疲劳程度多模态融合检测方法、电子设备及存储介质与流程
本发明涉及民航工作人员疲劳状态检测领域,尤其涉及一种疲劳程度多模态融合检测方法、电子设备及存储介质。
背景技术:
1、当前国内多家航空公司依据《ccar-121-r7大型飞机公共航空运输承运人运行合格审定规则》和《ac-121-fs-014ccar121部合格证持有人的疲劳管理要求》建立了疲劳风险管理要求,目前,对于民航工作人员疲劳风险管理国际上比较认可的科学分析方法是生物数学模型,基于不同的疲劳理论模型,预测人体疲劳即警觉性的变化趋势,提供了预测运行中飞行员个体潜在疲劳风险可能。
2、中国专利(申请号202210695576.9)公开了一种基于rppg的非接触式疲劳检测系统及方法本发明提供一种基于rppg的非接触式疲劳检测系统及方法,该系统及方法采用多线程同步通讯,针对实时检测需求,基于python threading多线程模块,实现rppg信号的实时采集与处理以及疲劳状态的同步检测。其中,第一个线程,实现rppg数据的实时捕获、保存与拼接;第二个线程,实现rppg数据的实时分析与疲劳检测。在皮肤检测和luv颜色空间转换结合的基础上,实现rppg原始信号提取,消除人脸内外环境噪声的干扰;其次,通过自适应多级滤波提高信噪比,通过多维度融合cnn模型实现呼吸和心率的高精度检测;最后,在呼吸和心率多通道数据融合的基础上,实现高精度的疲劳分类。但该专利技术需要额外硬件实现呼吸和心率的检测,使用较为复杂;生理信号检测受限于检测设备的灵敏度、佩戴是否规范、环境干扰等情况,易产生较大误差、无效信号甚至信号中断。
3、国内航空公司的飞行员一般是飞四休二,在飞行后的两天休息日获得充分的生理和心理的恢复,可以利用休息期的睡眠情况获得相位峰值。目前,对于民航工作人员疲劳程度的评测主要依赖测试量表填写、人工观察评估,现有技术缺少对于民航工作人员疲劳程度的评测技术手段,不利于民航工作人员的疲劳检测及管理。
技术实现思路
1、本发明的目的在于解决背景技术所指出的技术问题,提供一种疲劳程度多模态融合检测方法、电子设备及存储介质,在待测工作人员应答测评时采集视频、音频数据及获取应答量表,通过构建的视频疲劳识别模型、声学疲劳识别模型和量表评测计算模块分别从三个方面分别进行视频疲劳评测、音频疲劳评测、文本疲劳评测,实现了疲劳评测视频、音频、文字三个维度的综合疲劳检测并加权融合,得到的疲劳状态分值结果与真实情况符合度高。
2、本发明的目的通过下述技术方案实现:
3、一种疲劳程度多模态融合检测方法,其方法包括:
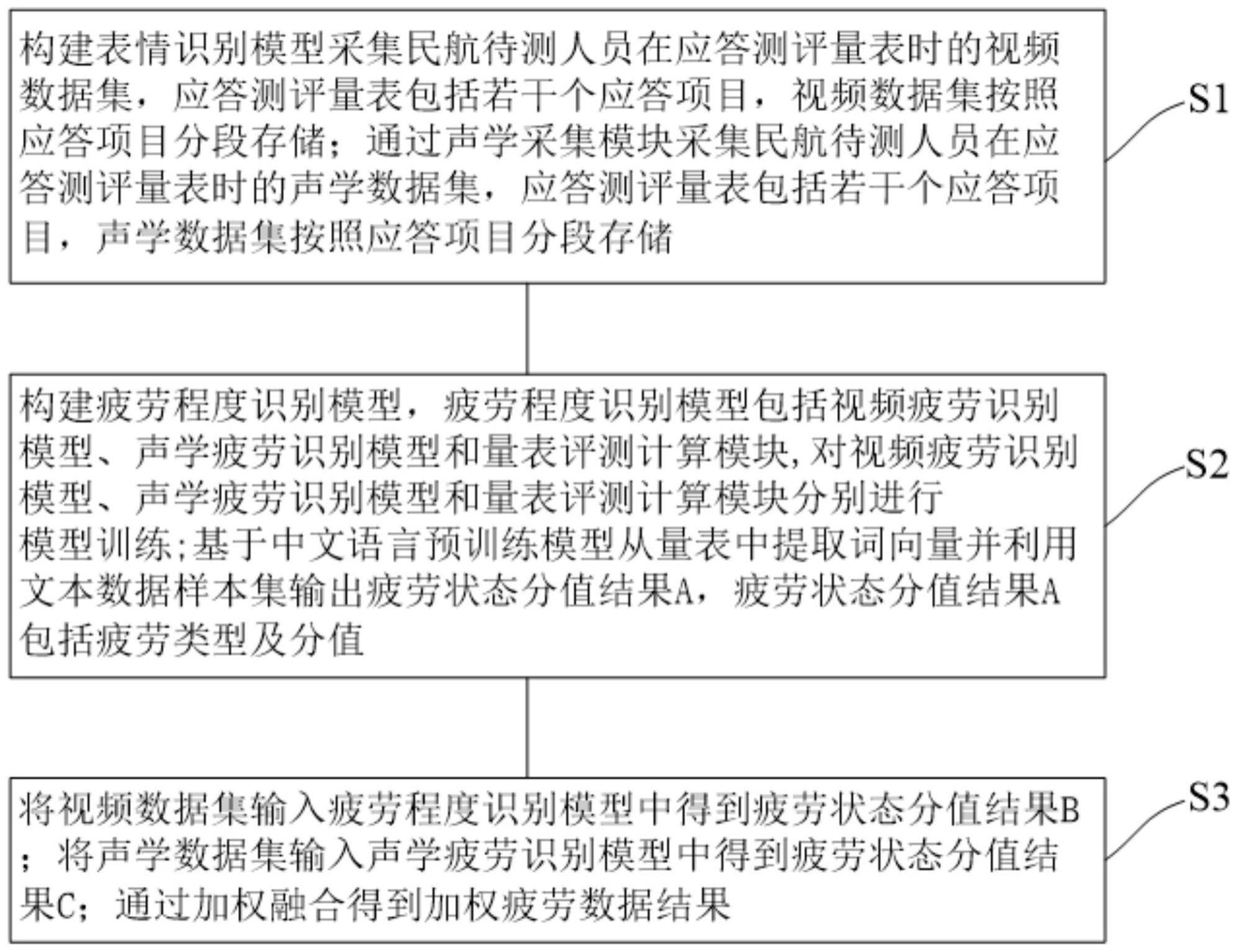
4、s1、构建表情识别模型采集民航待测人员在应答测评量表时的视频数据集,应答测评量表包括若干个应答项目,视频数据集按照应答项目分段存储;通过声学采集模块采集民航待测人员在应答测评量表时的声学数据集,应答测评量表包括若干个应答项目,声学数据集按照应答项目分段存储;
5、s2、构建疲劳程度识别模型,疲劳程度识别模型包括视频疲劳识别模型、声学疲劳识别模型和量表评测计算模块;
6、s21、对视频疲劳识别模型进行如下模型训练:
7、s211、构建视频数据样本集,对视频数据样本集基于应答项目分段按时序稀疏采样得到视频帧样本集其中i表示视频帧i,q表示应答项目,k表示疲劳类型及分值的标签,p为应答项目所对应的视频帧数量;
8、s212、利用特征提取器对视频帧样本集中的视频帧i用描述人脸不同部位肌肉运动情况的特征集进行特征提取,特征集包括肌肉运动特征集、头部运动特征集、眼睛运动特征集;
9、s213、利用lstm模型基于神经网络节点按照应答项目分段进行视频帧的特征时序统计得到特征其中t表示时间序列数据,j表示视频索引,i表示项目索引;通过神经网络节点aj,i产生信息并信息传递、sigmoid函数、tanh函数处理构建出特征时序数据;
10、s214、视频疲劳识别模型通过双层lstm获得2048维表示,通过concat函数将疲劳类型与视频帧连接形成4096维向量,并经过全连接层输出三维表示;
11、s22、对声学疲劳识别模型进行如下模型训练:
12、s221、构建基于应答项目分段的声学数据样本集,声学数据样本集的声学音频片段样本按照应答项目、融合特征、疲劳分值标签对应存储;声学音频片段样本的融合特征由声学特征、频谱特征融合组成,声学特征为具有生理学意义的声学特性,频谱特征为梅尔倒谱系数特征;
13、s222、将融合特征作为特征向量并进行归一化处理,利用声学数据样本集进行排序并利用主成分分析、偏最小二乘回归分析计算得到特征向量与疲劳分值标签的相关性;
14、s23、量表评测计算模块方法如下:构建包含情绪关键词对应疲劳分值、语句层对应疲劳分值、因果关系层对应疲劳分值的文本数据样本集,在应答测评量表从视频数据集提取文字数据构成量表,基于中文语言预训练模型从量表中提取词向量并利用文本数据样本集输出疲劳状态分值结果a,疲劳状态分值结果a包括疲劳类型及分值;
15、s3、将视频数据集输入疲劳程度识别模型中得到疲劳状态分值结果b;将声学数据集输入声学疲劳识别模型中得到疲劳状态分值结果c;按照如下公式得到加权疲劳数据结果:
16、s=wgsg,其中wg表示疲劳状态分值结果为视频或声学或量表的权重,sg表示疲劳状态分值结果为视频或声学或量表所对应的疲劳状态分值结果。
17、优选地,步骤s21替换为如下方法:
18、b21、构建视频数据样本集,对视频数据样本集基于应答项目分段进行视频剪辑得到剪辑片段并赋予疲劳类型及分值的标签,每个应答项目分段对应u个剪辑片段,提取每个剪辑片段v个128维特征向量;采用冗余感知自注意力模块进行特征向量权重分析,冗余感知自注意力模块内部具有高斯核函数计算模块并进行特征向量处理构建空间维度关系,并得到特征图数据;通过视频疲劳识别模型训练特征图数据与疲劳类型及分值标签。
19、优选地,表情识别模型采集民航待测人员的视频时构建有人脸检测获取框进行人脸对齐及配准,若民航待测人员所采集视频未在人脸检测获取框中,则触发警示并重新采集。
20、优选地,所述特征提取器包括神经网络resnet,神经网络resnet对视频帧样本集中的视频帧i进行特征项的计算与提取,将特征项汇集于特征集中;肌肉运动特征集包括内部眉毛抬起、抬起上眼皮、上扬嘴角;头部运动特征集包括头部向左转、头部向右转、头部向上抬、头部向下低、头部向左摇、头部向右右摇、头部向前移、头部向右移;眼睛运动特征集包括眼睛向左动、眼睛向右动、眼睛向上动、眼睛向下动。
21、优选地,步骤s214的损失函数为:
22、其中m表示疲劳类型的个数,n表示总个数,tm表示疲劳类型k的预测值,yk表示疲劳类型k的原始标签。
23、为了更好地实现本发明,融合特征的归一化处理公式如下;
24、其中x是训练特征样本,αmax和αmin分别为最大和最小训练特征向量,为标准化的训练样本;
25、偏最小二乘回归分析采用偏最小二乘回归模型,利用偏最小二乘回归模型计算特征向量与疲劳分值标签之间的相关性;
26、s=kgk+e
27、w=uhk+f,其中s为一个由预测因子组成的a×b矩阵,w为一个由响应组成的a×g矩阵;k与u为两个n×1矩阵,g、h分别为b×1和g×1的正交矩阵;矩阵e和矩阵f是误差项;对s和w进行分解以使k和u的协方差达到最大。
28、优选地,中文语言预训练模型所提取的词向量为识别出意图及需求的关键信息并进行倾向分类与识别,词向量包括内容实体、语句层特征、因果关系向量。
29、一种电子设备,包括:至少一个处理器;以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器执行如权利要求1-7任一所述的方法的步骤。
30、一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1-7中任一项所述的方法的步骤。
31、本发明较现有技术相比,具有以下优点及有益效果:
32、本发明在待测工作人员应答测评时采集视频、音频数据及获取应答量表,通过构建的视频疲劳识别模型、声学疲劳识别模型和量表评测计算模块分别从三个方面分别进行视频疲劳评测、音频疲劳评测、文本疲劳评测,实现了疲劳评测视频、音频、文字三个维度的综合疲劳检测并加权融合,评测手段科学、全面,能得到与真实情况符合度高的疲劳状态分值结果。
- 还没有人留言评论。精彩留言会获得点赞!