一种基于时空特征增强网络的视频人体行为识别方法
本发明涉及视频分析,尤其涉及一种基于时空特征增强网络的视频人体行为识别方法。
背景技术:
1、视频中的人体行为识别是计算机视觉领域中的热门研究,属于视频分析任务中的一个重要分支,其主旨是利用计算机视觉相关算法自动对视频中人的行为进行分析和理解。现阶段视频任务下的人体行为识别在国内外大量研究人员不断努力下,具备了极大的发展潜力与宽广的应用前景,视频行为识别相比于静态图片中的行为识别,更加关注人体在视频序列中的时空变化。现阶段,视频序列的行为识别算法主要可以分为两大类,这两类算法具有不同的理论基础,一类基于传统手工算法,另一类以深度学习算法为基础。随着深度学习在视频理解任务中的应用,视频人体行为识别取得了巨大的进步,因此现阶段较多地使用深度学习的方法,但目前精度较高的深度学习算法往往模型复杂度较大,无法部署在低算力的移动设备当中满足实时性的应用需求,所以研究一个高精度低延迟的算法模型将对大规模应用人体行为识别技术产生重要意义。
2、基于深度方法的行为识别的步骤主要分为:数据的载入与处理、网络构建、分类器与损失函数的定义、优化器的设计以及训练与验证。而卷积神经网络是深度学习中较为高效的方法,其中二维卷积和三维卷积常用于行为识别,但是三维卷积虽能提取到时空特征,但是它会引入大量参数,且计算量大,因此耗时长,因此从时间开销上来看,现在大多选择对传统的二维卷积进行改进,在保证低计算量的情况下确保时间信息的提取,与此同时,现有的研究发现局部时空特征和全局时空特征相互补充对人体行为识别是有利的。
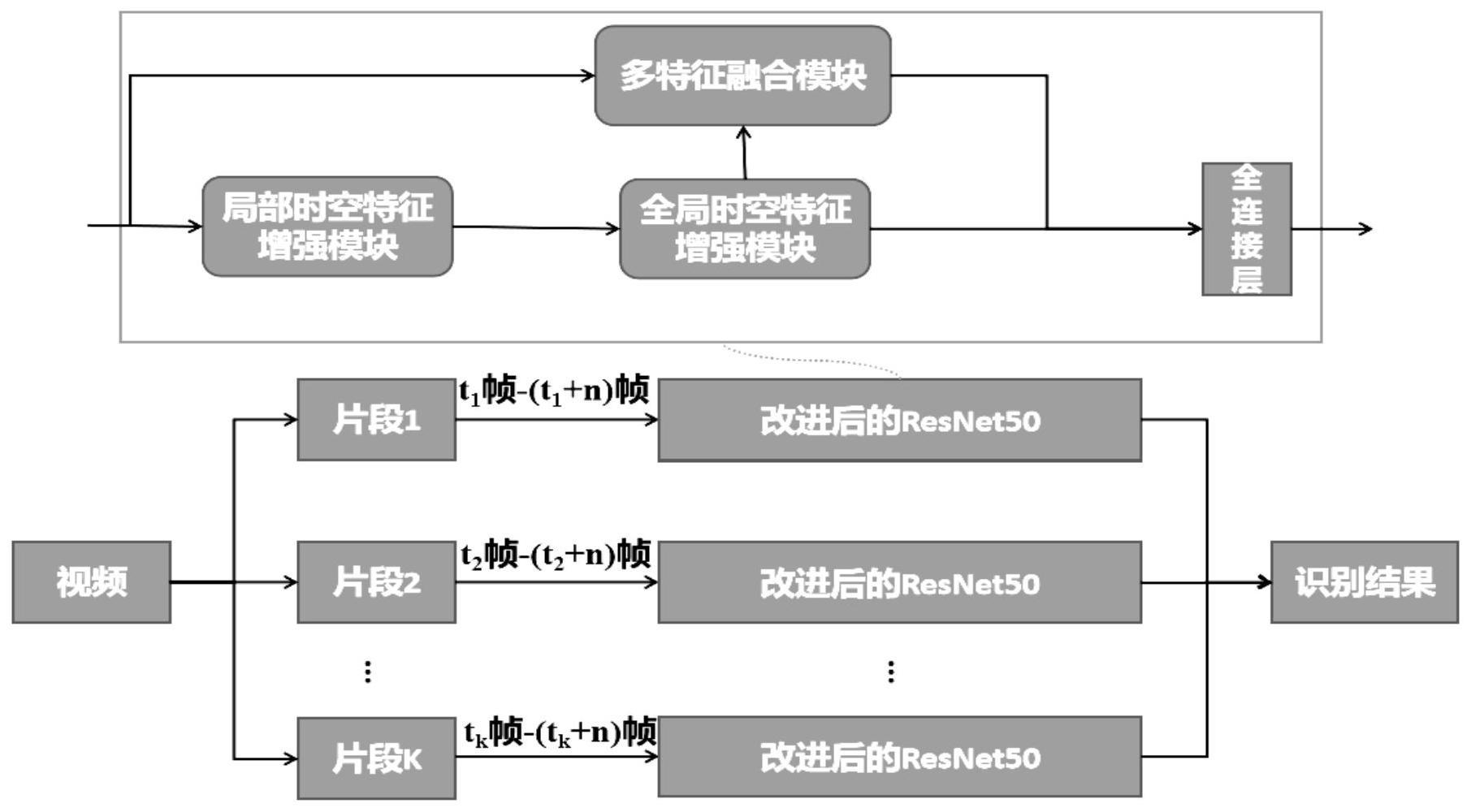
3、目前也出现了一些技术可以避免三维卷积的缺陷,设计了一些即使使用二维卷积神经网络但是也能提取时序信息方法。现有技术中的一种视频人体行为识别方案提出了时空网络与该技术路线相契合。该时空网络用于视频中的局部和全局建模,其时空建模方法的主干采用二维卷积神经网络,如resnet50,设计的时空建模模块插入在resnet50的残差块之间。时空网络首先对输入数据进行了预处理,输入视频采取了均匀采样的策略,因此整个网络利用这种抽样而不是整个视频序列模拟远程时间动态,随后将视频均匀分为t个连续片段,再从每个片段中局部采样n个视频帧。将n个连续的视频帧堆叠成具有3n个通道的堆叠图像,该堆叠图像不仅包含由单个帧表示的局部空间外观信息,还包含这些连续视频帧之间的局部时间依赖性。由于t个堆叠图像上的二维卷积生成t个局部时空特征图,构建采用t个堆叠图像的全局时空表示对于理解整个视频至关重要,因此该时空网络在resnet50中插入了两个时间建模块,分别用在resnet50的第三个阶段和第四个阶段之后,时间建模块旨在捕获视频序列内的远程时间动态,时间建模块中使用了三维卷积。最后为了进一步融合时序信息,在最后的全连接层前加了时间感知块,该结构类似残差结构,包含上下两个分支,上分支包含两次卷积,下分支一次卷积,上下两个分支不同的感受野能更好的融合局部和全局的时序信息,这种卷积结构看成深度可分离卷积,既能融合通道维度的信息又能融合时间维度的信息,将最后做的最大池化生成特征输入全连接层之后就能给出分类结果。
4、上述现有技术中的一种视频人体行为识别方案的缺点包括:
5、计算复杂、时间花销大:巨大的计算成本,需要很长的执行时间,速度太慢不适合在实际应用中使用。
6、长距离建模困难:动作有快慢,一个完整动作的完成时间有长有短,而长时间运动的全局运动特征难以捕获。
7、缺乏高效的运动表示:常用的运动特征从光流图中提取,一方面光流图的计算会带来额外的开销,另一方面,当视频中没有发生运动,而仅仅是外部照明发生变化,也可以观测到光流。
技术实现思路
1、本发明的实施例提供了一种基于时空特征增强网络的视频人体行为识别方法,以实现有效对识别视频数据中的人体行为。
2、为了实现上述目的,本发明采取了如下技术方案。
3、一种基于时空特征增强网络的视频人体行为识别方法,包括:
4、构建包括局部时空特征增强模块、全局时空特征增强模块和多特征融合模块的视频人体行为识别模型;
5、将训练视频数据的帧图像输入到所述视频人体行为识别模型中,通过局部时空特征增强模块提取出帧图像中的帧级别运动的局部时空特征,利用全局时空特征增强模块获取帧图像中的视频级运动的全局时空特征,通过多特征融合模块融合所述局部时空特征和所述全局时空特征,将得到的最终的特征表示输入到全连接层,全连接层输出视频数据中的人体行为识别结果;
6、当重复执行上述处理过程迭代训练所述视频人体行为识别模型达到设定次数后,得到训练好的视频人体行为识别模型,利用所述训练好的视频人体行为识别模型对待检测的视频数据进行人体行为识别。
7、优选地,所述的将训练视频数据的帧图像输入到所述视频人体行为识别模型中,通过局部时空特征增强模块提取出帧图像中的帧级别运动的局部时空特征,包括:
8、将训练的视频数据进行分段,从每一段视频数据中采样并分解得到视频帧图像序列,将视频帧序列输入到所述视频人体行为识别模型中,局部时空特征增强模块包括空间流网络模块和时间流网络模块,所述空间流网络模块通过卷积核为3×3的二维空间卷积提取视频帧图像的空间特征,所述时间流网络模块通过卷积核为3×3的时间卷积提取视频帧图像的时序特征,将所述空间特征和所述时序特征进行组合,得到所述视频数据的局部的时空特征,将局部的时空特征送入resnet50的前期网络层得到特征图fl,将特征图fl传输给全局时空特征增强模块。
9、优选地,所述的利用全局时空特征增强模块获取帧图像中的视频级运动的全局时空特征,包括:
10、所述的全局时空特征增强模块,用于包括多尺度提取网络,该多尺度提取网络包含了三条路径:第一条路径采用短连接;第二条路径利用是一个卷积核为3×3的卷积层提取特征;第三条路径经过平均池化缩小尺寸后再进入卷积核为3×3的卷积层提取特征,再经上采样还原尺寸,进行空间对齐,利用一维的卷积将特征图fl分为前向特征和后向特征,将所述前向特征与经过二维卷积处理过的后向特征相减后,将得到的特征输入到所述多尺度提取网络中的三条路径中,将所述后向特征与经过二维卷积处理过的前向特征相减后,将得到的特征输入到所述多尺度提取网络中的三条路径中,使用sigmoid激活函数将所述三条路径得到的特征进行加权求和,得到融合特征,将所述融合特征与输入的特征图fl进行相乘,得到所述全局时空特征增强模块输出的特征图fg。
11、优选地,所述的通过多特征融合模块融合所述局部时空特征和所述全局时空特征,将得到的最终的特征表示输入到全连接层,全连接层输出视频数据中的人体行为识别结果,包括:
12、将分段后稀疏采样的视频序列与全局特征增强模块的输出fg之和输入到多特征融合模块,多特征融合模块使用卷积从输入数据中提取时空特征、通道特征和运动特征三类互补关键信息,基于注意力机制对时空特征、通道特征与运动特征进行增强,通道特征增强首先经过空间平均池化实现降维,然后经过卷积核为1×1的二维卷积、卷积核为3的一维卷积以及卷积核为1×1的二维卷积得到通道增强特征fc,时空特征增强首先经过通道平均池化实现降维,经过一个卷积核为3×3×3的三维卷积增强时空特征fst,运动特征增强首先利用1×1的二维卷积在通道上分成16份得到特征fmi(i∈[1,16]),将fm(i+1)输入到卷积核为3×3的二维卷积后得到新的特征,再与特征fmi进行差分运算,再经过一个1×1的二维卷积层得到运动增强特征fm;
13、将三类增强的特征之和fc+fst+fm与该多特征融合模块的原始输入数据一同送入resnet50的残差模块得到最终的特征表示fm,将最终的特征表示fm输入到作为分类器的全连接层,全连接层获取输入的视频数据中的人体动作类别,输出人体行为识别结果。
14、优选地,所述的当重复执行上述处理过程迭代训练所述视频人体行为识别模型达到设定次数后,得到训练好的视频人体行为识别模型,利用所述训练好的视频人体行为识别模型对待检测的视频数据进行人体行为识别,包括:
15、将所述视频人体行为识别模型的人体行为识别结果输入到均方误差mse损失函数中,得到损失结果,根据损失结果判断视频人体行为识别模型是否收敛,若收敛,得到训练好的视频人体行为识别模型;否则,根据损失结果梯度反向传播更新视频人体行为识别模型的参数,继续训练视频人体行为识别模型,直到模型收敛,得到训练好的视频人体行为识别模型;
16、将待识别的视频数据进行分段处理,从每一段视频中稀疏采样,将稀疏采样的视频数据输入到训练好的视频人体行为识别模型中,所述训练好的视频人体行为识别模型输出所述待识别的视频数据的输出结果。
17、由上述本发明的实施例提供的技术方案可以看出,本发明提出了一种基于时空特征增强网络的视频人体行为识别的方法,可以高效地从视频中识别出行人的行为。本发明的网络主干利用残差网络resnet50,首先设计了两个特征增强子模块分别用于对长短程运动建模,局部特征增强模块用于提取帧级别运动的局部时空特征,全局特征增强模块用于获取视频级运动的全局时空特征,最后利用一个多特征融合模块捕获视频序列中的互补信息,避免运动细节在深层网络中丢失,并增强网络的表现力。
18、本发明附加的方面和优点将在下面的描述中部分给出,这些将从下面的描述中变得明显,或通过本发明的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!