基于图片相似度的代码克隆检测方法、系统及存储介质
本发明属于源代码克隆检测领域,更具体地,涉及一种基于图片相似度的代码克隆检测方法、系统及存储介质。
背景技术:
1、代码克隆检测作为衡量代码复用的一种有效方式,在软件开发、维护以及质量保证中发挥着重要作用。不好的代码复用方式会对整个软件系统的开发和维护带来很多不利因素,因此高效且准确的代码克隆检测是亟需解决的痛点问题。
2、目前主流的代码克隆检测可以分为大规模克隆检测和语义克隆检测两类。大规模克隆检测主要采用基于文本和基于令牌的方式实现,通过直接将代码片段转换为文本或令牌序列,然后进行相似度比较,检测时间较短,但缺乏对代码语义信息的考虑。
3、现有的语义克隆检测主要包括基于图和基于树的检测方法。基于图的检测方法,程序依赖的图(pdg)和控制流图(cfg)都具有复杂的结构,导致对其相似度匹配的时间开销巨大;此外,生成准确的图形表示一般需要代码编译,这导致基于图的方法对某些代码片段(例如单个函数、代码片段)的检测有限。基于树的克隆检测方法中树表征的结构也非常复杂,仍然会导致匹配的时间开销过大。
技术实现思路
1、针对现有技术的缺陷和改进需求,本发明提供了一种基于图片相似度的代码克隆检测方法、系统及存储介质,其目的在于同时实现对大规模语义克隆的代码克隆检测。
2、为实现上述目的,按照本发明的一个方面,提供了一种基于图片相似度的代码克隆检测方法,包括:
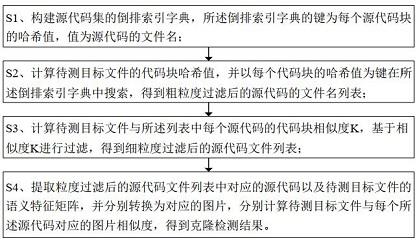
3、s1、构建源代码集的倒排索引字典,所述倒排索引字典的键为每个源代码块的哈希值,值为源代码的文件名;
4、s2、计算待测目标文件的代码块哈希值,并以每个代码块的哈希值为键在所述倒排索引字典中搜索,得到对应的源代码的文件名列表;
5、s3、计算待测目标文件与所述列表中每个源代码的代码块相似度k,若,则判断待测目标文件与对应的源代码不存在克隆关系;若,则判断待测目标文件与对应的源代码存在克隆关系;其中,为设定的第一克隆过滤阈值,为设定的第二克隆过滤阈值;
6、s4、提取对应的源代码以及待测目标文件的语义特征矩阵,并分别转换为对应的图片,分别计算待测目标文件与每个所述源代码对应的图片相似度,得到克隆检测结果。
7、进一步地,s4中,提取对应的源代码以及待测目标文件的语义特征矩阵,并分别转换为对应的图片包括:
8、s41、将待测目标文件以及对应的源代码转换为抽象语法树;
9、s42、将所述抽象语法树转换为n×n的语义特征矩阵,其中,所述语义特征矩阵中的元素表示所述抽象语法树中节点指向节点的边的条数,和取值分别为0,1,……,n-1,n为所述抽象语法树节点的总数;
10、s43、将所述语义特征矩阵转换为对应的图片。
11、3.根据权利要求2所述的方法,其特征在于,s43中,将所述语义特征矩阵转换为对应的图片之前,还包括:删除所述语义特征矩阵中表示两个叶子节点之间边的条数的元素。
12、进一步地,s43中,将所述语义特征矩阵转换为对应的图片之前,还包括:将所述语义特征矩阵进行归一化;所述归一化公式为:
13、
14、其中,表示归一化之前的语义特征矩阵,表示归一化之后的语义特征矩阵。
15、进一步地,s4中,分别计算待测目标文件与每个所述源代码对应的图片相似度,得到克隆检测结果,包括:
16、分别计算待测目标文件与每个所述源代码对应的图片的均方误差值;
17、若所述均方误差值大于设定的图片距离阈值,则判定待测目标文件与相应的源代码为非克隆代码对,否则为克隆代码对。
18、进一步地,s1中,构建源代码集的倒排索引字典包括:
19、s11、将源代码的每n行拼接为一个字符串,则每个源代码生成的代码块个数为:m-n+1,其中,m表示源代码的行数;
20、s12、计算每个代码块的哈希值,并以所述哈希值为键,对应的源代码的文件名为值,构建所述倒排索引字典。
21、进一步地,在s11之前,还包括步骤:
22、提取每个源代码的抽象语法树,并对所述抽象语法树中的变量名类型节点的代码令牌进行规范化;所述规范化包括将同类型变量的变量名用统一的变量名代替。
23、进一步地,s3中,所述代码块相似度k为:
24、
25、其中,表示待测目标文件生成的代码块个数,为所述列表中任一候选源代码的代码块个数,表示待测目标文件与所述候选源代码的代码块重合行数,表达式为:
26、 。
27、按照本发明的另一方面,提供了一种基于图片相似度的代码克隆检测系统,用于执行如第一方面任一项所述的基于图片相似度的代码克隆检测方法,包括:
28、倒排索引字典构建模块,用于构建源代码集的倒排索引字典,所述倒排索引字典的键为每个源代码块的哈希值,值为源代码的文件名;
29、粗粒度过滤结果计算模块,用于计算待测目标文件的代码块哈希值,并以每个代码块的哈希值为键在所述倒排索引字典中搜索,得到对应的源代码的文件名列表;
30、细粒度过滤结果计算模块,用于计算待测目标文件与所述列表中每个源代码的代码块相似度k,若,则判断待测目标文件与对应的源代码不存在克隆关系;若,则判断待测目标文件与对应的源代码存在克隆关系;其中,为设定的第一克隆过滤阈值,为设定的第二克隆过滤阈值;
31、克隆检测模块,用于提取对应的源代码以及待测目标文件的语义特征矩阵,并分别转换为对应的图片,分别计算待测目标文件与每个所述源代码对应的图片相似度,得到克隆检测结果。
32、按照本发明的另一方面,提供了一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现如第一方面任一项所述的方法。
33、总体而言,通过本发明所构思的以上技术方案,能够取得以下有益效果:
34、(1)本发明的方法通过构建源代码集的倒排索引字典,在倒排索引字典搜索与待测目标文件存在一定相似性的代码集合作为粗粒度过滤的结果,实现在大规模源代码集中快速过滤非克隆代码;基于该粗粒度过滤的结果,再次过滤掉与目标文件明显不存在克隆关系或者明显存在克隆关系的源代码,得到细粒度过滤的结果,以减少后续语义特征矩阵提取的样本量,降低相似度匹配的时间开销,通过将克隆检测问题转换为图片相似度比较问题,基于图片的相似性得到克隆检测结果,从而达到语义克隆检测的效果,也即本发明能够降低匹配的时间开销,同时兼顾了大规模和语义克隆检测。
35、(2)进一步地,本发明的方法通过将代码转换为抽象语法树,再将抽象语法树转换为语义特征矩阵,通过抽取抽象语法树的边信息构造一个包含树结构信息的树表征矩阵(也即语义特征矩阵),将两个复杂的抽象语法树匹配算法转换为n×n的二维矩阵,再将其转换为图片进行比较,而不必直接进行语法树之间的匹配,避免了抽象语法树匹配算法的时间长及空间复杂度高的问题,进一步降低了匹配的时间开销。
36、(3)作为优选,由于抽象语法树的令牌节点均为叶子节点,树形结构中叶子节点之间不存在边,也即两个叶子节点之间边的数量为0,因此,删除语义特征矩阵中表示两个叶子节点之间边的数量的元素,以压缩语义特征矩阵的大小,降低计算量,进一步减小检测的时间开销。
37、(4)作为优选,通过以每个源代码块的哈希值为键,以源代码的文件名为值构建倒排索引字典,只要确定了代码的哈希值就可以确定该哈希值对应的多个源代码文件,可以使构建的字典尽可能的小,便于实现快速索引。
38、(5)作为优选,在构建倒排索引字典之前,通过对每个源代码进行代码令牌规范化,可以增强本方法对type-2类型克隆检测的鲁棒性。
39、(6)本发明的方法与源代码的语言类型无关,适用于任意开发语言,通用性强;且本发明的方法不需要代码编译,检测范围广泛。
- 还没有人留言评论。精彩留言会获得点赞!