时序数据环境分析及决策方法、装置、设备及存储介质与流程
本发明涉及金融科技及人工智能,尤其涉及一种时序数据环境分析及决策方法、装置、电子设备及可读存储介质。
背景技术:
1、随着数据获取及处理能力的发展,强化学习在视觉、听觉、翻译、游戏等领域取得了很多成功应用。这类决策问题涉及的决策变量、决策空间有限,决策环境平稳,不确定因素可控。然而,现实自然社会中的决策问题存在映射关系复杂、决策空间巨大、决策环境随时间变化大、不确定因素多等特点,导致现有强化学习算法在复杂决策领域中的表现仍不理想,例如重大灾害救援领域,大型系统突发故障诊断(如高铁运行、供电系统)等;金融领域市场时序指标分布状态突变等风险预测防控问题。此外,这类复杂决策问题还存在可学习样本稀缺(样本来自自然事件、市场突变等,不受人类控制,或者采集成本极大),容错程度低(一旦决策失败,损失重大)等问题。
2、以下为结合实际应用案例具体描述现有的强化学习算法在这些场景中面临的问题:
3、1. 映射关系复杂/决策空间巨大:目前最被熟知且广泛应用的人工智能技术是深度学习。而深度学习的输入输出边界都比较固定。例如深度学习ocr文字识别,其任务是将文字目标由图像与文字本身建立链接。其输入是范围在0~255之间的张量,对应输出则是文本字符集合中的唯一一个。而以诸如金融领域时序数据预测、气象灾害预测、轨道交通突发故障防控等为例的时间序列决策建模,决策变量可能是市场指标图、卫星云图、雷达及高空探测等图像,以及窗口期内温度、降水等序列指标,状态边界极为开放,用相同的数据驱动的方法进行训练,其模型参数值会在巨大的探索空间中震荡,难以收敛。而在超高维状态空间中确定模型参数,建立准确的映射非常困难得到的模型在样本外预测,经常出现过拟合问题。
4、2. 规律/数据分布时变性高:在自然界中,高维时间序列的各变量之间的关系错综复杂,决策目标值与状态变量之间的关系经常呈周期性变化,或因突发刺激产生突变;在指标统计领域,很多指标时间序列数据也具有规律时变特性,并且因为影响因素多而难以预测。这些现实问题的决策目标可能随任意一个或几个特征值的短时变化产生巨大的波动,具有高度时变性。相较而言,深度学习任务则不具备这一特点,反观诸如市场波动预警、自然灾害监控预警、疾病预防、自动驾驶等时序指标监控预警问题,如果将其是为一个随机过程,其状态转移具有极高的不确定性,在这一过程中进行决策,直接使用相同的强化学习算法框架无法有效应对这一问题。
5、3. 专业领域数据稀缺:在取得突破的人工智能技术领域,无论是深度学习使用的图片、语料等训练集,还是通过电脑游戏为强化学习算法提供采样,数据量都是十分丰富的。相比之下,实际生产时间中,在任何一个时间截面,数据量是有限且固定的。因此,数据变得极为稀缺。
6、现有技术中,基于环境学习的强化学习算法框架主要在以下问题。
7、(1)这些算法模型可以在稳定环境中学习最佳决策,但是对环境的时变性有很高的要求,往往难以应对复杂的任务和模型的不确定性。例如q学习(q learning)算法的方法是比较经典的学习算法之一,但难以推广到不同的未知环境,非稳定环境中状态的微小变化也会导致下一步预测不准确,反过来又会导致动作规划不合理,最终导致算法性能下降,使得算法框架在现实部署中变得不可靠。近几年引入的元学习策略算法虽然能解决这一挑战,但通常会遇到在线策略学习的采样效率低下或离线策略学习的元过度拟合等问题。随后进一步改进的pearl(probabilistic embeddings foractor-critic meta-rl,策略-价值网络的概率嵌入)和maml(model-agnosticmeta-learning ,模型无关的元学习)等算法即使能适应少数试验中的任务,但都严重限于狭窄的任务分布,这使得它们只应用于参数环境,无法适用于非稳定环境。因此,现有基于环境学习的强化学习算法框架还无法有效应对在自动驾驶、监控预警、市场运行突变、机器人应用等诸多现实问题。
8、(2)主流acto-critic强化学习框架强依赖样本量,且难以与专家知识融合。一方面,该框架中actor策略网络需要通过价值网络对价值函数拟合生成,critic价值网络的生成依赖于actor通过执行动作与决策环境并获取奖励值,算法训练需要大量质量较好的学习样本。此外,该算法中策略网络和价值网络需要随机初始化,奖励值在训练初始阶段具有高噪声,critic难以使用这些高噪声奖励对价值函数的拟合进行优化,更无法指导actor有效优化。另一方面,actor预测性能的起点近似于随机抽样,很难快速积累正向奖励,也导致这种训练方式很难使得actor接受人类知识指导,因此在决策空间较大时模型参数往往陷入鞍点或局部最优,收敛不稳定,实际预测效果差。
技术实现思路
1、本发明提供一种时序数据环境分析及决策方法、装置、电子设备及可读存储介质,其主要目的在于可以提高时序数据环境分析及决策的准确性。
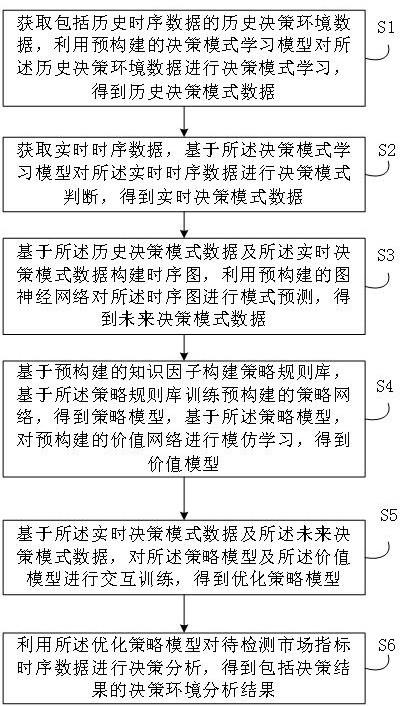
2、为实现上述目的,本发明提供的一种时序数据环境分析及决策方法,包括:
3、获取包括历史时序数据的历史决策环境数据,利用预构建的决策模式学习模型对所述历史决策环境数据进行决策模式学习,得到历史决策模式数据;
4、获取实时时序数据,基于所述决策模式学习模型对所述实时时序数据进行决策模式判断,得到实时决策模式数据;
5、基于所述历史决策模式数据及所述实时决策模式数据构建时序图,利用预构建的图神经网络对所述时序图进行模式预测,得到未来决策模式数据;
6、基于预构建的知识因子构建策略规则库,基于所述策略规则库训练预构建的策略网络,得到策略模型,基于所述策略模型,对预构建的价值网络进行模仿学习,得到价值模型;
7、基于所述实时决策模式数据及所述未来决策模式数据,对所述策略模型及所述价值模型进行交互训练,得到优化策略模型;
8、利用所述优化策略模型对待检测市场指标时序数据进行决策分析,得到包括决策结果的决策环境分析结果。
9、可选地,所述利用预构建的决策模式学习模型对所述历史决策环境数据进行决策模式学习,得到历史决策模式数据,包括:
10、利用所述决策模式学习模型中的决策目标函数构建所述历史决策环境数据的序列划分点;
11、基于所述序列划分点对所述历史决策环境数据进行序列划分,得到历史决策模式数据。
12、可选地,所述基于所述决策模式学习模型对所述实时时序数据进行决策模式判断,得到实时决策模式数据,包括:
13、基于所述决策模式学习模型及预设的滑动时间窗口对所述实时时序数据进行决策模式判断,得到不同滑动时间窗口对应的实时决策模式数据。
14、可选地,所述基于所述历史决策模式数据及所述实时决策模式数据构建时序图,利用预构建的图神经网络对所述时序图进行模式预测,得到未来决策模式数据,包括:
15、基于预设的数据结构从所述历史决策模式数据及所述实时决策模式数据中提取定量指标序列,基于预设的关系规则从所述历史决策模式数据及所述实时决策模式数据提取关系网络;
16、汇总所述定量指标序列及所述关系网络得到所述时序图;
17、利用所述图神经网络对所述时序图进行环境预测,得到未来决策环境数据;
18、基于所述决策模式学习模型对所述未来决策环境数据进行模式预测,得到未来决策模式数据。
19、可选地,所述基于所述策略规则库训练预构建的策略网络,得到策略模型,包括:
20、将所述策略规则库中的数据划分为目标序列及多个特征序列,利用所述策略网络中嵌入注意力机制的编码器对所述多个特征序列进行贡献度打分,得到贡献度打分结果;
21、基于所述贡献度打分结果,利用所述策略网络中嵌入注意力机制的解码器对所述目标序列进行预测,得到预测结果,返回所述将所述策略规则库中的数据划分为目标序列及多个特征序列的步骤,直至满足预设的训练条件,得到所述策略模型。
22、可选地,所述基于所述策略模型,对预构建的价值网络进行模仿学习,得到价值模型,包括:
23、将所述策略模型中的网络参数权重复制到所述价值网络中,得到初始化价值网络;
24、获取基于所述策略规则库构造的历史时序训练集合,利用所述初始化价值网络对所述历史时序训练集合中的数据进行预测,得到时序预测结果;
25、基于所述时序预测结果计算预测奖励值,利用所述预测奖励值计算损失值;
26、在所述损失值不满足预设的损失阈值时,调整所述初始化价值网络中的参数,返回所述利用所述初始化价值网络对所述时序训练集合中的数据进行预测的步骤,直至所述损失值满足预设的损失阈值时,得到所述价值模型。
27、可选地,所述基于所述实时决策模式数据及所述未来决策模式数据,对所述策略模型及所述价值模型进行交互训练,得到优化策略模型,包括:
28、基于所述决策模式学习模型从所述实时决策模式数据及所述未来决策模式数据中抽取样本三元组;
29、基于所述样本三元组,利用所述价值模型对所述策略模型进行联合价值训练,并计算所述决策模式学习模型的决策损失,以及计算所述策略模型及所述价值模型的交互损失;
30、基于所述决策损失及所述交互损失计算联合价值损失,在所述联合价值损失不满足预设的联合训练条件时,更新所述决策模式学习模型、所述策略模型及所述价值模型中的模型参数,返回所述基于所述样本三元组,利用所述价值模型对所述策略模型进行联合价值训练的步骤,直至所述联合价值损失满足预设的联合训练条件时,将训练完成的策略模型作为优化策略模型。
31、为了解决上述问题,本发明还提供一种时序数据环境分析及决策装置,所述装置包括:
32、决策模式学习模块,用于获取包括历史时序数据的历史决策环境数据,利用预构建的决策模式学习模型对所述历史决策环境数据进行决策模式学习,得到历史决策模式数据,获取实时时序数据,基于所述决策模式学习模型对所述实时时序数据进行决策模式判断,得到实时决策模式数据,基于所述历史决策模式数据及所述实时决策模式数据构建时序图,利用预构建的图神经网络对所述时序图进行模式预测,得到未来决策模式数据;
33、模仿学习模块,用于基于预构建的知识因子构建策略规则库,基于所述策略规则库训练预构建的策略网络,得到策略模型,基于所述策略模型,对预构建的价值网络进行模仿学习,得到价值模型;
34、模型优化及预测模块,用于基于所述实时决策模式数据及所述未来决策模式数据,对所述策略模型及所述价值模型进行交互训练,得到优化策略模型,利用所述优化策略模型对待检测市场指标时序数据进行决策分析,得到包括决策结果的决策环境分析结果。
35、为了解决上述问题,本发明还提供一种电子设备,所述电子设备包括:
36、存储器,存储至少一个计算机程序;及
37、处理器,执行所述存储器中存储的计算机程序以实现上述所述的时序数据环境分析及决策方法。
38、为了解决上述问题,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一个计算机程序,所述至少一个计算机程序被电子设备中的处理器执行以实现上述所述的时序数据环境分析及决策方法。
39、本发明通过预构建的决策模式学习模型对历史决策环境数据进行决策模式学习总结,对未来决策模式数据进行预测,提高了决策环境预测在真实环境的有效性,通过决策环境的自学习与适配,可以基于决策环境的变化而更新,避免决策环境突变,提高了决策环境预测的准确性。同时,基于预构建的知识因子构建策略规则库,基于策略规则库训练预构建的策略网络,得到策略模型,基于所述策略模型,对预构建的价值网络进行模仿学习,得到价值模型,通过引入领域知识及决策规则使得模型训练训练样本的依赖程度大幅降低,提高模型训练效率及准确率。并且,通过历史真实数据及价值模型,对策略模型进行交互优化,可以不断提高策略模型训练的速度及稳健性,进一步提高预测结果。因此本发明提出的时序数据环境分析及决策方法、装置、电子设备及计算机可读存储介质,可以提高时序数据环境分析及决策的准确性。
- 还没有人留言评论。精彩留言会获得点赞!