基于视频理解的手术器械、操作和组织智能识别方法
本发明涉及微创手术行为识别,具体涉及一种基于视频理解的手术器械、操作和组织智能识别方法。
背景技术:
1、微创手术通常在患者体表切开较小的创口,并基于内窥镜等成像设备的引导,完成手术操作。目前微创手术主要采用内镜,将内镜视频呈现在显示器上供医生观察。而微创手术行为识别是指在内镜视频中识别出何种器械正在对何种组织实施何种操作,进而识别手术中的细粒度行为。
2、现有的手术行为识别方法通常是对器械、操作、目标进行独立识别,随后再将识别结果融合得到行为识别结果。
3、但现有技术未能考虑器械、操作、目标之间的关联关系,识别性能存在缺陷。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术的不足,本发明提供了一种基于视频理解的手术器械、操作和组织智能识别方法,解决了现有技术识别性能低的问题。
3、(二)技术方案
4、为实现以上目的,本发明通过以下技术方案予以实现:
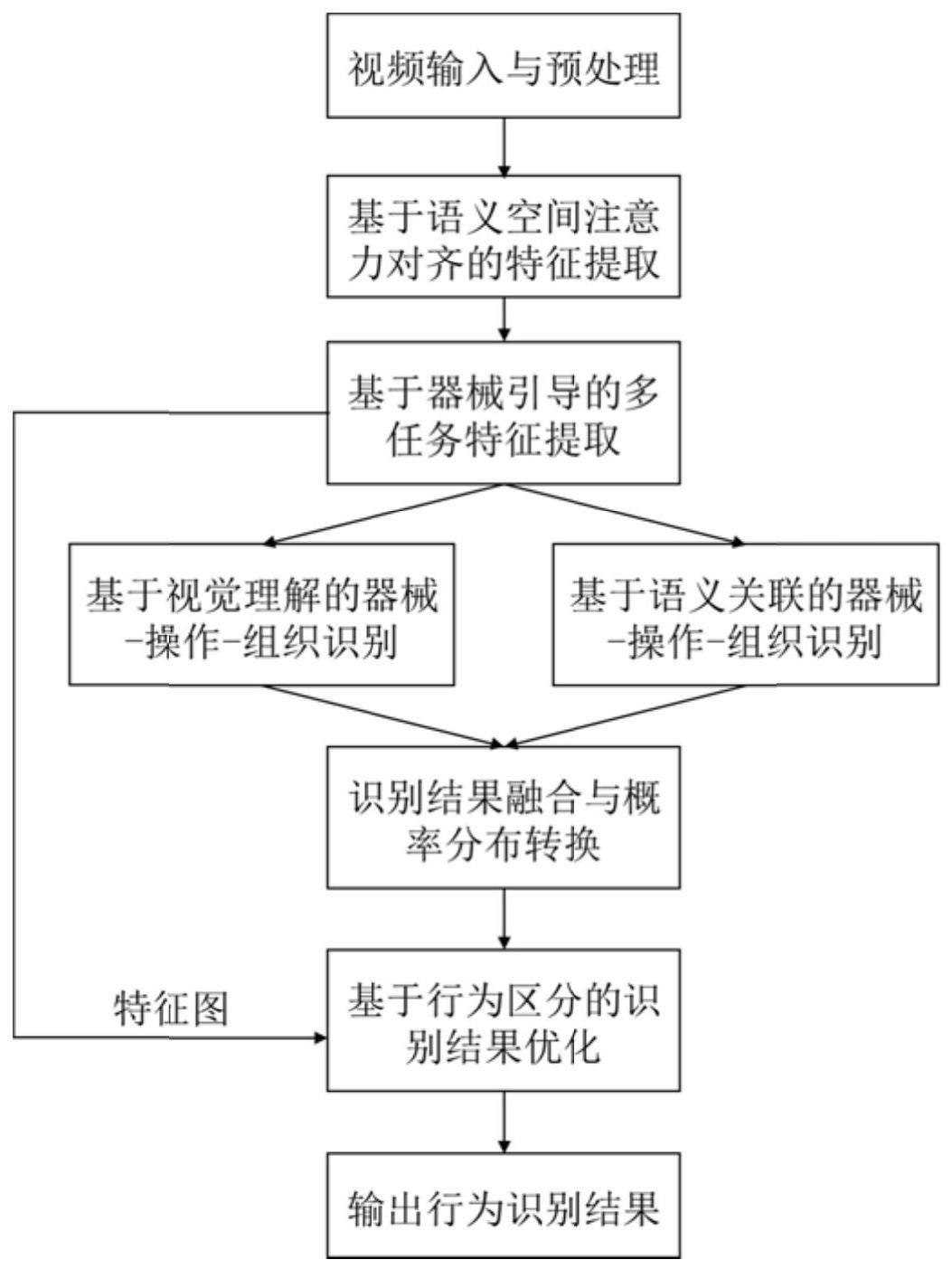
5、一种基于视频理解的手术器械、操作和组织智能识别方法,该方法包括:
6、获取内镜视频的视频帧特征图和对应的语义特征;
7、基于视频帧特征图获取对应的器械视觉识别概率、操作视觉识别概率和组织视觉识别概率;并基于语义特征获取器械关联识别概率、操作关联识别概率和组织关联识别概率;
8、融合各视觉识别概率和对应的关联识别概率获取器械识别概率、操作识别概率和组织识别概率;并基于器械识别概率、操作识别概率和组织识别概率获取三元组标签分类概率。
9、进一步的,所述获取内镜视频的视频帧特征图和对应的语义特征,包括:
10、对内镜视频进行预处理,得到符合预设分辨率的视频帧;
11、将视频帧作为特征提取网络的输入,得到视频帧特征图和对应的语义特征,
12、其中,所述视频帧特征图通过卷积网络进行提取;
13、所述语义特征通过图卷积网络进行提取。
14、进一步的,所述卷积网络和图卷积网络均包含若干个子网络;
15、且卷积网络的每层子网络输出的特征图和图卷积网络的每层子网络输出的语义特征输入空间语义注意力对齐模块,并将空间语义注意力对齐模块输出的特征图和对应的语义特征作为下一层子网络的输入。
16、进一步的,空间语义注意力对齐模块输出特征图和对应的语义特征,包括:
17、通过卷积层和全连接层获取隶属度矩阵,再令隶属度矩阵分别经过softmax操作和二维平均池化avgpool操作获取空间注意力和通道注意力;最后通过残差连接将空间注意力融合进特征图,并将通道注意力融合进语义特征。
18、进一步的,所述基于视频帧特征图获取对应的器械视觉识别概率、操作视觉识别概率和组织视觉识别概率,包括:
19、从视频帧特征图中提取器械特征图,并从中提取器械分类特征;
20、将视频帧特征图与器械特征图进行拼接,再从中提取操作特征图和组织特征图,再从中提取操作分类特征和组织分类特征;
21、基于器械分类特征、操作分类特征和组织分类特征获取对应的器械视觉识别概率、操作视觉识别概率和组织视觉识别概率。
22、进一步的,基于语义特征获取器械关联识别概率、操作关联识别概率和组织关联识别概率,包括:
23、从语义特征获取器械语义特征、操作语义特征、组织语义特征;
24、基于器械语义特征、操作语义特征、组织语义特征和对应的分类特征获取对应的器械关联识别概率、操作关联识别概率和组织关联识别概率。
25、进一步的,所述方法还包括:
26、将器械特征图、动作特征图与组织特征图在通道维拼接;再将拼接后的特征图输入到三元组卷积网络提取三元组特征图,通过二维平均池化操作得到三元组特征,将三元组特征输入三元组全连接分类器获取三元组调整分数,基于三元组调整分数和三元组标签的概率可计算得到最终的三元组识别概率;且采用度量学习进行训练。
27、进一步的,器械、操作和组织识别以及三元组标签识别的损失函数均采用二元交叉熵损失。
28、进一步的,输入图卷积网络的共现频率矩阵的获取方法为:将标签按照器械、操作、组织的顺序排列,获取训练集中的各标签的共现频率矩阵,并对其进行归一化。
29、进一步的,所述器械特征图、操作特征图和组织特征图均采用卷积网络进行提取。
30、(三)有益效果
31、本发明提供了一种基于视频理解的手术器械、操作和组织智能识别方法。与现有技术相比,具备以下有益效果:
32、1.本发明基于多任务学习,能够同时识别器械、操作和组织。利用了器械特征图引导操作与组织特征图的提取,基于器械识别准确度高、稳定性强的特点,提高了识别的稳定性。
33、2.本发明充分利用手术先验知识,通过图卷积网络在语义层面上显式建模了器械、操作、组织的关联关系,这种关联关系通过空间语义注意力对齐模块进一步嵌入到图像特征提取网络和语义特征提取网络中,最终融合了视觉识别结果与关联识别结果,提升了识别的准确性。
34、3.本发明采用度量学习对三元组特征进行区分,并优化识别结果,显著降低了手术内镜视频中同时出现多个三元组时的误识别概率。
技术特征:
1.一种基于视频理解的手术器械、操作和组织智能识别方法,其特征在于,该方法包括:
2.如权利要求1所述的一种基于视频理解的手术器械、操作和组织智能识别方法,其特征在于,所述获取内镜视频的视频帧特征图和对应的语义特征,包括:
3.如权利要求2所述的一种基于视频理解的手术器械、操作和组织智能识别方法,其特征在于,所述卷积网络和图卷积网络均包含若干个子网络;
4.如权利要求3所述的一种基于视频理解的手术器械、操作和组织智能识别方法,其特征在于,空间语义注意力对齐模块输出特征图和对应的语义特征,包括:
5.如权利要求1所述的一种基于视频理解的手术器械、操作和组织智能识别方法,其特征在于,所述基于视频帧特征图获取对应的器械视觉识别概率、操作视觉识别概率和组织视觉识别概率,包括:
6.如权利要求1所述的一种基于视频理解的手术器械、操作和组织智能识别方法,其特征在于,基于语义特征获取器械关联识别概率、操作关联识别概率和组织关联识别概率,包括:
7.如权利要求5所述的一种基于视频理解的手术器械、操作和组织智能识别方法,其特征在于,所述方法还包括:
8.如权利要求1所述的一种基于视频理解的手术器械、操作和组织智能识别方法,其特征在于,器械、操作和组织识别以及三元组标签识别的损失函数均采用二元交叉熵损失。
9.如权利要求2所述的一种基于视频理解的手术器械、操作和组织智能识别方法,其特征在于,输入图卷积网络的共现频率矩阵的获取方法为:将标签按照器械、操作、组织的顺序排列,获取训练集中的各标签的共现频率矩阵,并对其进行归一化。
10.如权利要求1所述的一种基于视频理解的手术器械、操作和组织智能识别方法,其特征在于,所述器械特征图、操作特征图和组织特征图均采用卷积网络进行提取。
技术总结
本发明提供了一种基于视频理解的手术器械、操作和组织智能识别方法,涉及微创手术行为识别技术领域。本发明基于多任务学习,能够同时识别器械、操作和组织。利用了器械特征图引导操作与组织特征图的提取,基于器械识别准确度高、稳定性强的特点,提高了识别的稳定性。同时充分利用手术先验知识,通过图卷积网络在语义层面上显式建模了器械、操作、组织的关联关系,这种关联关系通过空间语义注意力对齐模块进一步嵌入到图像特征提取网络和语义特征提取网络中,最终融合了视觉识别结果与关联识别结果,提升了识别的准确性。最后采用度量学习对三元组特征进行区分,并优化识别结果,显著降低了手术内镜视频中同时出现多个三元组时的误识别概率。
技术研发人员:杨宇轩,王浩,丁帅,苏伊阳,李诗惠
受保护的技术使用者:合肥工业大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!