视频理解方法及装置与流程
本发明涉及视频理解,尤其涉及一种视频理解方法及装置。
背景技术:
1、在信息技术飞速发展的今天,多模态数据已经成为近年来数据资源的主要形式,因此研究多模态学习的发展赋予计算机理解多元异构数据的能力就具有着重要的价值。利用多种模态,对深度学习的研究具有重要的意义,同时多模态的数据也可为模型的决策提供更多的信息,从而提高决策总体的准确率。多模态的优势在于数据天然是以多种模态存在的,如果能够去进行多模态的融合,那么就可以去更全面的获取信息。多模态学习对于不同的研究领域有不同的应用,例如新闻分析,会有文本记录、也有现场照片、采访者的音频以及现场视频,如果能够充分利用这些信息,对于细粒度的语义理解、对话意图识别以及情感的分析是非常有帮助的。那么另一个优势,在于能够提供更加人性化的人机交互。对比单模态和多模态在形式上的差异,多模态具有丰富的形式。比如图片、文本和音频,对于人类而言,图片对应我们的眼睛,音频对应耳朵,自然语言对应嘴巴或者记录等。多模态的优势在于可以对冗余信息进行删除和对互补信息进行补充,完成对目标更清晰准确的理解和认知。
2、如今大多数多模态学习模型都会应用于视频理解任务,其中大多数有竞争力的视频理解模型都是在与字幕配对的图像上预先训练的,通常是有监督的视觉表征学习,例如目标检测器。在一些视频理解模型中,会使用youtube(优土视频网站)视频帧和文本作为预训练的一部分,到目前为止,很少有视频理解模型在音频上进行过预训练。在训练联合多模态模型时,一个常见的困境是在学习过程中忽略复杂的模态间监督,而支持更简单的模态内监督,比如在一些视频理解任务的工作中应用到了独立的模态编码器,但其只能在简单的模态内进行监督。除此之外,另一个常见的问题是像clip(contrastive language-imagepre-training,对比语言-图像预训练)模型,这样的模型通过匹配图像及其文本来学习图像分类,其仅限于文本和图像之间模态对齐,并且不同语言种类场景的视频数据集都需要重新训练。
技术实现思路
1、本发明的目的之一是为了克服现有技术中的不足,针对现有技术中存在的视频理解模型在进行多模态学习任务时在各模态之间缺乏监督对齐、不同的种类语言场景需要重新训练的问题,提供一种视频理解方法及装置。
2、为实现以上目的,本发明通过以下技术方案实现:
3、第一方面,本发明提供了一种视频理解方法,所述方法包括:
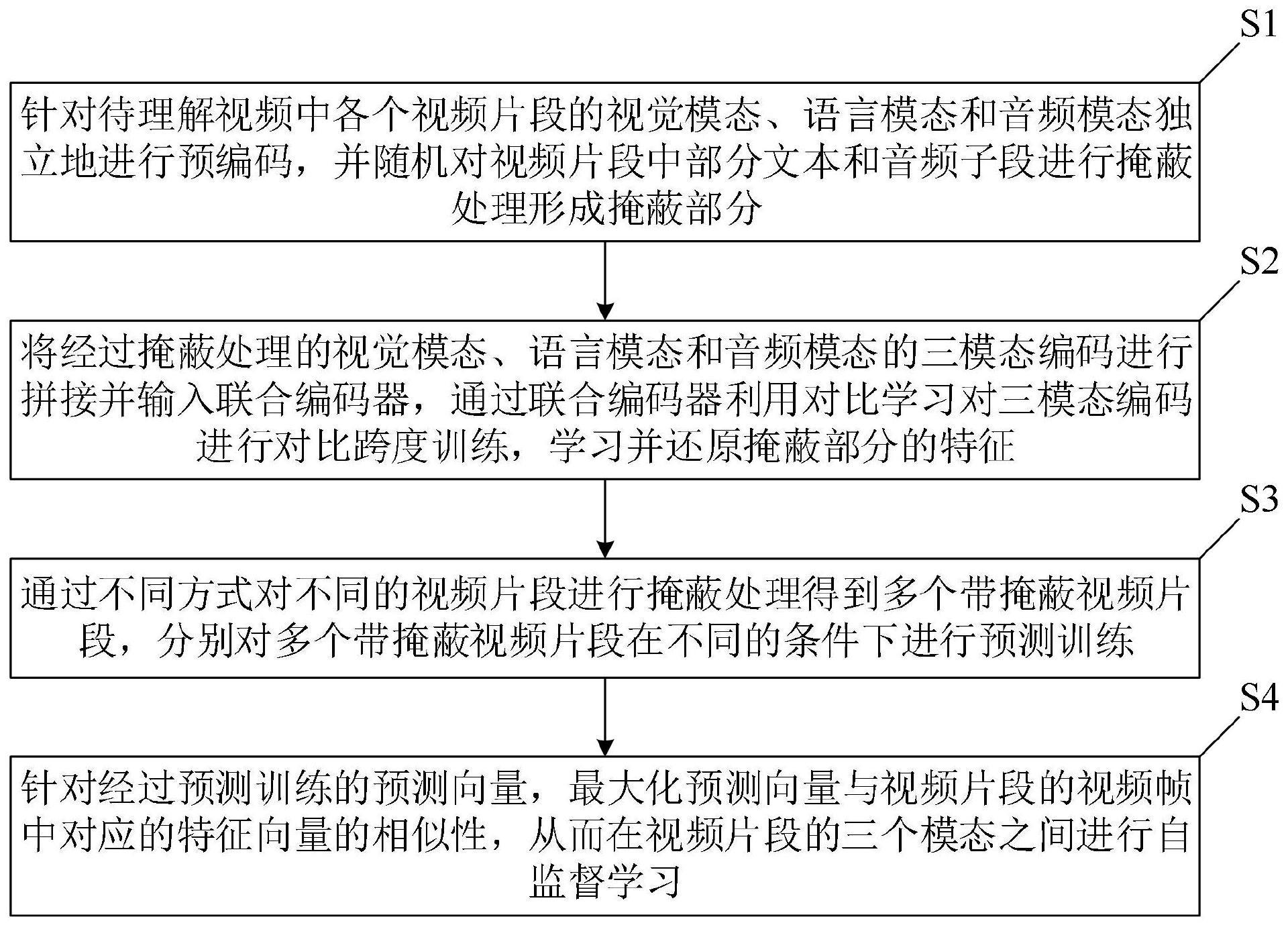
4、s1:针对待理解视频中各个视频片段的视觉模态、语言模态和音频模态独立地进行预编码,并随机对所述视频片段中部分文本和音频子段进行掩蔽处理形成掩蔽部分;
5、s2:将经过掩蔽处理的所述视觉模态、语言模态和音频模态的三模态编码进行拼接并输入联合编码器,通过所述联合编码器利用对比学习对所述三模态编码进行对比跨度训练,学习并还原所述掩蔽部分的特征;
6、s3:通过不同方式对不同的视频片段进行掩蔽处理得到多个带掩蔽视频片段,分别对所述多个带掩蔽视频片段在不同的条件下进行预测训练;
7、s4:针对经过预测训练的预测向量,最大化所述预测向量与所述视频片段的视频帧中对应的特征向量的相似性,从而在所述视频片段的三个模态之间进行自监督学习。
8、在本技术的一个优选实施例中,s1具体包括:
9、s11:将待理解视频输入视频理解模型中;所述待理解视频包括多个视频片段,每个所述视频片段具有视觉模态的图像、语言模态的文本和音频模态的音频;
10、s12:所述图像通过图像编码器进行预编码得到图像特征,所述音频通过音频编码器进行预编码得到序列特征,所述文本通过词嵌入进行预编码得到序列编码;
11、s13:所述视频片段被分成多个视频子片段,随机对其中部分所述视频子片段中文本和音频进行掩蔽处理,形成掩蔽部分,结合所述序列特征和序列编码分别得到带掩蔽部分的序列特征和带部分的序列编码。
12、在本技术的一个优选实施例中,所述视频片段还包括所述文本中与文本内容相邻的上下文内容,对所述视频片段中图像、文本、音频和上下文内容的所有特征进行零均值归一化处理,并通过多层感知器和激活函数来约束回归函数,并通过l1损失来训练所述回归函数。
13、在本技术的一个优选实施例中,s2具体包括:
14、s21:拼接所述图像特征、所述带掩蔽部分的序列特征和所述带掩蔽部分的序列编码形成三模态编码,将所述三模态编码输入联合编码器;
15、s22:在所述联合编码器中,使用语言转换器将所述带掩蔽部分的序列特征中的掩蔽部分的原文本进行编码语义信息得到文本输出,使用音频频谱转换器编码得到音频输出;
16、s23:基于所述视频理解模型和所述视频片段的步长来联合编码所有的模态,使用联合编码器,对所述三模态所联合的联合特征使用线性投影至所述视频理解模型的隐藏层。
17、在本技术的一个优选实施例中,所述对比跨度训练通过设置视觉常识推理、合成视频的问题回答以及运动识别这三个下游任务进行,通过执行所述三个下游任务分别为所述视频理解模型打分,基于所述视频理解模型得到的分数还原所述掩蔽部分的特征。
18、在本技术的一个优选实施例中,s3具体包括:
19、s31:通过对视频片段中部分文本和音频进行掩蔽处理得到第一带掩蔽视频片段,通过对视频片段中部分文本进行掩蔽处理得到第二带掩蔽视频片段;
20、s32:根据所述第一带掩蔽视频片段的视频帧与字幕推测掩蔽部分的音频和文本,根据所述第二带掩蔽视频片段的文本和音频推测掩蔽部分的文本;
21、s33:设置下游任务对所述第一带掩蔽视频片段和所述第二带掩蔽视频片段中的音频和文本分别进行训练,得到掩蔽部分的文本向量和音频向量;
22、其中,所述下游任务对应多个候选答案,每个候选答案表示一个序列,每个序列包含视频帧特征、问题、候选答案和一个掩蔽标记。
23、在本技术的一个优选实施例中,s4具体包括:
24、s41:对所述掩蔽部分经过预测训练得到的文本向量与所述视频中对应于所述文本向量的文本特征之间的交叉熵进行最小化,得到l2损失;
25、s42:基于所述l2损失得到基于文本的损失和基于音频的损失,同时通过联合编码器对所述视频的文本进行编码,为每个所述视频片段提取一个隐藏层表征;
26、s43:通过对比设置将所述隐藏层中各个向量与所述视频片段的视频帧的对应向量之间进行最大化相似性处理,得到基于帧的损失;
27、s44:将所述基于文本的损失、所述基于音频的损失和所述基于帧的损失相加得到总损失函数;
28、s45:通过所述视频理解模型对所述待理解视频的三个模态进行训练,使得三个模态对应的损失函数的曲线趋向平稳。
29、第二方面,本发明提供了一种视频理解装置,所述装置包括;
30、所述预编码模块用于针对待理解视频中各个视频片段的视觉模态、语言模态和音频模态独立地进行预编码,并随机对所述视频片段中部分文本和音频子段进行掩蔽处理形成掩蔽部分;
31、所述特征还原模块用于将经过掩蔽处理的所述视觉模态、语言模态和音频模态的三模态编码进行拼接并输入联合编码器,通过所述联合编码器利用对比学习对所述三模态编码进行对比跨度训练,学习并还原所述掩蔽部分的特征;
32、所述对比学习模块用于通过不同方式对不同的视频片段进行掩蔽处理得到多个带掩蔽视频片段,分别对所述多个带掩蔽视频片段在不同的条件下进行预测训练;
33、所述自监督学习模块用于针对经过预测训练的预测向量,最大化所述预测向量与所述视频片段的视频帧中对应的特征向量的相似性,从而在所述视频片段的三个模态之间进行自监督学习。
34、第三方面,本发明提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,当其在计算机上运行时,使得计算机执行如第一方面所述的视频理解方法。
35、第四方面,本发明提供了一种计算机程序产品,所述计算机程序产品包括计算机程序,当其在计算机上运行时,使得计算机执行如第一方面所述的视频理解方法。
36、本发明所公开的视频理解方法及装置,能够在图像、文本和音频三模态之间进行监督对齐,不用依赖单一模态的特征就可以进行视频理解,不同的种类语言场景也都不需要重新训练也能达到不错的效果,缺失任何模态的情况下的任务也可以做的很好。
- 还没有人留言评论。精彩留言会获得点赞!