一种基于大数据的智能化数据预测分析系统及方法与流程
本发明涉及深度学习,具体为一种基于大数据的智能化数据预测分析系统及方法。
背景技术:
1、在现代社会中,电力负荷数据已经成为了重要数据之一,准确对电力负荷数据进行预测,无论是对社会和国家还是个人,其重要性都不言而喻。诸多因素都对电力负荷有或多或少的影响,在大数据时代,数据的种类繁多,体积巨大但价值密度比较低,在对电力负荷进行预测时,过多不需要的数据不仅仅会增加训练的时间和难度,也会使预测的精度降低。同时,在预测过程中,短期的电力负荷主要受到气象因素和电力价格因素的影响,尖、峰、平和谷各个时的电价差异较大,也会给预测带来困难。
技术实现思路
1、本发明的目的在于提供一种基于大数据的智能化数据预测分析系统及方法,以解决上述背景技术中提出的问题。
2、为了解决上述技术问题,本发明提供如下技术方案:
3、一种基于大数据的智能化数据预测分析系统,包括:数据采集单元、数据预处理单元、数据降维单元和分布式服务器集群;
4、所述数据采集单元,其输出端与所述数据预处理单元的输入端相连接,用于收集每个小时的电力负荷、相对湿度、温度、大气压强、降雨量、风速和电力价格数据;
5、所述数据预处理单元,其输出端与所述数据降维单元的输入端相连接,用于对原始数据的异常值进行寻找和处理,将原始数据进行标准化;
6、所述数据降维单元,其输出端与所述分布式服务器集群的输入端相连接,对数据进行降维处理;
7、所述分布式服务器集群,用预处理和降维之后的数据建立分布式深度学习模型,对电力负荷序列进行预测,并将预测结果反标准化得到最终电力负荷数据预测值。
8、可选地,原始数据采用孤立森林算法直接对每天的数据向量进行检测异常值检测。
9、可选地,对检测出来的异常值采用移动平均滤波代替,滤波时使用的数据长度可根据具体情况设定,其形式如下:
10、
11、其中,n为数据长度,zk为异常变量值,zk-24i(i=1,2,...,n)为异常值之前的前n个变量值。
12、可选地,标准化方式采用z—score。
13、可选地,以主成分分析法获取主成分及其方差贡献率,按照方差贡献率从高到低,选取主成分直到所选主成分的方差贡献率之和达到q,q为小于一的正常数,可根据需要自行设置;将获得的主成分与其对应的方差贡献率作内积得到hour量集合,一个hour量对应一个小时的主成分数据,以多元线性回归方式计算获取最合适的hour量组,hour量组所对应的主成分部分即为主成分的有效部分,作为输入输送给所述分布式服务器集群。
14、由于采用了z—score方式进行标准化,故多元线性回归不存在截距。
15、多元线性回归的形式如下:
16、
17、其中,t代表时刻,代表第t时刻的拟合值,l为拟合优度r2保持不变时,对应的hour量组中的hour量个数,xi(i=1,2,...,n)表示时刻,表示第xi时刻的hour量,为的系数。
18、优选地,以分布式机器学习的方式对大规模数据进行训练,将数据分成多个数据片到不同的计算节点上面进行训练,即以数据并行方式训练;
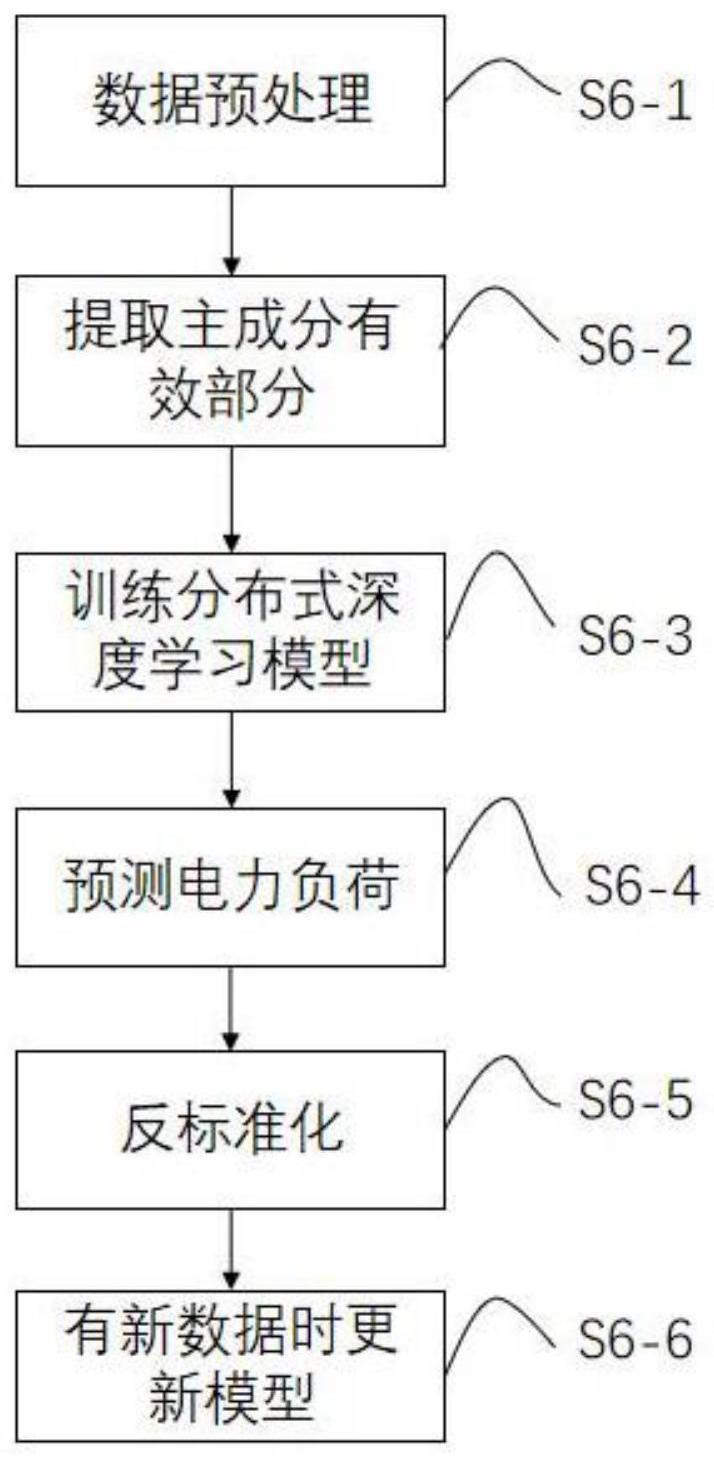
19、优选地,分布式架构基于规约reduce。经典架构参数服务器模式需要有一个中心节点来存储参数和更新梯度,中心节点需要和各个计算节点之间进行通信,随着计算节点数量增加,中心节点通信量也线性增加,参数服务器模式会达到瓶颈;而基于规约reduce的架构则不同,计算节点连接成环形,每个计算节点将梯度传送给下一个计算节点,经过同步之后就可以完成梯度的更新,当计算节点数量增加时,通信量不会随之增加,也没有参数服务器模式会遇到的瓶颈。
20、可选地,梯度同步采用混合范式,完成梯度计算的计算节点会在一定的时间内等待其它的计算节点完成梯度计算;其他计算节点超时之后,完成梯度计算的计算节点之间同步更新梯度,不与未完成的计算节点之间进行同步,未完成的计算节点的梯度被抛弃。
21、可选地,以长短期记忆神经网络对电力负荷进行预测。
22、一种基于大数据的智能化数据预测分析方法,包括:
23、s6-1,收集电力负荷、相对适度、温度、大气压强、降雨量、风速和电力价格数据,进行预处理;
24、s6-2,从预处理的数据中提取出所需要的主成分有效部分;
25、s6-3,分布式服务器集群采用lstm模型对主成分有效成分进行训练;
26、s6-4,利用训练所得lstm模型进行预测得到输出;
27、s6-5,将模型预测结果反归一化得到最终电力负荷预测值;
28、s6-6,当有新的数据来临时,重复步骤s6-1至s6-5,更新lstm模型并获得新的电力负荷预测值。
29、数据预处理包括异常值处理和归一化,原始数据采用孤立森林算法直接对每天的数据向量进行检测异常值检测,对检测出来的异常值采用移动平均滤波代替,滤波时使用的数据长度可根据具体情况设定,其形式如下:
30、
31、其中,n为数据长度,zk为异常变量值,zk-24i(i=1,2,...,n)为异常值之前的前n个变量值;
32、标准化方式采用z—score,其形式如下:
33、
34、其中,x*为归一化后的数据,x为经过异常值处理的数据,μ为x的均值,σ为x的方差。
35、主成分有效部分提取包括以下步骤:
36、s8-1,用hour量集合中的前m个hour量分别对第m+1个hour量进行简单线性回归,挑选出拟合优度r2最高的一个hour量;
37、s8-2,将所挑选的hour量与前m个hour量中其余未被选中的hour量依次组合,对第m+1个hour量进行二元线性回归,挑选出拟合优度r2最高的hour量组;
38、s8-3,将所挑选的hour量组与前m个hour量中其余未被选中的hour量依次组合,对第m+1个hour量进行多元线性回归,获得拟合优度最高的新的hour量组;
39、s8-4,重复步骤s8-3,直到拟合优度r2保持不变,此时hour量组中的hour量个数为n1,将n1个hour量所对应的主成分数据部分提取出来;
40、s8-5,对第m+2至m+p个hour量分别重复进行上述步骤,分别提取出n2至np个对应的主成分数据部分;
41、s8-6,将提取的n1至np个对应的主成分数据部分拼成矩阵,剔除重复的部分,得到a×n维主成分数据部分,a为提取的主成分个数,n为不重复的主成分数据部分的个数;
42、s8-7,考虑到电力价格数据变化周期长,而尖、峰、平和谷各个时段的电力价格不同,为了防止某个或某些时段的电力价格数据缺失,专门在尖、峰、平和谷4个时段内各自挑选一个数据向量作为额外输入,s8-6中提取的n个主成分数据部分合并,剔除重复的部分,得到n*个不重复主成分数据部分,即主成分有效部分,输入数据维度由最初的7×m降低至a×n*;
43、其中,m和p均为正整数,m+p在数值上和数据长度相同。
44、多元线性回归模型如下:
45、
46、其中,t代表时刻,代表第t时刻的拟合值,l为拟合优度r2保持不变时,对应的小时量组中的小时量个数,xi(i=1,2,...,n)表示时刻,表示第xi时刻的日期变量,为的系数。
47、lstm模型包括输入层、lstm层、第一全连接层、dropout层、第二全连接层和回归层;所述输入层的输出端与所述lstm层的输入端相连接,所述lstm层的输出端与所述第一全连接层的输入端相连接,所述第一全连接层的输出端与所述dropout层的输入端相连接,所述dropout层的输出端与所述第二全连接层的输入端相连接,所述第二全连接层的输出端与回归层的输入端相连接。
48、与现有技术相比,本发明所达到的有益效果是:通过让所有主成分与其对应的贡献率作内积,获得hour量集合,用历史hour量对未来的hour量进行多元线性回归,得到对未来的hour量影响较大的历史的hour量,剔除不需要的数据,从而减少输入数据的维数并提高预测精度;在分布式服务器集群上以数据并行方式对lstm模型进行训练,可提高模型的训练速度。
- 还没有人留言评论。精彩留言会获得点赞!