结合CNN和Transformer的多特征融合对联生成方法
本发明涉及对联自动生成,具体涉及结合cnn和transformer的多特征融合对联生成方法。
背景技术:
1、对联拥有悠久的历史,对联结构对仗语言对应极具特点,自古就受到人们的喜爱,但对联的创作需要一定的文学基础,一般人很难轻松创作对联,所以对于自动创作对联的研究慢慢兴起,研究对联自动创作一方面降低了创作的难度,一方面促进了中文生成任务的研究。
2、现有对联自动生成方法包括:基于规则模板的方法、基于进化算法的方法、基于统计机器翻译的方法和基于深度学习的方法。
3、基于规则模板的方法通过人为设置的创作背景和创作条件生成对联,生成的对联健壮性差,对联形式和内容过于机械呆板。
4、基于进化算法的方法通过进化算法生成对联,生成的对联的质量较好,但对联生成过程需要耗费大量时间和空间,工作效率低耗费资源多。
5、基于统计机器翻译的方法通过大量语料进行匹配翻译进而生成对联,该方法需要语料进行自动学习,生成的对联质量也受语料库的规模和质量限制。
6、基于深度学习的方法通过深度学习知识生成对联,生成的对联质量高,但该方法也存在生成文本对仗不严谨、语义不连贯等问题。
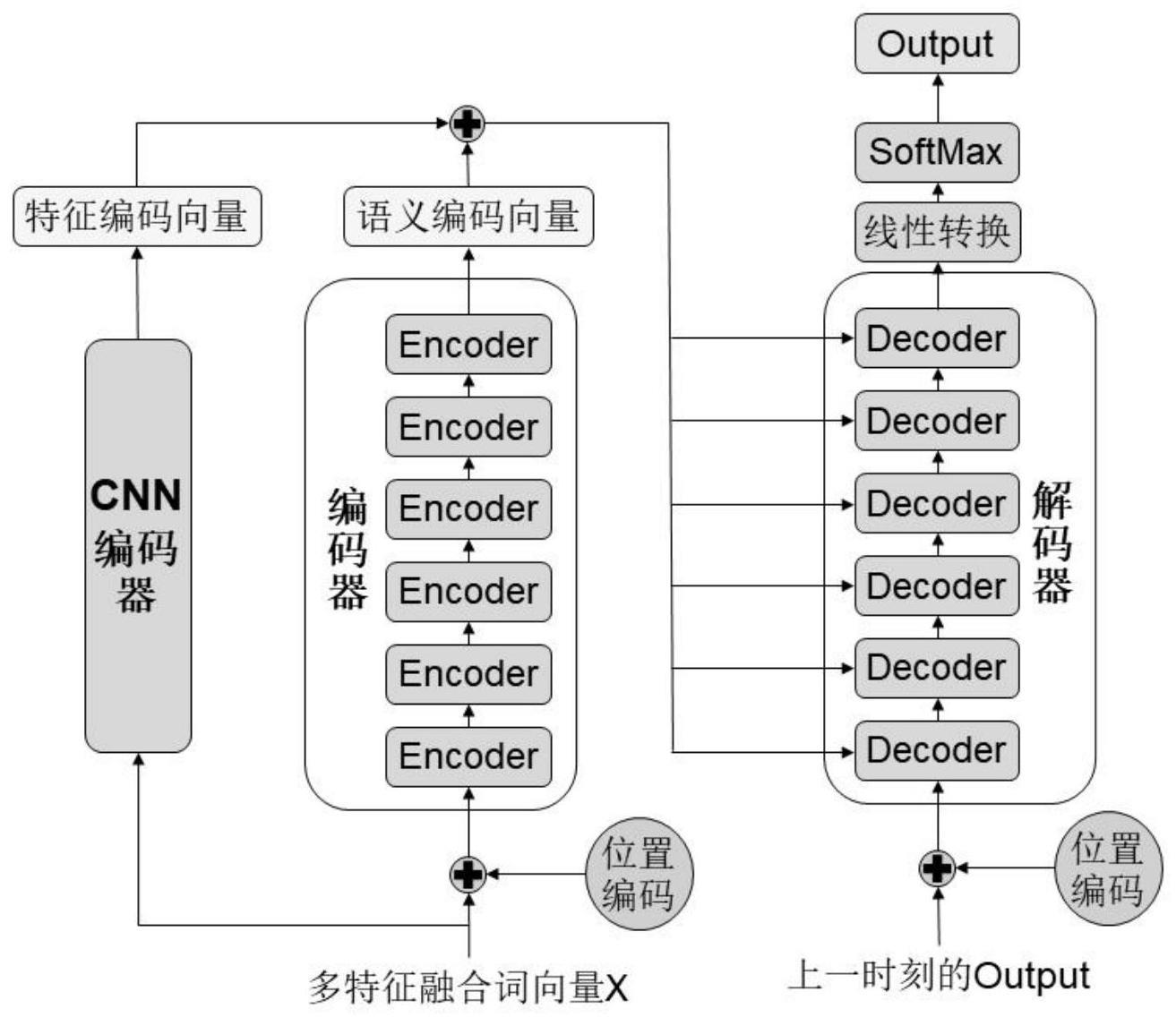
7、结合cnn和transformer的多特征融合对联生成方法是一种基于深度学习的方法,将对联的词性特征和平仄特征加入到词向量中,得到多特征融合的词向量,将该词向量作为cnn和transformer的输入,最后transformer预测输出对联下联。多特征融合的词向量能提高生成对联的对仗性;将cnn模型和transformer模型结合起来,强化对联的重点信息,提高生成对联的语义连贯性。
技术实现思路
1、本发明的目的是解决现存对联生成方法中存在的生成下联对仗不严谨、语义不连贯的问题,通过提供一种结合cnn和transformer的多特征融合对联生成方法来实现。
2、本发明采用的技术方案为一种结合cnn和transformer的多特征融合对联生成方法,包括以下步骤:
3、步骤1.在数据预处理阶段,分别构建带词性特征和平仄特征的对联语料库;
4、步骤2.根据对联上联构建结合词性特征和平仄特征的多特征融合词向量。
5、步骤3.将对联上联的多特征融合词向量分别输入到cnn编码器和transformer模型的编码器中进行对联特征提取和对联语义编码,分别得到特征编码向量和语义编码向量。
6、步骤4.将特征编码向量和语义编码向量结合起来输入到transformer模型的解码器中。
7、步骤5.transformer模型的解码器根据对联语料库预测并输出下联。
8、进一步,步骤1中分别构建带词性特征和平仄特征的对联语料库具体如下:
9、s11.获取对联语料库;
10、s12.对对联语料库里的对联数据进行逐字分词;
11、s13.采用ltp(language technology platfor)对分词后的对联语料进行词性特征标注,得到具有词性特征的对联语料库;
12、s14.采用python中的pypinyin对分词后的对联语料进行拼音标注,然后根据拼音音调与平仄音调的转换规则将拼音转换成为平仄特征,得到具有平仄特征的对联语料库。
13、其中拼音音调与平仄音调的转换规则为:拼音音调的一二声为平声,拼音音调的三四声为仄声。
14、进一步,步骤2中多特征融合词向量构建过程如下:
15、s21.对对联上联进行逐字分词;
16、s22.根据分词后的上联数据构建语义向量;
17、s23.采用ltp对分词后的上联的每个字进行词性特征标注,然后根据标注有词性特征的上联数据构建词性特征向量;
18、s24.采用pypinyin对分词后的上联的每个字进行拼音标注,然后根据拼音音调与平仄音调的转换规则将拼音转换成为平仄特征,得到标注有平仄特征的对联上联数据,最后根据标注有平仄特征的对联上联数据构建平仄特征向量;
19、s25.将语义向量、词性特征向量和平仄特征向量按照一定维度先后拼接起来,得到多特征融合词向量。
20、设定多特征融合词向量的向量矩阵表示为x=[x1,x2,…xi]t,其中xi是对联上联句子分词后每个词语的词向量,xi=[xii1,xii2,…xiin],其中ii是对联上联句子分词后的词语个数,n是词向量维度。
21、进一步,步骤3中cnn编码器结构及特征编码向量生成过程如下:
22、cnn编码器由两个卷积层、一个池化层和一个全连接层构成。
23、两个卷积层采用不同尺寸的卷积核wk进行特征编码。第一层卷积层采用多个1×1卷积核w1×1扩充神经网络深度和加强非线性,进而增强网络的表达能力;第二层卷积层采用多个不同尺寸的卷积核wk对对联句子进行特征提取,分别是:w2×n∈r2×n、w3×n∈r3×n和w4×n∈r4×n,其中卷积核的宽度与输入的对联句子矩阵x中每个词语的词向量的维度一致,这是为了保证每一次卷积操作都能对每个词语的完整的词向量进行扫描,避免出现词语特征缺失的情况。
24、第一层卷积层采用多个卷积核w1×1对输入矩阵x进行卷积操作,输出的特征图c与输入矩阵x的形状一致,第二层卷积层采用多个不同尺寸的卷积核w2×n、w3×n和w4×n对第一层卷积层输出的特征图c进行卷积操作,得到特征图c*,然后将特征图c*输入到池化层中,分别进行最大池化操作和平均池化操作,得到最具代表性的特征,平均池化操作使得到的特征更全面,将最大池化操作和平均池化操作得到的特征值进行融合,将所有融合的特征值进行拼接得到特征融合向量,最后经过一个全连接层生成最终的特征编码向量。
25、第一层卷积层使用1×1卷积核w1×1对矩阵x进行卷积操作,每个卷积核在单词窗口xi:i+j-1上生成的特征值cl的计算公式为:
26、cl=relu(w1×1xi:i+j-1+b) (1)
27、relu=max(0,x)(2)
28、其中,i表示矩阵x的行,j表示卷积核的高,b为偏置项。当卷积核w1×1将整个对联句子矩阵x遍历完成后,每个卷积核都会输出包含多个特征值cl的特征图c,特征图c的尺寸与矩阵x一致。
29、第二个卷积层中使用多个卷积核w2×n、w3×n和w4×n对特征图c进行卷积操作,每个卷积核在特征图窗口ci:i+j-1上生成的特征值cp的计算公式为:
30、cp=relu(wkci:i+j-1+b) (3)
31、其中,i表示矩阵x的行也表示为特征图c的高,j表示卷积核的高,b为偏置项。当卷积核wk将整个特征图c遍历完成后,每个卷积核都会输出包含多个特征值cp的特征图c*,特征图c*的尺寸为(i-j+1)×1。
32、将得到的特征图c*传给池化层,池化层对特征图c*进行最大池化操作和平均池化操作,计算公式如下:
33、
34、
35、公式(4)是最大池化操作,公式(5)是平均池化操作,最大池化操作和平均池化操作的窗口的尺寸均为(i-j+1)×1,与特征图c*的尺寸一致,所以经过池化操作后得到的最大特征值和平均特征值的尺寸均为1×1。
36、将最大特征值和平均特征值进行融合得到特征值公式如下:
37、
38、其中,9(·)代表融合操作,本文采取直接相加的融合方式。
39、将所有特征图c*进行如上池化操作后,把所有得到的特征值并接成一个特征融合向量e,特征融合向量e的维度为1×v,v代表一个卷积层中所有卷积核的个数,假设卷积核w2×n、w3×n和w4×n的数量都为10,则v=10×3=30。
40、将特征融合向量e输入到一个全连接层中,生成特征编码向量z:
41、z=relu(ew+b) (7)
42、其中,w是权重参数,b是偏置项,z的维度为1×n,n表示输入矩阵x中每个词语的词向量维度。
43、进一步,步骤4中特征编码向量和语义编码向量结合计算如下:
44、语义编码向量由transformer模型的编码器计算得到,是矩阵形式,包含所有上联句子词向量的编码信息。将语义编码向量和特征编码向量直接相加,公式如下:
45、
46、
47、id=[id1、id2、…、idi]t (10)
48、其中,wh和wz是权重参数,i是对联句子分词后的词语个数。id是语义编码向量和特征编码向量融合后的新向量,维度与一致。
49、本发明的有益效果:提供一种结合cnn和transformer的多特征融合对联生成方法,引入多特征融合词向量,能加强对联的队长性;将cnn模型和transformer模型结合起来对对联上联数据进行处理,强化了对联的重点信息,提高生成对联的语义连贯性。
- 还没有人留言评论。精彩留言会获得点赞!