一种基于主动深度强化学习多机协作SLAM方法
本发明涉及多机器人slam领域,用于无回环复杂场景下的slam累计误差消除,具体涉及的是一种基于主动深度强化学习的多机器人协作slam方法。
背景技术:
1、同步定位与地图构建(simultaneous localization and mapping,简称为slam)是指搭载特定传感器的载体,在未知环境于运动过程中进行自身定位,并建立环境的地图。slam能够有效解决gps信号缺失下的定位问题,在无人车辆、机器人等领域得到了广泛的应用。目前,基于单机的视觉slam方法已经具有较为成熟的解决方案,但随着作业环境的扩大,单机slam效率较低,估计时间较长,往往难以达到良好的效果。为了解决这一问题,多机协同的slam方案引起了学术界和工业界的广泛关注。多机协同slam一般指群体移动机器人,在未知环境中,搭载相机获取环境信息,通过数据交换,估计,优化自身的定位信息,并建立环境的地图。其中,slam系统的累计误差在长期无回环的情况下难以消除。
2、目前,主流的slam算法使用回环检测算法消除系统中存在的累计误差,从而提高定位和建图的精度,但是在长时间无回环的场景下容易出现较大的位姿漂移,对于slam中存在的此类问题,单机器人系统的解决能力有限(一种分布式多机协同视觉slam方法与系统_蒋朝阳)。
3、因此针对以上背景很有必要开发多机主动学习协同slam算法,以此应对和处理复杂动态环境下的slam位姿精度问题。
技术实现思路
1、本发明目的在于提供一种基于主动深度强化学习的多机协同视觉slam方法,该方法可以实现在长时间无回环的场景下消除slam系统累计误差。
2、为实现本发明的目的,本发明提供的一种基于主动深度强化学习的多机协作slam方法,其主要特征是能实现复杂场景下的slam误差消除,特别是在长时间无回环的场景下,在光照复杂多变,动态物体等因素影响下满足一定精度的slam位姿估计和地图构建,提高slam系统的鲁棒性,进而提高slam算法在复杂环境的性能。
3、本发明考虑多机协同slam算法进行多机间的深度强化学习,通过互相的学习来改进优化各自的位姿估计。并且在单个机器人的强化学习算法基础上引入主动感知策略,实现多机间的共同学习策略。通过主动感知多机slam位姿以及其准确概率p,进行选取学习和被学习的对象,通过多机合作的方式实现slam系统的累积误差,从而提高slam算法的京都的和鲁棒性
4、本发明的目的至少通过如下技术方案之一实现。
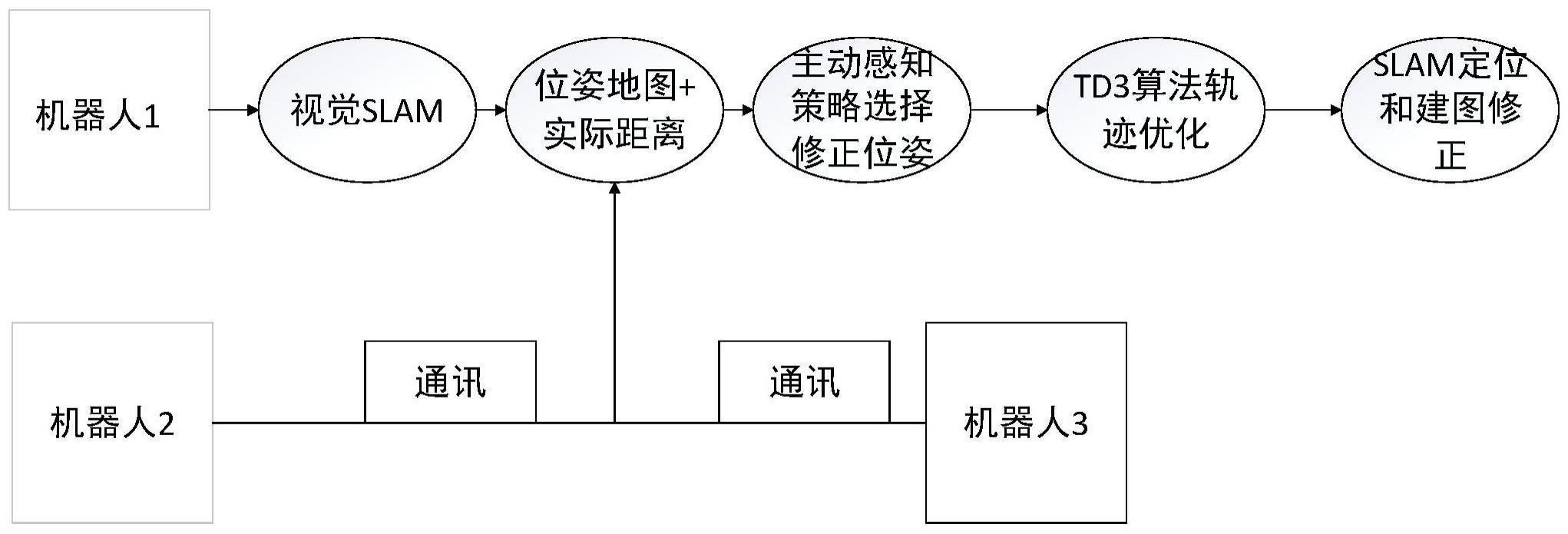
5、一种基于主动深度强化学习多机协作slam方法,包括以下步骤:
6、s1、对机器人运行orb-slam2程序,通过相机获取图像进行位姿估计,得到多机的初始运动轨迹位姿图;
7、s2、基于所得的机器人运动轨迹位姿图,使用深度强化学习td3算法训练进行轨迹的优化得到更准确的位姿;
8、s3、在强化学习算法基础上,引入主动感知策略同时优化多机的位姿,根据实时的slam估计概率值p,选择相应的机器人进行td3算法优化位姿信息;
9、s4、机器人间互相传输各自的位姿信息和实际距离信息,使用td3算法进行slam轨迹的后端优化,达到消除累积误差效果。
10、进一步地,步骤s1具体如下:
11、通过自身携带的相机感知周围环境进行位姿估计和建图,首先对相机获取的真实图像进行orb特征点提取,包括提取fast角点,并计算brief描述子两个步骤;
12、提取orb特征点之后,通过对orb特征点进行相邻帧间的特征匹配来进行初始的位姿估计;特征匹配解决了slam中的数据关联问题,即确定当前看到的路标与之前的看到的路标之间的对应关系;通过对brief描述子的准确匹配确定相邻帧间的特征匹配,可以得到初始位姿估计,本发明使用快速近似最近邻(flann)算法进行特征匹配;
13、根据特征匹配建立的数据关联进行相机位姿和空间点位置估计,得到多机的初始运动轨迹位姿图。
14、进一步地,通过特征匹配建立的数据关联进行相机位姿和空间点位置估计的过程包括:
15、求解过程也即求解一个bundle adjustment问题,是一个最小化重投影误差的问题;考虑n个三维空间点p和三维空间点p的投影p,希望计算相机的位姿r,t,以李代数表示为ε;i表示第i个特征点,假设第i个空间点坐标为pi=[xi,yi,zi]t,其投影的像素坐标为ui=[ui,vi]t;像素位置与空间点的关系如下:
16、
17、写成矩阵形式是:
18、siui=k exp(ε^)pi
19、其中,i为第i个特征点,ε为相机位姿的李代数,si为第i个特征点对应的深度参数,k为相机参数;
20、由于相机位姿未知以及观测点的噪声,该等式存在一个误差;因此,把误差求和,构建最小二乘问题,然后寻找最好的相机位姿,最小化所有观测点匹配误差,最终得到多机的初始运动轨迹位姿图:
21、
22、其中,使用矩阵最小二乘法求得最小化所有观测点匹配误差ε*。
23、进一步地,步骤s2中,根据slam的初始位姿(带有误差),在slam得到的多机初始位姿轨迹图基础上,使用深度强化学习td3算法用于马尔可夫决策过程进行slam轨迹的优化,具体如下:
24、使用强化学习模块用于决策控制的方向,所述马尔可夫决策过程的数学表达式如下式所示:
25、
26、
27、其中,智能体0时刻的初始状态为s0,智能体从一个动作集a中自由地选择动作a0来执行,0时刻的动作a0被执行后,获得0时刻的动作a0的即刻奖励r0,同时智能体以的概率随机地转移到下一个状态,即1时刻的状态s1,是0时刻的动作a0对应0时刻的初始状态s0的概率;在1时刻的状态s1下,然后紧接着开始执行下一个动作,即1时刻的动作a1,执行后,获得1时刻的动作a1的即时奖励r1,智能体又以的概率随机被转移到下一个状态,即2时刻的状态s2,以此类推完成整个转移过程,是动作a1对应初始状态s1的概率,为一个联合概率,表示在选择动作a的情况下,状态从s转移到s'的概率,at为t时刻的动作集,st+1=s'为状态集,为动作a的s状态下的奖励值,e为下一时刻的状态的价值期望,rt+1为t+1时刻的奖励函数。
28、进一步地,所述深度强化学习的算法的离线训练过程包括:
29、在每个时间步,将智能体从环境中得到的样本,包括当前动作a、状态s和奖励r存储到经验回放池中;
30、每次训练时从经验回放池中随机抽取样本,并更新q值;
31、每隔预设训练次数重新复制当前q网络的参数到目标q网络,θ'←θ,θ'为目标q网络的参数,θ为当前q网络的参数;
32、训练时的损失变化为:
33、
34、其中,l'为损失函数,q(st,at,θ)表示原始q网络,为目标q网络,θ和分别表示原始网络和目标网络的权重,a'为下一个状态对应的动作,st、at和rt分别为时间t时的状态、动作和奖励,γ为折损系数;
35、自适应规则调度选择器选择不同的调度规则进行训练,并将选择后的状态值反馈到当前q网络中,再次完成学习。
36、进一步地,采用学习函数learn从经验回放池中抽取样本,完成智能体和环境的数据交互,其中,更新q值的方式为:
37、
38、其中,qπ*(s,a)表示对于任意一个马尔科夫模型,总是存在在状态s下采取动作a并遵循一个最优的策略π*,并且在使用这个策略时就能取得最优值函数;p(s'|s,a)表示在每个决策点,智能体都会观察当前状态并选择动作a,然后从状态s进入一个新状态s’;r(s,a,s')表示当前状态s转换到新的状态s’之后获得的奖励;为最大化长期奖励值得预期总和。
39、进一步地,步骤s3中,引入主动感知策略从单机的强化学习迁移到多机的学习,具体如下:
40、经典的slam模型,由一个运动方程和一个观测方程构成,如下式所示:
41、
42、其中,k表示k时刻机器人的位姿,j表示第j个观测,以函数得形式表示状态方程x和观测方程z,xk-1表示k-1时刻的位姿,uk表示k-1时刻到k时刻的速度输入,f(xk-1,uk)构建k-1时刻到k时刻的位姿估计方程,wk为k时刻的噪声;观测方程中yj表示第j个观测点,zk,j表示在k时刻观测到第j个观测点yj,h(yj,xk)构建k时刻的位姿xk的观测方程,vk,j为对应k时刻和第j个观测点的噪声;
43、在运动和观测方程中,通常假设两个噪声项wk,vk,j满足0均值的高斯分布:
44、wk~n(0,rk),uk~n(0,qk,j)
45、其中,rk和qk,j分别表示对应两个噪声项wk,vk,j的方差,在这些噪声的影响下,希望通过带噪声的数据z和u,推断位姿x和地图y,以及位姿x和地图y的概率分布,这构成了一个状态估计问题;也即,对机器人状态的估计,就是已知输入数据u和观测数据z的条件下,计算状态x的条件概率分布p(x|z,u)。
46、进一步地,为了估计状态变量的条件分布,利用贝叶斯法则,有:
47、
48、其中,p(x|z)表示在已知观测数据z的条件下位姿x的概率,p(z)表示观测概率,p(x)表示位姿估计;
49、那么可以求解x的最大似然估计(mle)x*mle:
50、x*mle=arg max p(z|x)。
51、进一步地,考虑多机器人的位姿估计,每个机器的位姿由最大p值选取,基于此选取p值最小的机器进行主动学习:
52、x'=argminp(zn|xn)
53、其中,n表示第n个机器人,意为选取p值最小的机器人进入学习状态,p(zn|xn)表示第n个机器人在当前帧的位姿估计准确率,x'表示准确率最低的机器人的位姿。
54、进一步地,步骤s4中,slam的位姿变换有以下模型,对于机器人在帧与帧之间的运动,有相应旋转矩阵和变换矩阵:
55、
56、
57、r表示旋转矩阵,t表示位移向量;
58、其中,三维旋转矩阵构成了特殊正交群so(3),而变换矩阵构成了特殊欧式群se(3),表示了机器人在三维空间中的运动,并以李群和李代数的思想优化机器人的轨迹;采取多机器人协作slam的方法消除系统存在的累积误差,构建一个分布式多机系统,进行独立slam工作,以机器间的相对位姿信息(so(3),se(3))为先验知识,使用强化学习算法与环境进行交互,使得地图信息向真实环境学习,达到消除累积误差效果。
59、与现有技术相比,本发明能够实现的有益效果至少如下:
60、(1)本发明提出的深度强化学习优化slam轨迹算法,通过定义环境、状态、行动、奖励和策略,将slam位姿估计问题转化为一个轨迹优化策略问题(即马尔科夫决策的动态转移过程),构建了马尔科夫决策模型作为slam轨迹优化模型,缩小了模型表达与实际问题之间的差距,提高slam的定位精度和鲁棒性。
61、(2)在单机基础上引入了主动感知策略进行多机协同学习,采用主动深度强化学习多机协同策略。依据slam的概率模型,主动感知当前帧各机器人的位姿估计准确性概率,以概率高位姿精准的机器人位姿为学习对象,位姿偏差的机器人使用深度强化学习动作策略,根据下一帧的奖励惩罚去学习优化自身的位姿和轨迹。多机协同的轨迹优化策略提高了多机slam的整体精度和鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!