一种用于提高自动驾驶三维目标检测效率的检测方法
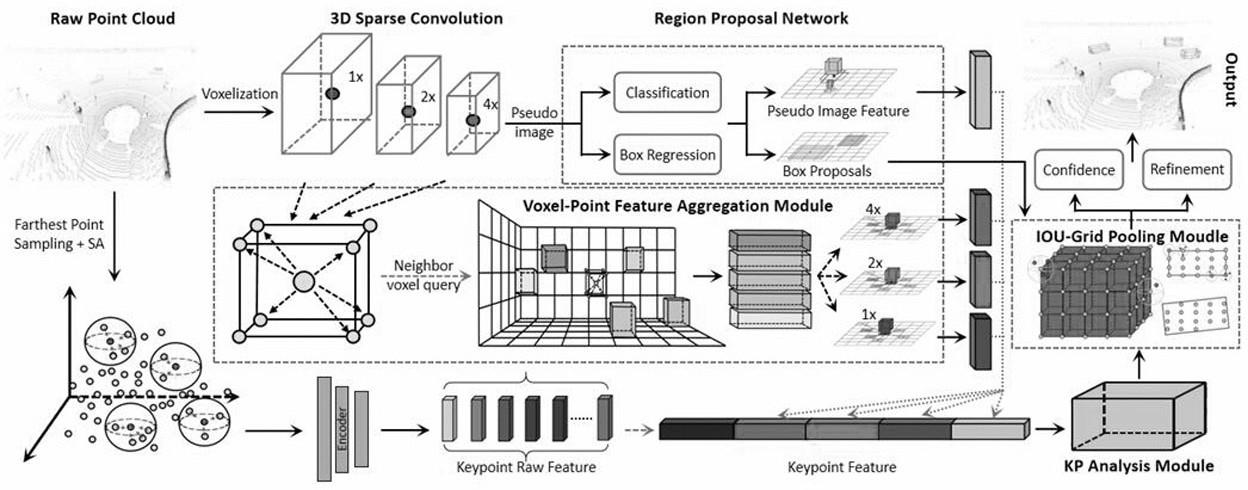
本发明涉及三维目标检测技术,具体涉及一种用于自动驾驶的目标检测方法,尤其是一种通过点云体素融合提高检测效率的三维目标检测方法。
背景技术:
1、利用3d目标检测技术开发的各种模块在自动驾驶、机器人技术和路径规划等领域都扮演着重要的角色。传统的3d目标检测方法将注意力更多地放在由激光雷达传感器获取的原始点云上。虽然原始点云可以提供非常准确的深度信息,但是点云的稀疏性必然会限制其应用领域的拓展。近几年较为热门的研究可以分为三类:基于点云(point)的方法,基于体素(voxel)的方法以及结合点云和体素的方法。这三种方法都需要使用卷积神经网络(cnn)提取3d表示,它们之间的差别在于如何转换目标对象的3d表示。
2、基于point的方法直接将原始点云作为处理对象。它们提取基于点的特征,所以可以提供准确的3d空间表示。以pointnet为基础的一系列方法通过在集合中的变换元素上应用对称运算函数解决原始点云中由无序性带来的问题,而直接从原始点云提取特征必然会带来极大的计算量。为了解决这个问题,现阶段的基于point的方法都采用了两阶段管道(two-stage pipeline)。以point r-cnn为例(参见文献:shaoshuai shi,xiaogang wang,and hongsheng li,“pointrcnn:3d object proposal generation and detection frompoint cloud”,in proceedings of the ieee conference on computer vision andpattern recognition,pages 770–779,2019),它先在第一阶段中通过分割的前景对象估计3d目标提案。然后在第二阶段中使用更精确的基于point的特征对3d提案进行细化以生成最终的预测建议。基于point的方法虽然有着较高的预测性能,但是它们依然无法规避从单个点中提取特征带来的昂贵的计算成本。
3、基于voxel的方法将不规则的点云转换为有序的体素网格,解决了原始点云的稀疏性及不规则性带来的问题。在早期的研究中,点云投影到伪鸟瞰图(bird eye view,bev)中从而得到较为密集的3d表示。这种方式仅能得到精度较高的3d特征,而目标对象的其余信息无法获取。为了解决这个问题,最近的方法都会使用3d卷积从体素表示中提取体素特征。voxelnet(参见文献zhou y,tuzel o.voxelnet:end-to-end learning for pointcloud based 3d object detection[c].proceedings of the ieee conference oncomputer vision and pattern recognition.2018:4490-4499)首先提出将pointnet部署到激光雷达点云中,并提出通过3d卷积层、2d骨干网和检测头联合处理。但它的缺点也十分明显,voxelnet的运行速度很慢。此后出现了一系列的改进以提升运行速度,使得基于体素的方法得到了充分的发展和使用。但是,这些方法依旧受限于分割体素时出现的量化误差。具体来说,基于体素的方法主要有两个缺点:一是大量细粒度的3d结构信息丢失;二是体素网格的大小会极大程度上影响算法的性能。
4、为了同时解决计算成本昂贵和细粒度结构信息丢失问题,最近的方法选择将基于point的方法和基于voxel的方法进行结合。pv r-cnn(参见文献shi s,guo c,jiang l,etal.pv-rcnn:point-voxel feature set abstraction for 3d object detection[c]//proceedings of the ieee/cvf conference on computer vision and patternrecognition.2020:10529-10538),通过加入基于point的特征拓展了second。pv r-cnn同样也是一种投影2d视图的方法,但是它的不同之处在于利用体素集抽象模块获取了多尺度的3d体素特征,并将它们集成到邻近的关键点中。最后每个3d区域提案都会通过roi网格池化提取关键点的特征以进行最终提案的细化。结合point和voxel的检测方法兼顾了基于voxel和基于point方法的优点,但依然无法彻底避免计算量大,计算速度慢及互补信息无法充分利用的问题。并且,这三个方向的方法都存在尺寸歧义(size ambiguity problem)的问题,即这些方法可能会忽略掉提案的边界尺寸,而这会导致在处理一些复杂场景时算法性能的下降。
5、3d目标检测需要在现实复杂3d空间中估计周围目标物体的7个自由度(包括坐标位置,维度及方向)。现阶段大多数3d目标检测方法通过轴对齐的框直接拟合目标对象的方式,而点云的稀疏性会导致3d空间中出现大量无测量值区域,所以仅仅通过输出结果中的一个3d框无法与全局坐标系对齐。而传统的基于anchor的方法会导致拟合旋转对象的方向错误。
6、因此,为了提高三维目标的检测效率以适应自动驾驶的应用需求,需要解决现有技术中存在的计算量大、存在尺寸歧义及角度偏差、生成关键点中存在正负样本不平衡等问题。
技术实现思路
1、本发明的发明目的是提供一种用于提高自动驾驶三维目标检测效率的检测方法,在提高预测精度的同时降低计算量。
2、为达到上述发明目的,本发明采用的技术方案是:一种用于提高自动驾驶三维目标检测效率的检测方法,包括以下步骤:
3、(1)获取待检测的原始点云数据;
4、(2)使用最远点采样法从原始点云中提取一组关键点p,其中的关键点为pi,i是关键点的序号;
5、(3)将需要查询的关键点pi量化为相应体素,然后通过计算关键点周围的非空体素与关键点体素之间的曼哈顿距离,判断该非空体素是否为查询关键点的相邻体素,获得关键点pi的相邻体素特征集其中k表示当前下采样的倍数;
6、(4)计算关键点pi的基于点云(point)的特征与其相邻体素特征集中的基于体素(voxel)的特征的匹配概率,根据匹配概率选择最相似的k个体素特征,并将其与相应的匹配概率聚合,进行特征增强,最后,将k个聚合体素特征通过pointnet-block方法生成关键点pi的特征k为1×、2×、4×;
7、(5)通过将原始点云特征多尺度体素聚合特征以及鸟瞰图特征连接得到原始关键点特征
8、(6)分别计算关键点特征与其相邻原始点云特征多尺度体素聚合特征的特征匹配概率均值,并预测前景概率一起加权初始的关键点特征,得到更新的关键点特征
9、(7)利用一组虚拟网格点均匀分割每一个感兴趣区域(roi),并设置关键点阈值λ和集合抽象半径rg对网格点进行筛选;通过拟合最小包围矩形和加权关键点特征对提案的方向和边界进行修正,得到修正的3d框;
10、(8)重复步骤(3)至步骤(7)直至遍历所有关键点,得到最终三维目标检测结果。
11、上述技术方案中,步骤(3)包括:
12、将3d稀疏卷积获得第k级体素特征集及其对应的实际坐标表示为:
13、
14、其中,i表示第k级中非空体素的个数;
15、以需要查询的关键点作为局部坐标系的原点,并为其周围的非空体素添加3个偏移,即,
16、
17、然后采样曼哈顿阈值dk内的所有非空体素,对于任何一个关键点pi都可以获得一个相邻体素特征集,即:
18、
19、其中,表示语义体素特征的相对位置;kj表示第k级中关键点pi的第j个相邻非空体素;表示语义体素特征与相应关键点之间的曼哈顿距离,
20、
21、上述技术方案中,步骤(4)包括:
22、关键点pi的基于点云(point)的特征与其相邻体素特征集中的基于体素(voxel)的特征的匹配概率为,
23、
24、其中,f(vn,pi)表示关键点pi的第n个基于体素(voxel)的相似特征;
25、根据匹配概率选择最相似的k个体素特征,并将其与相应的匹配概率聚合,最后将k个聚合体素特征通过pointnet-block生成关键点pi的特征,
26、
27、其中,m(·)表示一个用来编码关键点体素特征的多层感知器网络;max(·)表示沿通道最大池化操作。
28、上述技术方案中,步骤(5)中获得的关键点pi的特征为,
29、
30、步骤(6)中,对于任意一个关键点pi可以获得一个相邻的原始点云集合,
31、
32、其中,分别代表了原始点云的基于点云(point)的特征和实际坐标;代表了原始点云的相对位置;rraw表示设定的半径范围;craw,fraw分别表示原始点云的特征集及其对应的实际坐标;n表示相邻原始点云数量;
33、计算关键点pi的基于点云的特征与其相邻的原始点云的基于点云的特征匹配概率的方式如下,
34、
35、通过一个3层的多层感知机网络和sigmod函数获得关键点的特征概率,即关键点属于前景的预测概率通过sa计算关键点与相邻原始点云的特征匹配概率均值通过vpfa分别计算关键点和多个尺度中相邻体素的特征匹配概率均值然后通过平均和加权操作使得来自前景区域关键点的权重提高,经过重新加权的关键点特征表示为:
36、
37、上述技术方案中,步骤(7)包括:
38、对于每一个3d提案,设置在长宽高上都均匀分布的m×m×m个虚拟网格点,并且虚拟网格点的坐标与真实点的坐标是归一化的;然后对每一个虚拟网格点使用sa来选择需要聚合的关键点特征,设定虚拟网格点的关键点阈值λ和集合抽象半径rg,将集合抽象半径以内的所有加权关键点聚合,对于任何一个虚拟网格点gi都可以获得一个相邻加权体素特征集,
39、
40、其中,pj-gi表示相邻加权关键点的相对位置;n'表示相邻加权关键点的总数;
41、如果任意一个网格点gi以rg为半径的球内无法找到λ个加权关键点,则删除该虚拟网格点;
42、设置的虚拟网格点同样分布于提案表面,可以捕获目标提案3d边界框之外,但在集合抽象半径之内的相邻加权特征点;
43、得到每个提案的虚拟网格点集合,
44、g={gm∈r3|m∈[0,m3-1]}
45、然后在虚拟网格点集合中的所有剩余点周围拟合一个最小包围矩形,实现对提案方向及边界的修正,通过将相邻加权体素特征集中的特征进行插值,得到虚拟网格的特征,
46、
47、其中,d(·)表示l2距离;
48、将一个提案中所有虚拟网格点的特征加入网格特征集,并将其通过一个具有[c+3,256,128,128]的通道维数的mlp及全局最大池从而获得每一个提案的roi特征,然后通过另一个mlp获取每个框的交并比(intersection over union)估计,最后通过使用一个2层的多层感知机分别预测目标提案的前景置信度和优化3d框。
49、关键点阈值可以根据经验选取,优选的技术方案,关键点阈值λ=3。
50、由于上述技术方案运用,本发明与现有技术相比具有下列优点:
51、1、本发明针对传统体素-点特征聚合中存在的计算量较大的问题,提出了一个利用偏移和特征匹配概率的特征聚合方法,通过偏移查询邻居体素,并利用体素-关键点匹配概率进行体素特征筛选,提高预测精度的同时降低了计算量。
52、2、针对大量目标检测算法存在的尺寸歧义及角度偏差问题,提出了一个基于虚拟网格点组的池化模块,通过一组均匀分布的虚拟网格点组对生成的边界框提案进行边界和角度优化。
53、3、针对生成关键点中存在的正负样本不平衡问题,提出了一个基于多尺度概率加权的关键点分析模块,通过计算的多尺度中匹配概率的均值,然后加权关键点特征来判断关键点存在于背景还是前景,并最终解决正负样本不平衡问题。
- 还没有人留言评论。精彩留言会获得点赞!