一种基于编程的大语言模型免微调预训练方法和装置
本发明涉及计算机模型训练,尤其涉及一种基于编程的大语言模型免微调预训练方法和装置。
背景技术:
1、现如今,以openai发布的gpt作为代表的生成式预训练大语言模型快速发展,其有着强大的对话生成能力,能够通过问答回复解决大量知识性问题。该预训练大语言模型是对通用大语言模型的基础上是使用特定领域知识对通用大语言模型进行微调得到的,其进一步优化了模型在该特定领域的答案质量。
2、然而,针对特定领域,对通用大语言模型进行微调的工作面临以下几方面难点:
3、1.需要提前构造数量可观并且有效的训练集,并反复对基础模型微调后的结果进行验证避免生成能力倒退。
4、2.如果领域特定知识出现变化,主要对变化的知识进行临时性训练,微调后的大语言模型不具备此能力。
5、3.在微调完毕后,一旦基础大模型需要替换为其他领域模型,则需要重新微调。
6、4.如果用于微调的训练信息十分敏感,一旦开始微调,这些信息会立即内化到大模型中,从而有被其他人利用导致泄露的可能。
7、5.大语言模型虽然有上下文的记忆能力,但对于输入长度有着严格限制,无法将大量训练集之间通过对话的方式直接输入。
8、考虑到上述难点以及通用大语言模型具备一定的代码生成能力,利用特定领域代码提示文本对通用大语言模型进行提示学习的大语言模型免微调预训练方法被提出,它能使模型具备针对特定领域的问答代码生成能力。然而机器对提示学习一次性输入量有限制,而代码提示语训练集的规模较大,这将影响模型对特定领域知识学习的效果。
9、因此,需要提出一种新的大语言模型免微调预训练方法。
技术实现思路
1、为解决上述问题,本发明提供一种基于编程的大语言模型免微调预训练方法和装置,利用程序编译器对关键字的语义不敏感的特点,将代码提示语训练集中的关键词进行符号化压缩编码,从而大幅度缩小输入给大语言模型的代码提示语信息长度,以在大语言模型对于对话输入有着长度限制的情况下能尽可能少次多量的输入代码提示语,实现大语言模型的高效预训练。基于大语言模型具备基础编程能力,在应用经过免微调预训练的大语言模型时,该大语言模型根据输入的经过关键词符号化压缩编码的问题代码反馈一个回复代码,将回复代码进行符号化反压缩编码即可得到人类可理解的程序,应用过程同样简单易实现。
2、第一方面,本发明提供一种基于编程的大语言模型免微调预训练方法,所述方法包括:
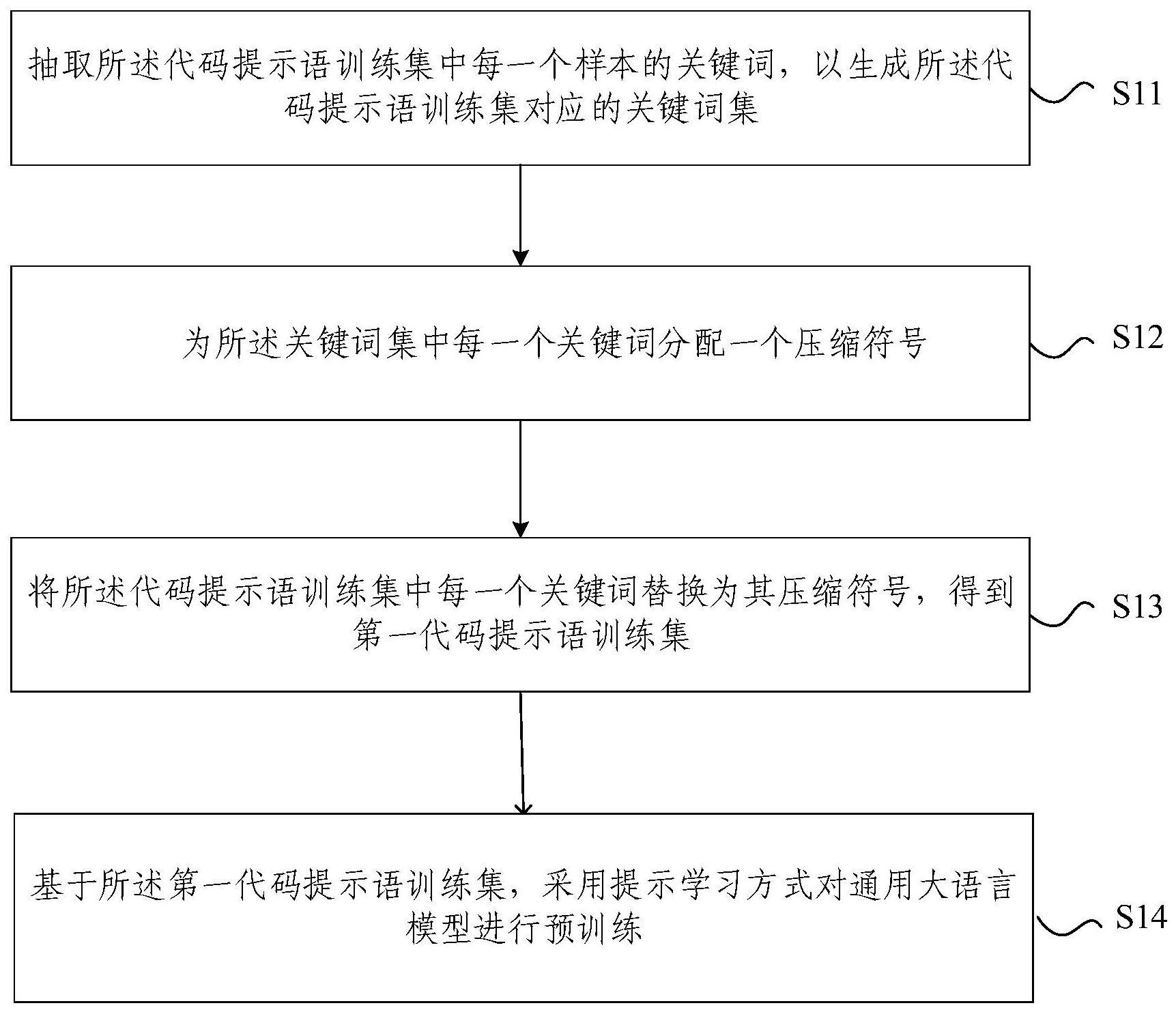
3、抽取所述代码提示语训练集中每一个样本的关键词,以生成所述代码提示语训练集对应的关键词集;
4、为所述关键词集中每一个关键词分配一个压缩符号;
5、将所述代码提示语训练集中每一个关键词替换为其压缩符号,得到第一代码提示语训练集;
6、基于所述第一代码提示语训练集,采用提示学习方式对通用大语言模型进行预训练。
7、根据本发明提供的基于编程的大语言模型免微调预训练方法,所述代码提示语训练集中的样本以“提示-补全”的方式呈现;
8、其中,所述提示为一个问题或一个示例的代码描述;
9、所述补全为指导模型生成最佳回复的代码描述。
10、根据本发明提供的基于编程的大语言模型免微调预训练方法,所述抽取所述代码提示语训练集中每一个样本的关键词,包括:
11、生成每一个所述样本对应的抽象语法树;
12、从所述抽象语法树中抽取特定类型词,并将抽取的特定类型词作为每一个所述样本的关键词。
13、根据本发明提供的基于编程的大语言模型免微调预训练方法,所述特定类型词包括但不限于变量名,方法名和特殊符号。
14、根据本发明提供的基于编程的大语言模型免微调预训练方法,为所述关键词集中每一个关键词分配一个压缩符号时需要满足同时下述条件:
15、条件1:所述关键词集中不同关键词具有不同的压缩符号;
16、条件2:将所述代码提示语训练集中每一个关键词替换为其压缩符号时,不可造成代码语义的变化。
17、根据本发明提供的基于编程的大语言模型免微调预训练方法,为所述关键词集中每一个关键词分配一个压缩符号之后,还包括:
18、根据所述关键词集中每一个关键词及其压缩符号之间的映射关系建立映射表。
19、根据本发明提供的基于编程的大语言模型免微调预训练方法,经过预训练的大语言模型的应用过程,包括:
20、获取待询问问题的代码表示;
21、将所述代码表示输入所述经过预训练的大语言模型,得到第一答复;
22、基于所述映射表,将所述第一答复中的压缩符号替换为其关键词,得到待询问问题的答复。
23、第二方面,本发明提供一种基于编程的大语言模型免微调预训练装置,所述装置包括:
24、生成模块,用于抽取所述代码提示语训练集中每一个样本的关键词,以生成所述代码提示语训练集对应的关键词集;
25、分配模块,用于为所述关键词集中每一个关键词分配一个压缩符号;
26、替换模块,用于将所述代码提示语训练集中每一个关键词替换为其压缩符号,得到第一代码提示语训练集;
27、预训练模块,用于基于所述第一代码提示语训练集,采用提示学习方式对通用大语言模型进行预训练。
28、第三方面,本发明提供一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现如第一方面所述基于编程的大语言模型免微调预训练方法。
29、第四方面,本发明提供一种非暂态计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如第一方面所述基于编程的大语言模型免微调预训练方法。
30、本发明提供一种基于编程的大语言模型免微调预训练方法和装置,包括:抽取代码提示语训练集中每一个样本的关键词,以生成代码提示语训练集对应的关键词集;为关键词集中每一个关键词分配一个压缩符号;将代码提示语训练集中每一个关键词替换为其压缩符号,得到第一代码提示语训练集;基于第一代码提示语训练集,采用提示学习方式对通用大语言模型进行预训练。本发明利用程序编译器对关键字的语义不敏感的特点,将代码提示语训练集中的关键词进行符号化压缩编码,从而大幅度缩小输入给大语言模型的代码提示语信息长度,以在大语言模型对于对话输入有着长度限制的情况下能尽可能少次多量的输入代码提示语,实现大语言模型的高效预训练。
技术特征:
1.一种基于编程的大语言模型免微调预训练方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于编程的大语言模型免微调预训练方法,其特征在于,所述代码提示语训练集中的样本以“提示-补全”的方式呈现;
3.根据权利要求1所述的基于编程的大语言模型免微调预训练方法,其特征在于,所述抽取所述代码提示语训练集中每一个样本的关键词,包括:
4.根据权利要求3所述的基于编程的大语言模型免微调预训练方法,其特征在于,所述特定类型词包括但不限于变量名,方法名和特殊符号。
5.根据权利要求1所述的基于编程的大语言模型免微调预训练方法,其特征在于,为所述关键词集中每一个关键词分配一个压缩符号时需要满足同时下述条件:
6.根据权利要求1~5任一项所述的基于编程的大语言模型免微调预训练方法,其特征在于,为所述关键词集中每一个关键词分配一个压缩符号之后,还包括:
7.根据权利要求6所述的基于编程的大语言模型免微调预训练方法,其特征在于,经过预训练的大语言模型的应用过程,包括:
8.一种基于编程的大语言模型免微调预训练装置,其特征在于,所述装置包括:
9.一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1至7任一项所述基于编程的大语言模型免微调预训练方法。
10.一种非暂态计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7任一项所述基于编程的大语言模型免微调预训练方法。
技术总结
本发明提供一种基于编程的大语言模型免微调预训练方法和装置,包括:抽取代码提示语训练集中每一个样本的关键词,以生成代码提示语训练集对应的关键词集;为关键词集中每一个关键词分配一个压缩符号;将代码提示语训练集中每一个关键词替换为其压缩符号,得到第一代码提示语训练集;基于第一代码提示语训练集,采用提示学习方式对通用大语言模型进行预训练。本发明利用程序编译器对关键字的语义不敏感的特点,将代码提示语训练集中的关键词进行符号化压缩编码,从而大幅度缩小输入给大语言模型的代码提示语信息长度,以在大语言模型对于对话输入有着长度限制的情况下能尽可能少次多量的输入代码提示语,实现大语言模型的高效预训练。
技术研发人员:刘英博,吕武谦,王建民
受保护的技术使用者:清华大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!