一种危化品的性质实体抽取方法及系统
本发明涉及自然语言处理,具体涉及一种危化品的性质实体抽取方法及系统。
背景技术:
1、nlp中危险化学品的物理提取(ner)是一个活跃的研究领域。由于化合物的复杂性和描述它们的相关语言,这是一项艰巨的任务。有一些开源工具可用于支持危险化学品的物理提取(ner)。例如,chemdataextractor是一个用于从文本中提取化学信息的开源库。它提供了一套从文本中提取化学名称、公式和其他特征的规则和算法。但是它也存在一些问题,包括只能处理支持格式的文档和提取特定类型的数据,并不能对所有类型的数据进行提取,同时提取的效率也是需要在意的问题。深度学习和自然语言处理的最新进展为改进现有方法提供了新的机会。nlp中危险化学品的当前实体提取(ner)方法可以包括使用字典和基于规则的方法,以及机器学习算法,如支持向量机(svm)、条件随机域(crf)和递归神经网络(rnn)。由于文本的复杂性,单一简单的模型可能无法准确识别某些化学名称或实体。此外,这些模型可能无法识别同一化学名称或实体的不同变体,这可能导致错误的结果。最后,这些方法在识别文本中未明确引用化学名称的化学实体方面受到限制。
技术实现思路
1、发明目的:为了克服现有技术的不足,本发明提供一种危化品的性质实体抽取方法,该方法可以解决现有技术中单一模型识别率不佳和对化工危险品性质的实体抽取模型的相对空缺的问题,本发明还提供一种危化品的性质实体抽取系统。
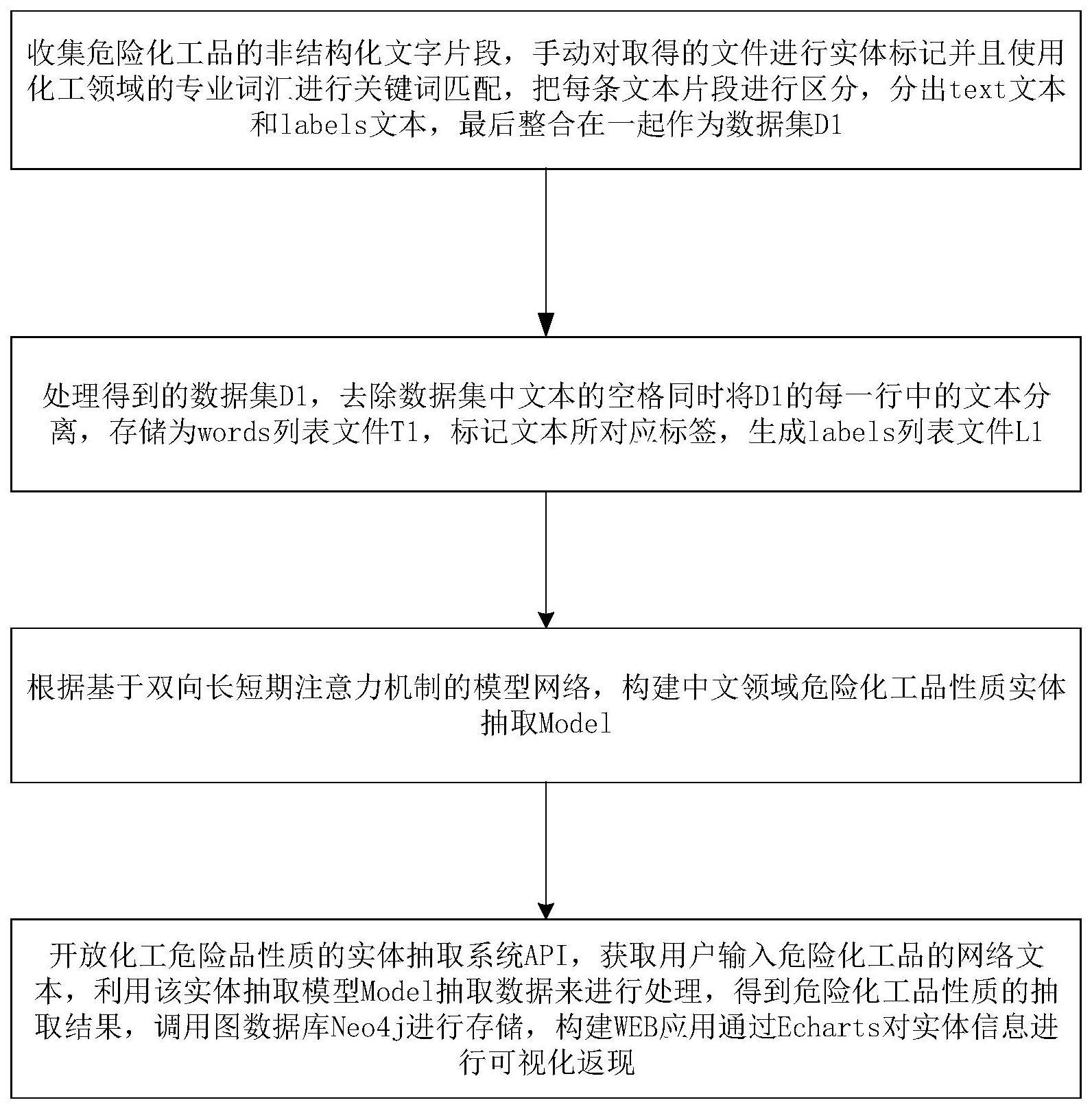
2、技术方案:本发明所述的危化品的性质实体抽取方法,包括以下步骤:
3、s1数据采集:获取msds数据库中的危险化工品名称,通过名称检索对该化学性质的描述文本,得到化学品的性质描述信息文本数据;
4、s2数据预处理:首先进行数据清洗,同时去掉信息文本中重复的信息,之后使用bio标注法进行标注,得到总体数据,将总体数据分为训练集和测试集;
5、s3训练阶段:
6、s31词嵌入模型:将训练集的每条信息文本分别输入到基于bilstm的字符级别模型,经过所述基于bilstm的字符级别模型得到联合后的字符向量特征表示,将联合后的字符向量特征表示输入到长短时记忆网络中,得到对输入序列进行建模的结果ql,kl,vl,把其中的kl,vl传给attention层,把ql传输偏旁特征获取模型中的transformer encoder层;
7、s32偏旁特征获取模型:首先将每条信息文本中的汉字拆分成每个单一的词根,统计词根的词频,然后将词根中的部首输入到卷积神经网络中,让其经过卷积神经网络提取部首级嵌入特征,并将其输入到transformer encoder层;
8、s33将把通过attention层的特征和encoder层的特征进行融合,通过条件随机场crf输出标签信息;
9、s34对步骤s31-s33循环迭代,直至结束;
10、s4采用测试集对训练后的模型进行测试,得到测试集合;
11、s5将训练之后的训练结果和测试集合存储在图数据库neo4j中。
12、进一步的,包括:
13、步骤s31中,基于bilstm的字符级别模型包括:
14、对匹配到的字符进行分类:首先,选取语句s_1,对语句s_1进行单个字符的切分,切分之后,得到chars={c1,c2,c3,……,cn-1,cn},其中,n为语句字符的长度,之后取每个字ci,根据化工词典建立相应的位置信息in_i,将位置信息设置为四类,分别为:{b:表示在匹配单词的第一个位置;m:表示在匹配单词的中间位置;e:表示在匹配单词的末端位置;s:表示单独文字信息},对应公式表示为:
15、
16、
17、
18、
19、其中,l表示词典,1≤i≤n;
20、压缩:在获得没给字符的{b,m,e,s}词集后,每个词集被压缩成一个固定维度的向量,使用词加权方法获取其整体特征,加权函数对应的公式为:
21、
22、其中,z=∑w∈bumueusz(w),这里使用每一个词在一个静态数据库上出现的频率当作权重;
23、字符的联合表示:分别求出vs(b),vs(m),vs(e)和vs(s),将其信息整合到字符表示之上,通过以下公式:
24、es(b,m,e,s)=[vs(b);vs(m);vs(e);vs(s)]
25、xc←[xc;es(b,m,e,s)]。
26、进一步的,包括:
27、步骤s31中,将联合后的字符向量特征表示输入到长短时记忆网络中,包括:
28、在输入序列的每个时间步骤中,长短时记忆网络将联合后的字符向量作为输入,并在隐藏状态中保留先前时间步骤中的信息,长短时记忆网络输出一个表示整个序列的向量,得到注意力机制的q,k,v,公式表示如下:
29、[q,k,v]=ei[w,i,w] (1)
30、其中,e表示长短时记忆网络得到的词向量特征,i为单位矩阵,w是学习的变量参数。
31、进一步的,包括:
32、步骤s32中,输入到卷积神经网络中,让其经过卷积神经网络提取部首级嵌入特征,具体包括:
33、首先,将词根中的部首输入到卷积神经网络中,让其经过卷积神经网络的特征提取层提取相关特征,特征提取层包括30个大小为3的一维卷积核,使用基于随机森林的贝叶斯优化算法搜索最优超参数;
34、然后,经过最大池化层和全连接层实现汉字部首级的特征嵌入,以此来得到每个汉字的偏旁特征,最后,把从卷积神经网络得到的部首级嵌入特征输入到transformerencoder层中。
35、进一步的,包括:
36、所述transformer encoder层包括:头自注意力机制和前馈神经网络,将所述部首级嵌入特征通过公式(1)得到qr,kr,vr,并将ql、kr、vr输入到自注意力机制中,qr输入到attention层中,把多头注意力机制的结果输出到前馈神经网络,设置激活函数,并输出对应特征。
37、进一步的,包括:
38、该方法还包括:
39、开放实体抽取系统的api,然后建立任务,判断需求功能是进行数据库检索还是实体抽取;
40、若进行实体抽取,用户输入待抽取的化工危险品描述文本,创建抽取任务,对这段文本进行预处理,通过训练好的模型预测实体标签y,同时检索数据库查看是否有已经存在的信息,若已经存在相关信息,就对实体抽取的结果信息进行参考,判断其差异性,以存在的数据信息为正确信息,对抽取信息进行补完和修正,如果没有数据则直接录入信息到数据库中,返回web应用程序,抽取任务结束;
41、若是数据库检索,就根据标签直接在图数据库中进行检索,若存在,直接返回检索信息,若不存在,则返回null。
42、另一方面,本发明还提供一种危化品的性质实体抽取系统,该系统包括:
43、数据采集模块,用于获取msds数据库中的危险化工品名称,通过名称检索对该化学性质的描述文本,得到化学品的性质描述信息文本数据;
44、数据预处理模块,其进行数据清洗,同时去掉信息文本中重复的信息,之后使用bio标注法进行标注,得到总体数据,将总体数据分为训练集和测试集;
45、训练阶段:
46、词嵌入模型:将训练集的每条信息文本分别输入到基于bilstm的字符级别模型,经过所述基于bilstm的字符级别模型得到联合后的字符向量特征表示,将联合后的字符向量特征表示输入到长短时记忆网络中,得到对输入序列进行建模的结果ql,kl,vl,把其中的kl,vl传给attention层,把ql传输偏旁特征获取模型中的transformer encoder层;
47、偏旁特征获取模型:首先将每条信息文本中的汉字拆分成每个单一的词根,统计词根的词频,然后将词根中的部首输入到卷积神经网络中,让其经过卷积神经网络提取部首级嵌入特征,并将其输入到transformer encoder层;
48、融合模块,用于把通过attention层的特征和encoder层的特征进行融合,通过条件随机场crf输出标签信息;
49、循环模块,用于对步骤s31-s33循环迭代,直至结束;
50、测试模块,用于采用测试集对训练后的模型进行测试,得到测试集合;
51、存储模块,用于将训练之后的训练结果和测试集合存储在图数据库neo4j中。
52、进一步的,包括:
53、所述基于bilstm的字符级别模型包括:
54、分类模块:首先,选取语句s_1,对语句s_1进行单个字符的切分,切分之后,得到chars={cl,c2,c3,......,cn-1,cn},其中,n为语句字符的长度,之后取每个字ci,根据化工词典建立相应的位置信息in_i,将位置信息设置为四类,分别为:{b:表示在匹配单词的第一个位置;m:表示在匹配单词的中间位置;e:表示在匹配单词的末端位置;s:表示单独文字信息},对应公式表示为:
55、
56、
57、
58、
59、其中,l表示词典,1≤i≤n;
60、压缩模块:在获得没给字符的{b,m,e,s}词集后,每个词集被压缩成一个固定维度的向量,使用词加权方法获取其整体特征,加权函数对应的公式为:
61、
62、其中,z=∑wz∈bumueusz(w),这里使用每一个词在一个静态数据库上出现的频率当作权重;
63、字符的联合表示模块:分别求出vs(b),vs(m),vs(e)和vs(s),将其信息整合到字符表示之上,通过以下公式:
64、es(b,m,e,s)=[vs(b);vs(m);vs(e);vs(s)]
65、xc←[xc;es(b,m,e,s)]。
66、进一步的,包括:
67、所述词嵌入模型中,将联合后的字符向量特征表示输入到长短时记忆网络中,包括:
68、在输入序列的每个时间步骤中,长短时记忆网络将联合后的字符向量作为输入,并在隐藏状态中保留先前时间步骤中的信息,长短时记忆网络输出一个表示整个序列的向量,得到注意力机制的q,k,v,公式表示如下:
69、[q,k,v]=ei[w,i,w] (1)
70、其中,e表示长短时记忆网络得到的词向量特征,i为单位矩阵,w是学习的变量参数;
71、输入到卷积神经网络中,让其经过卷积神经网络提取部首级嵌入特征,具体包括:
72、首先,将词根中的部首输入到卷积神经网络中,让其经过卷积神经网络的特征提取层提取相关特征,特征提取层包括30个大小为3的一维卷积核,使用基于随机森林的贝叶斯优化算法搜索最优超参数;
73、然后,经过最大池化层和全连接层实现汉字部首级的特征嵌入,以此来得到每个汉字的偏旁特征,最后,把从卷积神经网络得到的部首级嵌入特征输入到transformerencoder层中。
74、进一步的,包括:
75、该系统还包括:
76、web检索模块,其包括:开放实体抽取系统的api,然后建立任务,判断需求功能是进行数据库检索还是实体抽取;
77、若进行实体抽取,用户输入待抽取的化工危险品描述文本,创建抽取任务,对这段文本进行预处理,通过训练好的模型预测实体标签y,同时检索数据库查看是否有已经存在的信息,若已经存在相关信息,就对实体抽取的结果信息进行参考,判断其差异性,以存在的数据信息为正确信息,对抽取信息进行补完和修正,如果没有数据则直接录入信息到数据库中,返回web应用程序,抽取任务结束;
78、若是数据库检索,就根据标签直接在图数据库中进行检索,若存在,直接返回检索信息,若不存在,则返回null。
79、有益效果:本发明通过依赖词典信息和文字偏旁的特征,来实现对化工品名称进行抽取,该方法首先通过构建化工危险品的词典信息,之后引用汉语拆字词典,查找文字对其拆分,再通过cnn卷积获取其特征向量,结合词组特征和汉字特征来实现对实体信息的抽取,之后把抽取到的数据保存到neo4j图数据库中,构建web应用来对抽取的数据进行检索,从而解决单一模型识别率不佳和对化工危险品性质的实体抽取模型的相对空缺问题。
- 还没有人留言评论。精彩留言会获得点赞!