一种基于无监督学习的视觉惯性里程计方法
本发明涉及视觉识别定位,具体涉及一种基于无监督学习的视觉惯性里程计方法。
背景技术:
1、随着信息科学、材料科学技术的进步,自主控制也得以在此基础上蓬勃发展,而自主定位技术也在各行业有着更重要的应用价值。基于视觉的定位方法,在实际应用中缺少光线、图像模糊或者采集信息的相机处于高速运动状态的情况下无法完成定位任务,其估算的位姿误差较大。而视觉惯性里程计是一种同时利用视觉信息与惯导信息完成定位任务的系统,可以充分利用惯性与视觉两种信息的互补性,相互补充矫正。同时由于其主要使用的两类传感器相机和惯性测量单元且都具有尺寸小和价格低廉的特点,视觉惯性里程计系统被广泛应用于自主定位的多个领域。
2、传统的视觉惯性融合方法其提取的特征多为表明的低级特征,且需要大量的传感器内部与传感器间的参数标定,并且在图像和imu数据使用前需进行严格的时间同步,数据对齐带来的噪声和误差会严重影响系统的表现效果。同时,惯性测量单元会受到传感器偏置、比例因子、非正交性、温度和噪声等因素的影响,其性能大大降低,因此需要复杂的建模来消除imu的误差和噪声。
3、近些年,深度学习在计算机视觉领域的应用逐渐增多,在视觉惯性里程计领域出现了许多基于深度学习的模型,这些模型可以提取图像与惯导的高维运动特征,同时有效解决传感器的参数标定困难、运动特征提取困难及视觉与惯性信息的融合等问题,但这些方法受到训练数据集的限制。
4、因此传统的定位方法往往存在准确性低、传感器误差的问题。基于深度学习的定位方法会受到训练数据集的限制。而无监督视觉惯性里程计方法,通过神经网络高效利用了图像和惯导信息实现高精度定位,同时通过无监督的方式摆脱了数据集的限制。
技术实现思路
1、针对现有技术的上述不足,本发明提供了一种采用无监督的训练方式解决了数据集的限制,整个系统能够充分利用图像与惯导的互补信息,实现高精度定位的基于无监督学习的视觉惯性里程计方法。
2、为达到上述发明目的,本发明所采用的技术方案为:
3、提供一种基于无监督学习的视觉惯性里程计方法,其包括以下步骤:
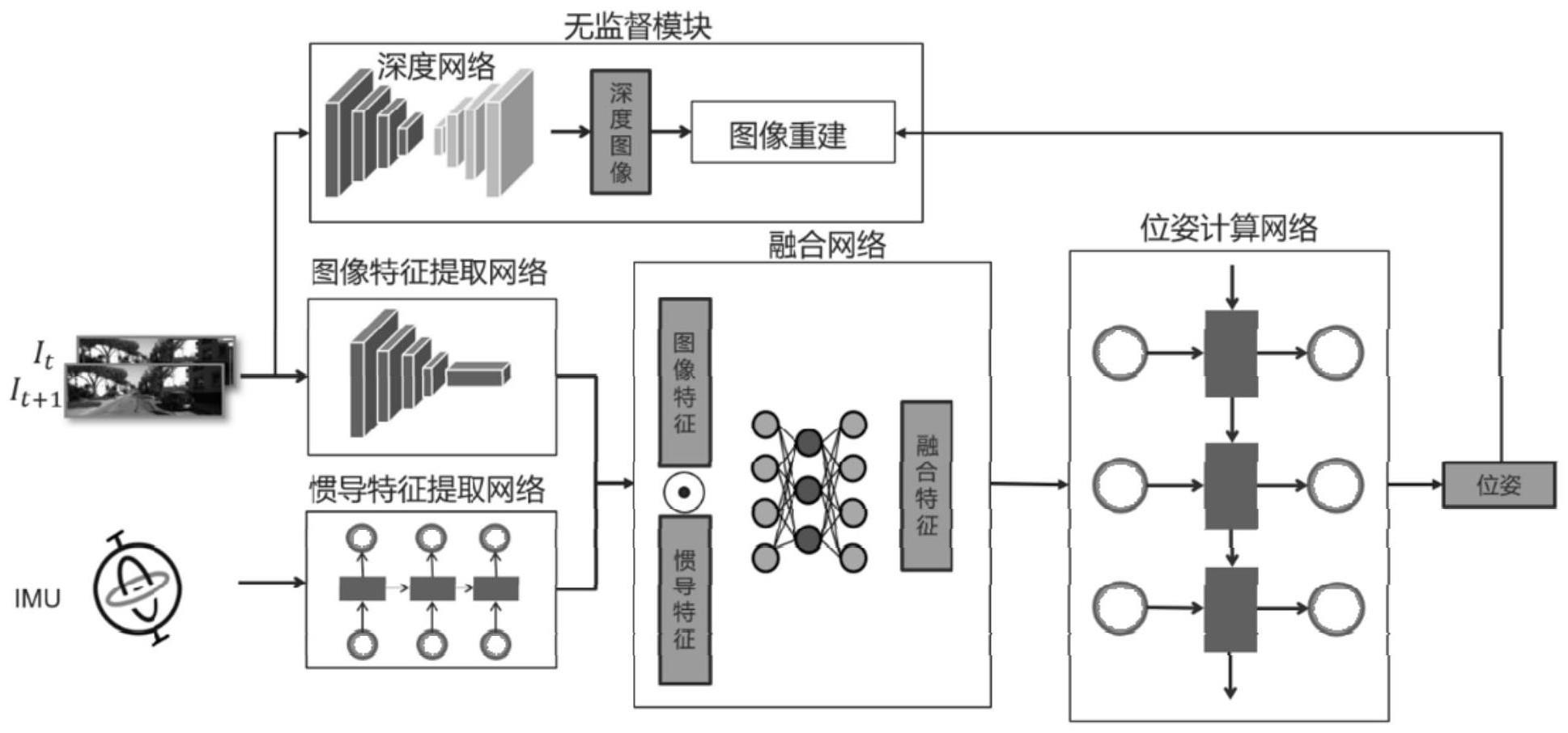
4、s1:采集输入数据,输入数据包图像数据和imu数据,将图像数据和imu数据进行预处理,使图像数据和imu数据同步;
5、s2:将同步后的图像数据和imu数据进行特征提取,得到图像数据的图像特征和imu数据的惯导特征;
6、s3:将图像特征和惯导特征输入位姿计算网络中,输出六自由度的位姿计算结果;
7、s4:利用位姿计算结果输入无监督模块中,构建深度网络框架,根据深度图和源图像之间的差异进行无监督训练,输出训练结果,得到训练好的深度网络;
8、s5:采集新的图像数据输入训练好的深度网络,输出定位结果。
9、进一步地,步骤s1中图像数据和imu数据预处理的方法为:相机采集相邻两祯的图像作为图像数据,并且把采集相邻两祯图像之间的时间采集的imu数据与相邻两祯图像一起打包作为输入数据,确保图像数据和imu数据同步,同步后的imu数据为:
10、
11、其中,α为xyz三个轴上的加速度,ω为xyz三个轴上的角速度。
12、进一步地,步骤s2包括:
13、s21:将同步后的相邻两祯图像信息输入卷积神经网络cnn,提取图像特征:
14、采用迁移学习的方法来辅助搭建图像特征提取的卷积神经网络,卷积神经网络采用flownetsimple光流网络的编码器结构,并在编码器结构的5×5卷积层处添加分支,分支通过7×7的空间通道注意力结构提取网络的不同层次特征,并将提取到的不同层次特征在倒数第二层卷积核处于编码器提取的特征级联,保留不同层次的特征,输出作为提取的图像特征;
15、s22:将同步后的10帧imu数据输入长短期记忆网络lstm中,长短期记忆网络lstm隐藏层数量为2,含512个隐藏状态完成惯导特征的提取。
16、进一步地,步骤s3包括:
17、s31:将提取的图像特征和惯导特征进行拼接,再通过解码器decode分析数据产生一组权重;利用拼接后的融合特征与权重相乘,完成对特征的融合筛选,融合筛选后的特征作为位姿计算网络的输入:
18、
19、w=σ(f(wf+b))
20、
21、其中,f为融合特征,fv和fi分别为图像特征和惯导特征,为沿通道方向的拼接过程,w为生成的调整特征的权重,σ为sigmod激活函数,f为解码器decode对应的函数,w和b均为训练时学习的参数,用于对融合特征做初步处理,f'为最终输出的筛选后的融合特征,为元素逐乘过程;
22、s32:采用长短期记忆网络lstm后接全连接层结构作为位姿计算网络,将融合筛选后的特征输入位姿计算网络中,输出六自由度的位姿计算结果。
23、进一步地,步骤s4包括:
24、s41:构建一个深度网络,深度网络的网络框架为编码器-解码器结构,当摄影机在场景中移动时,相邻图像中的对象可以形成几何约束,相邻图像分别表示源图像is和目标图像的两个相邻帧,利用深度图和运动变换矩阵构建几何一致性:
25、ds(ps)k-1ps=tt→sdt(pt)k-1pt
26、其中,ds、dt分别为相邻帧图像的深度图,ps,pt分别为相邻帧的深度图上的像素点,k为相机的内参矩阵,tt→s为位姿计算结果中的位姿变换矩阵;
27、s42:利用计算源图像is在目标图像的投影it,通过对比目标图像和投影it的外观相似性构建光度一致性约束,形成无监督模块,无监督模块的损失函数为:
28、
29、其中,lp为结构相似性损失,s为目标图像的编号,t为源图像的编号;
30、s43:引入平滑度损失函数来弥补无纹理区域的光度一致性误差:
31、
32、其中,ls为平滑度损失,为二维微分算子,d(p)、i(p)分别为深度图、源图像上的像素,|·|为取元素的绝对值;
33、s44:根据无监督模块的损失函数和平滑度损失函数建立总损失函数:
34、l=lp+αls;
35、其中,α为为加权因子;
36、s45:根据无监督模块的总损失函数进行无监督训练,输出输出训练结果,得到训练好的深度网络。
37、本发明的有益效果为:本发明采用深度学习的方式,避免了传统方法中传感器的复杂标定和建模,同时采用无监督的训练方式解决了数据集的限制,整个方法能够充分利用图像与惯导的互补信息,实现高精度的定位。
38、1.采用深度学习的方法,分别通过卷积神经网络与循环神经网络充分提取了图像和惯导信息的高维特征,同时采用长短期记忆网络lstm有效利用特征完成了位姿计算;各项误差指标(平均平移误差,平均旋转误差)优于目前的主流里程计方法。
39、2.在数据失灵时,相较于其他方法无法完成定位任务的情况,本方法通过合理的网络结构设计和数据筛选机制仍可输出较为准确的定位结果。
40、3.网络采用无监督的训练方式,整个网络训练无需标定真值的数据集,受到数据集的限制小,应用范围广泛。
- 还没有人留言评论。精彩留言会获得点赞!