联邦学习的动力。为此,基于按劳分配的联邦公平学习研究目标是参与客户端最终会获得与其在联邦学习中的实际贡献相匹配的回报。按劳分配理论的研究目标是参与客户端在联邦学习中获得的回报要与它的实际贡献相匹配。具有代表性的方法包括贡献评估机制、公平回报机制和激励机制的设计。然而,在实际情况中按劳分配理论的方法也并不能解决联邦学习中所有的公平问题,因为这类方法会使得性能好的客户端越来越好,导致客户端之间的性能差距越来越大。另外,在当前的贡献评估和回报机制的研究中,初期的评估效果对于整体效果的影响过大。若上一轮在评估中没有获得很好的评价,那么在下一轮训练阶段将会处于劣势,这种劣势将持续下去并逐轮累计。
7、xu等人提出了一种余弦梯度夏普利值(cosinegradientshapleyvalue,cgsv)方法计算客户端的贡献程度,使用客户端本地模型梯度之间的余弦相似度作为实际贡献,并通过理论证明得出余弦相似度能够有效而准确地近似夏普利值。它的核心思想是贡献更多的参与者应该得到更好的奖励。参与节点的贡献和奖励应该是定量的,并且适用于联邦学习的框架中。具体的做法是:在全局聚合的过程中,首先计算每个参与客户端更新的梯度方向与全局模型梯度方向的余弦相似度,根据余弦相似度度量不同客户端的信誉值。按照信誉值的不同决定客户端的聚合权重,并且根据信誉值的大小划分出客户端在本地更新阶段从服务器端下载的参数量,贡献值高的客户端获得更多的参数,从而实现联邦学习的公平性。
8、夏普利值在理想条件下能够有效地评估个体贡献程度,然而在联邦学习这种复杂场景中夏普利值的计算仍存在着问题亟需研究。在实际应用中,即使同样的数据集和参与者,使用不同模型计算得到参与者的夏普利值并不相同。此外,联邦学习每一轮迭代中,服务器会选取部分客户端进行全局聚合,若是其中一个没有被选中,那么即使两个拥有相同数据的客户端可能会收到完全不同的评估夏普利值的计算。
9、此外的夏普利值的方法是在优化计算的效率,然而对于联邦学习公平性中存在的问题仍然不能很好地解决。1.客户端之间的优化冲突。本地模型的更新方向存在着很大的差异,导致客户端优化得到的本地模型更新会偏离服务器聚合得到的全局模型更新,最终模型之间的差异很大,对某些客户来说,模型的准确性可能会显著降低。2.贡献收益机制不公平。每个客户端模型的性能应该与他们在训练过程中的实际贡献相匹配。从直观上看,拥有数量大和质量好数据集的客户端应该能够做出更高的贡献,贡献更多的客户端应该获得更好的回报,若两个客户端对联邦学习训练过程的贡献相同,则它们应该获得相同的回报,根据客户端的实际贡献进行聚合权重的调整和奖励的分配。3.恶意节点的破坏。联邦学习中客户端之间是彼此陌生和不信任的,而全局模型是根据客户端自身上传的模型更新聚合形成的,这就不能避免地会存在自私或恶意破坏的客户端,他们可以通过上传虚假或恶意伪造的更新信息获取或破坏全局模型的更新过程。
技术实现思路
1、本发明的实施例提供了一种基于节点贡献聚类的公平联邦学习方法,用于解决现有技术中存在的问题。
2、为了实现上述目的,本发明采取了如下技术方案。
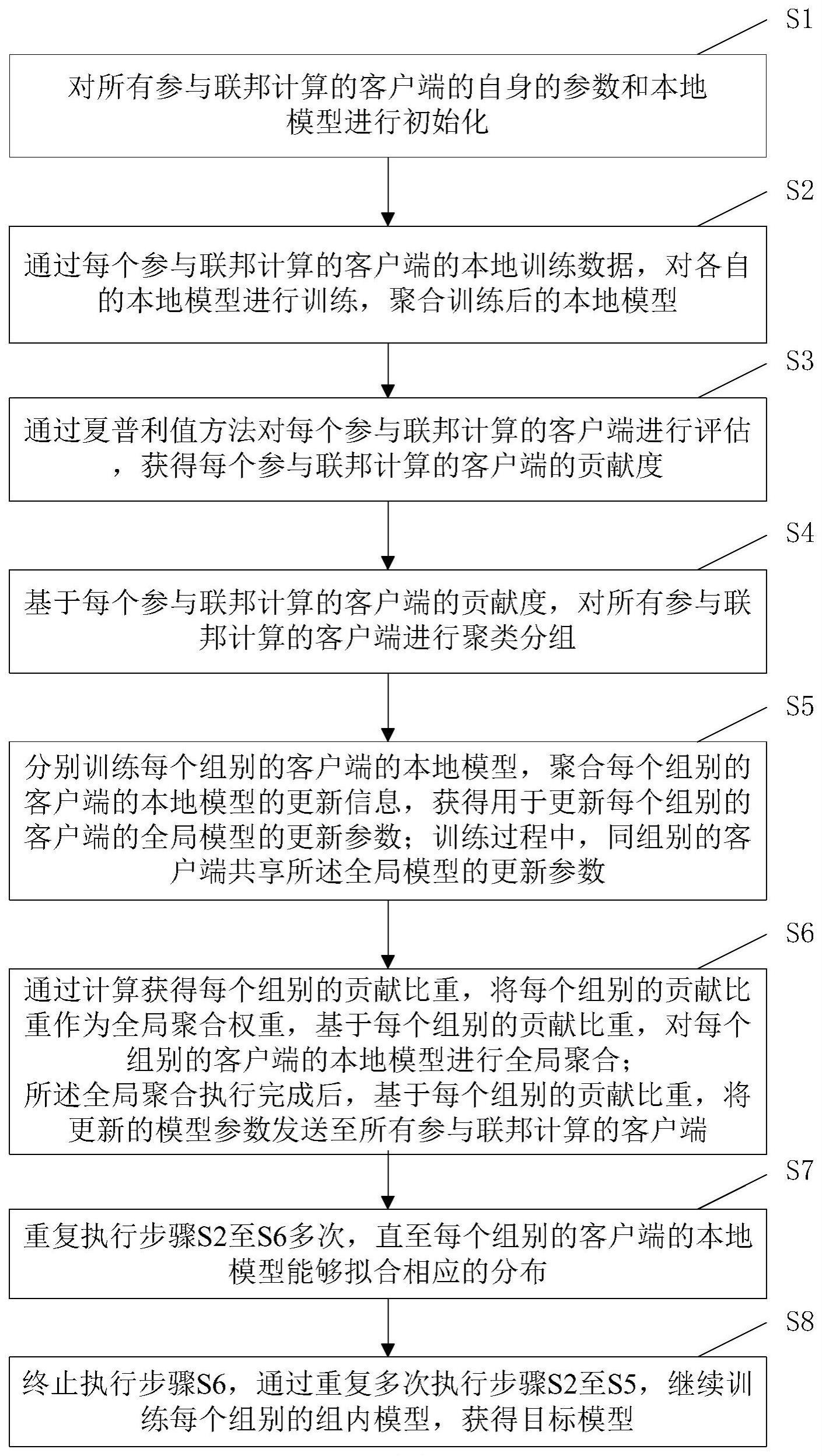
3、一种基于节点贡献聚类的公平联邦学习方法,包括:
4、s1对所有参与联邦计算的客户端的自身的参数和本地模型进行初始化;
5、s2通过每个参与联邦计算的客户端的本地训练数据,对各自的本地模型进行训练,聚合训练后的本地模型;
6、s3通过夏普利值方法对每个参与联邦计算的客户端进行评估,获得每个参与联邦计算的客户端的贡献度;
7、s4基于每个参与联邦计算的客户端的贡献度,对所有参与联邦计算的客户端进行聚类分组;
8、s5分别训练每个组别的客户端的本地模型,聚合每个组别的客户端的本地模型的更新信息,获得用于更新每个组别的客户端的全局模型的更新参数;训练过程中,同组别的客户端共享全局模型的更新参数;
9、s6通过计算获得每个组别的贡献比重,将每个组别的贡献比重作为全局聚合权重,基于每个组别的贡献比重,对每个组别的客户端的本地模型进行全局聚合;全局聚合执行完成后,基于每个组别的贡献比重,将更新的模型参数发送至所有参与联邦计算的客户端;
10、s7重复执行步骤s2至s6多次,直至每个组别的组内模型能够拟合相应的分布;
11、s8终止执行步骤s6,通过重复多次执行步骤s2至s5,继续训练每个组别的组内模型,获得目标模型;
12、目标模型用于发送到一种或多种平台。
13、优选地,步骤s3包括:
14、通过式
15、
16、计算参与联邦计算的客户端i每轮训练本地模型的夏普利值;式中,ut表示第t轮的效用函数,表示每个客户端的本地模型在任何子集上,c是可设置的常数,n表示所有参与联邦计算的客户端的总数;
17、通过式
18、
19、将参与联邦计算的客户端i每轮的夏普利值相加,获得客户端i贡献度si。
20、优选地,步骤s4包括:
21、s41基于每个参与联邦计算的客户端的贡献度,通过式
22、sim(si,sj)=exp(-d(si,sj)2/2σ2) (3)
23、依次计算两个客户端xi和xj之间贡献度si和sj的相似度,根据计算获得的所有客户端之间的相似度,建立相似度矩阵a;式中,d(si,sj)是距离函数,sim表示计算两个客户端xi和xj之间贡献度si和sj的相似度,exp表示以自然常数e为底的指数函数,σ为尺度参数;
24、s42通过式
25、[u s v]=svd(a) (4)
26、对相似度矩阵a进行奇异值分解操作;式中,u、v是相似度矩阵a的左、右奇异向量矩阵,s是相似度矩阵a的奇异值矩阵,s=diag(σ1,σ2...σn);
27、s43将奇异值矩阵s中的(σ1,σ2...σn)依次与预设阈值ρ进行对比,统计大于阈值的个数作为将要分成的组数k;
28、s44根据完成划分的组数k,对客户端依次进行聚类分组,获得聚类分组的结果c1,c2...ck。
29、优选地,步骤s6包括:
30、s61通过式
31、
32、计算客户端i在组内聚合过程中的聚合权重,基于客户端i在全局聚合过程中的聚合权重获得所属组别的贡献比重;式中,fi(θ)是客户端i的本地目标函数,pi是客户端i的全局聚合权重;
33、s62通过式
34、
35、计算每个组别的贡献程度;式中,表示第k个小组的贡献程度,n表示第k个小组内的客户端数量;
36、s63基于全体组别的贡献程度对全体组别进行排序,并按照贡献程度所占的比例将最新的全局模型参数以相应比例依次分发给每个组别的所有客户端中;
37、s64基于每个组别的贡献程度和组模型的更新程度,通过式
38、
39、和
40、
41、计算获得每个组别在全局聚合过程中的聚合权重pk;式中,表示每个组别的贡献占比权重,表示每个组别在训练过程中的模型权重,α和β分别是和的参数,α+β=1;
42、s65判断每个组别全局聚合过程中的贡献程度是否小于预设准入阈值γ,若是,则删除该个组别;
43、s66基于每个组别在全局聚合过程中的聚合权重,对每个组别的客户端的本地模型进行全局聚合。
44、由上述本发明的实施例提供的技术方案可以看出,本发明提供的一种基于节点贡献聚类的公平联邦学习方法,首先根据联邦学习中每个客户端的实际贡献程度进行分组,并将贡献相似的客户端划分为同一组。在每一轮迭代中,首先在每个组的客户端之间进行组内聚合,然后将组内聚合获得的小组模型更新参数上传到服务器端,服务器端对不同组之间的模型进行全局聚合。经过一段时间的全局聚合,每个组基本可以获得其他组的训练信息。此时,可以将全局联邦学习过程划分为组,每个组可以训练自己的个性化组模型,使每个组都能获得与其自身贡献相匹配的公平回报。
45、本发明附加的方面和优点将在下面的描述中部分给出,这些将从下面的描述中变得明显,或通过本发明的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!