一种基于特征去噪的行人再识别非局部防御方法
本发明属于计算机视觉,具体涉及一种基于特征去噪的行人再识别非局部防御方法。
背景技术:
1、行人再识别任务(pedestrian re-identification,re-id)是从非重叠视域的拍摄设备所捕获的行人图片库中识别出指定的某个行人图像,它在视频安全监控、传染病排查等领域中具有广泛的运用。随着深度学习研究的蓬勃兴起,基于深度学习的行人再识别逐渐取得了一系列显著的成果,但是神经网络的脆弱性在各种应用中也随之引起了越来越多的关注。在深度神经网络的输入中添加人类无法察觉的细微扰动,输出可能产生极大的影响。
2、在行人再识别领域中,基于深度学习的re-id模型同样沿袭了神经网络的脆弱性,一个人戴着包、帽子或眼镜也可能会误导系统预测,使同一行人在不同摄像机下的匹配相似度明显降低。图1所示为行人再识别任务中的一个对抗攻击(adversarial attack)示例,可以看到行人匹配排序在受到对抗攻击后,错误匹配结果的排序都靠前了。若公安部门在视频监控中部署re-id系统时受到此漏洞攻击,安全风险将大大增加。假如犯罪分子恶意利用这种对抗攻击来逃跑或欺骗监控系统的搜查,将会对社会构成重大威胁。
3、因此,研究行人再识别系统中对抗防御方法,进而改进re-id模型提高其鲁棒性的任务应运而生。
4、近年来,为解决对抗攻击在网络的特征图中产生巨大噪声的问题,《adversariallogit pairing》提出了对抗性逻辑分析(adversarial logit pairing,alp),在同一样本的干净样本和对抗性样本中嵌入更多的相似信息来帮助模型更准确地表达出有益特征,相当于使用干净图像的逻辑作为“无噪声”参考,为对抗图像进行“去噪”。论文《defenseagainst adversarial attacks using high-level representation guided denoiser》提出了高层表征引导去噪器(high-level representation guided denoiser,hgd),使用目标模型输出的重建损失替换像素级损失函数,计算干净图像与去噪图像特征图中激活的语义信息之间的差异,帮助减少噪声并保留图像的语义信息。
5、然而,这些防御方法都没有考虑直接去除特征图上的噪声,未除净的噪声扰动会随着网络传递逐渐扩大,最终仍会导致错误预测。
6、近年来,许多行人再识别的防御方法被提出。如2022年的论文《person re-identification method based on color attack and joint defence》中gong等人提出了一种联合防御方法jad(joint adversarial defense),采用对抗训练、像素掩蔽和颜色反转等多种防御策略提高系统鲁棒性。然而,基于对抗训练的防御方法会降低行人再识别模型的识别率,并且可能会被优化的对抗攻击方法规避。模型结构如图2所示。现有的行人再识别防御方法虽然提出了一些对抗攻击的解决方案,但大多未直接处理特征图上的噪声,导致噪声扩散并最终影响模型识别的准确率。
技术实现思路
1、针对现有技术的不足,本发明的目的在于抑制特征图上的多余噪声,并使re-id模型更加关注行人区域,提高对噪声攻击的鲁棒性,从而提高模型识别的准确率。本发明提出了一种基于特征去噪的行人再识别非局部防御方法。
2、本发明为实现上述发明目的,采取的技术方案如下:
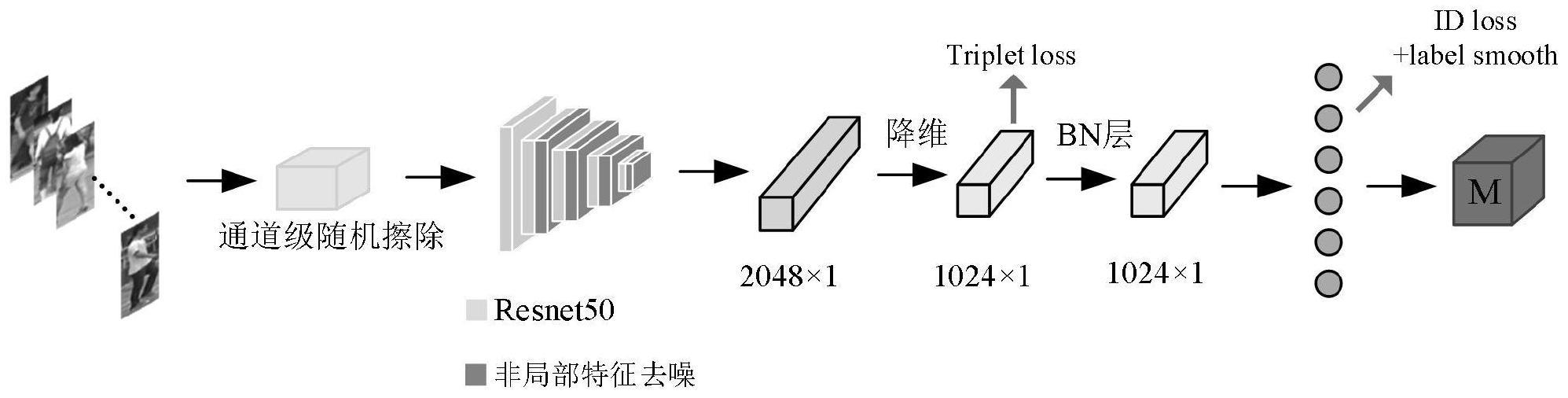
3、一种基于特征去噪的行人再识别非局部防御方法,包括以下步骤:步骤1、输入p×k张彩色图像至行人再识别非局部防御网络;步骤2、通过对输入的图像进行通道级图像擦除处理;步骤3、利用resnet50网络和基于非局部特征去噪块,捕获特征之间的相似性;步骤4、通过联合损失函数,训练出性能良好的防御网络;步骤5、利用步骤3获得的对齐的深层特征对浅层特征进行解耦知识蒸馏;步骤6、若达到指定的训练轮数,则结束;否则继续完成训练,返回步骤1。
4、进一步的作为本发明的优选技术方案,所述步骤s2包括以下步骤:步骤2-1:将输入的图像简单地转换为三个复制的单通道图像,丰富通道信息;步骤2-2:对图像的每一个通道进行随机擦除操作;步骤2-3:输出处理后的图像。
5、进一步的作为本发明的优选技术方案,所述步骤2中,利用通道级随机擦除方法对输入的特征图进行数据增强,增加训练样本的多样性,增强模型的泛化能力以及鲁棒性;通道级随机擦除方法,具体为给定一个预定义的擦除概率,但与普通随机擦除不同,训练过程中在不同通道(r、g、b)图像的任意位置上选择一个随机大小的矩形区域,然后用所有三个通道的随机值替换该矩形区域内的像素值,从而模拟不确定性遮挡带来的对抗噪声,使训练更接近实际场景中的复杂情况。
6、进一步的作为本发明的优选技术方案,所述步骤3包括以下步骤:步骤3-1:将图片特征进行经过1×1卷积层处理,然后进行点积计算得到相似性特征矩阵;步骤3-2:相似性特征矩阵经过softmax函数得到相似性权值,再通过计算得出特征图中的自相关性来去除噪声;步骤3-3:将经过去噪的特征表示送入1×1卷积层进一步处理,最后通过残差连接将该卷积层的输出添加到块的输入中。
7、进一步的作为本发明的优选技术方案,所述步骤3中,以非局部特征去噪块的形式,内嵌在resnet50网络中,捕获特征之间的相似性,从而抑制特征图中的噪声传递,提高防御能力。非局部特征去噪块具有相似性特征学习的特点,可以抑制特征图中的大部分噪声,并使反应集中在有视觉意义的内容上。
8、进一步的作为本发明的优选技术方案,所述步骤4中,采用难样本三元组损失函数和标签平滑正则化的交叉熵损失函数联合训练网络。
9、进一步的作为本发明的优选技术方案,所述采用难样本三元组损失函数具体为:假设在包含p个不同行人的批次样本中,每个行人选取k张图像,然后将它们组成一个大小为p×k的数据集;接着,对于每次训练,从这个数据集中选择类内距离最远和类间距离最近的三张图像组成三元组,并使用其中最困难的样本对来计算损失函数,难样本三元组损失函数表达式如式(1)所示:
10、
11、其中,a为锚点样本,p为正样本,n为负样本,α为阈值参数。
12、进一步的作为本发明的优选技术方案,交叉熵损失函数,具体如式(2)、式(3)所示:
13、
14、
15、其中,n为行人id数量,y为行人真实标签,pi为输出预测身份概率值;引入了标签平滑方法,即为网络分配少量错误的标签,计算过程如式(4)所示:
16、
17、其中,ε为错误率,一般取0.1,此时可以得到引入标签平滑的交叉熵损失函数llsr。
18、进一步的作为本发明的优选技术方案,联合标签平滑正则化的交叉熵损失和难样本三元组损失监督训练,构建的联合损失函数lsum如式(5)所示:
19、lsum=ltri_hard+llsr (5)。
20、本发明所述的一种基于特征去噪的行人再识别非局部防御方法,采用以上技术方案与现有技术相比,具有以下技术效果:
21、(1)本发明提出了基于特征去噪的行人再识别非局部防御网络,该网络在使用非局部防御方法nfd改进现有行人再识别模型的基础上,显著提高了模型在面对攻击时的识别准确率。
22、(2)本发明以resnet50为主干网络,并在其中添加了四层非局部特征去噪块。此外,还引入了通道级随机擦除方法进行数据增强,并采用联合标签平滑正则化的交叉熵损失和难样本三元组损失进行监督训练。这样的设计使得样本在特征空间中能够更好地聚类,从而提高了行人再识别的准确度。
23、(3)本发明提出了通道级随机擦除方法,增加训练样本的多样性,使网络可以处理行人被遮挡等特殊问题,同时增强网络的泛化能力,提高模型对图像噪声的鲁棒性。
24、(4)本发明提出非局部特征去噪模块,有效利用特征图中全局范围内不同位置的相似性信息,使得网络得以捕获噪声图像更大范围内的特征,对重要特征赋予更高权重,从而抑制无用特征,最终的特征图经过残差连接实现去噪效果。
- 还没有人留言评论。精彩留言会获得点赞!