基于反事实常识因果推理的视觉对话生成方法及装置
本发明涉及视觉对话生成领域,尤其涉及一种基于反事实常识因果推理的视觉对话生成方法及装置。
背景技术:
1、随着计算机视觉技术和自然语言处理技术的飞速发展,视觉和语言交互的多模态领域受到了广泛关注。从图像描述[1]、场景图生成[2]、视觉问答[3],再到视觉对话[4],研究者们致力于提高计算机与人类进行持续性交互的能力。其中,视觉对话任务一直是多模态领域的研究重点,它需要智能体不断地根据已有的图像信息和历史问答中所蕴含的文本信息来推理出当前问题的答案,人类与智能体之间的对话将持续多轮。因此,视觉对话任务需要智能体有较强的人机交互能力,基于此,视觉对话在帮助视障人群、灾害救援任务等领域有很大的应用价值。
2、近年来,在视觉对话领域涌现出了许多优秀的工作。例如:基于循环神经网络的方法[4]使用循环神经网络及其变体来编码视觉-语言的多模态特征进而得到答案,基于注意力机制的方法[5][6]主要使用注意力机制来更精细化的提取回答当前问题所需要的图像信息、对话历史中的上下文信息等,基于图结构的方法[7][8]主要使用图结构来编码图像、对话历史或者当前问题,赋予智能体更强的推理能力来生成答案。它们都是基于已有的图像信息和历史问答中蕴含的文本信息来推理出答案。但是在一些更为复杂的对话场景中,仅仅利用这些信息是远远不够的,智能体还需要像人类一样利用外部的常识知识来辅助答案生成,这往往被研究者们所忽略,从而限制了智能体人机交互能力的提高。例如:在火灾救援现场,智能体可以先一步进入火灾地点拍照并实时地回答救援人员的问题。当救援人员问到“火灾现场有煤气罐吗”的问题时,若智能体不具备“煤气罐在厨房里”等相关常识,将不会关注厨房区域,进而不能正确的回答救援人员的问题。
3、目前仅有基于知识的结构化网络方法(skanet)[9]以及基于多结构的常识知识推理方法(rmk)[10]等将外部常识知识引入了视觉对话任务,并取得了一系列进展。它们都是从外部常识库中提取常识知识,再经编码后融入多模态信息进而得到答案。但是上述框架都是基于这样一个潜在的假设:这些常识知识总是会对答案生成产生正面影响。尽管它们通过计算图像描述与常识知识的语义相似度、通过图嵌入算法(transe算法)构造常识知识图谱进而计算节点之间的余弦距离等,过滤出与当前对话不相关的常识,然而,常识中蕴含的一些“有害偏差”仍然没有被去除,它将会对答案生成产生负面影响。例如:用于检索常识知识的图像标签或者图像描述中的关键词在常识知识中出现频率较高,其可能会干扰智能体生成答案甚至使智能体生成含有这些高频词的错误答案。例如:智能体若具备了“煤气罐”相关的常识,当回答救援人员“火灾现场有煤气罐吗”的问题时,智能体可能会过于关注含有高频词“煤气罐”的错误答案,从而不能给救援人员提供正确的信息,增加了救援难度。
4、基于此研究现状,目前面临的挑战主要有以下三个方面:(1)如何更加有效的选取并利用与图像和当前对话相关的常识知识来辅助答案生成;(2)如何量化常识中蕴含的“有害偏差”对答案生成的负面影响;(3)如何从总体上去除常识对答案生成的负面影响进而只保留常识对答案生成的正面影响,从而提高智能体在灾害救援现场时的答案预测精度,来辅助救援人员更好的了解灾害现场环境、制定救援计划、展开救援工作等。
技术实现思路
1、本发明提供了一种基于反事实常识因果推理的视觉对话生成方法及装置,本发明构建基于常识融合的视觉对话事实因果图,从基于该因果图演绎的视觉对话生成的答案预测分数中减去常识对答案生成的自然直接效应,此过程保留了常识对答案生成的正面影响的同时,去除了常识中蕴含的“有害偏差”对答案生成的负面影响,从而提高智能体在灾害救援现场的人机交互能力,为救援人员提供更真实详尽的灾害环境信息,详见下文描述:
2、一种基于反事实常识因果推理的视觉对话生成方法,所述方法包括:
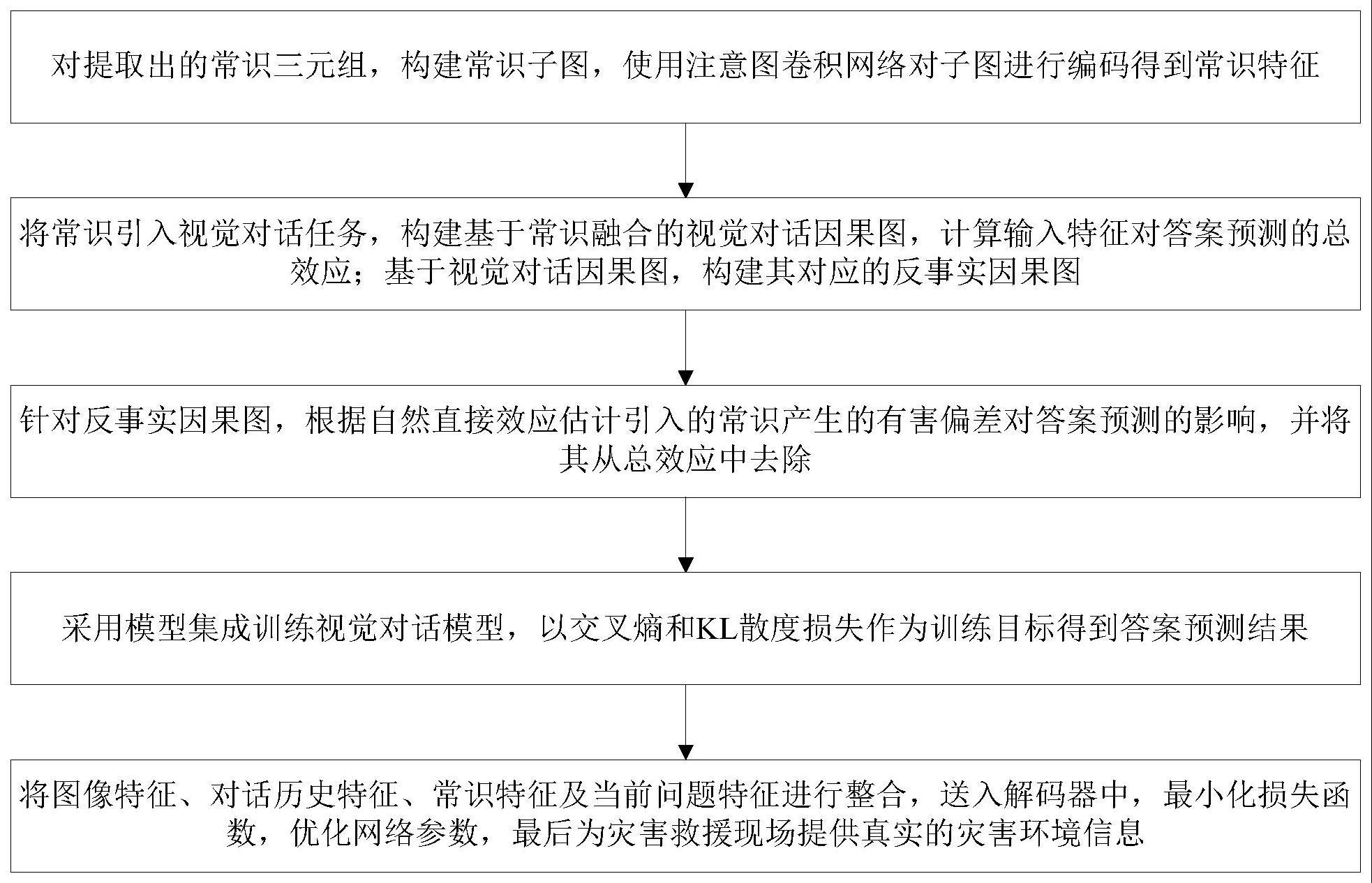
3、对提取出的常识三元组,构建常识子图,使用注意图卷积网络对子图进行编码得到常识特征;
4、将常识引入视觉对话任务,构建基于常识融合的视觉对话因果图,计算输入特征对答案预测的总效应;基于视觉对话因果图,构建其对应的反事实因果图;
5、针对反事实因果图,根据自然直接效应估计引入的常识产生的有害偏差对答案预测的影响,并将其从总效应中去除;
6、采用模型集成训练视觉对话模型,以交叉熵和kl散度损失作为训练目标得到答案预测结果;
7、将图像特征、对话历史特征、常识特征及当前问题特征进行整合,送入解码器中,最小化损失函数,优化网络参数,最后为灾害救援现场提供真实的灾害环境信息。
8、其中,所述常识三元组为:提取数据库的训练集、验证集和测试集样本中与每个视觉对话单元相关的常识;提取出的常识三元组具体操作为:
9、用faster r-cnn框架检测出物体标签,并根据每个标签对应的置信分数选出分数最高的前若干个物体标签;同理针对图像描述选出分数最高的前若干个关键词;
10、其中,所述基于视觉对话因果图,构建其对应的反事实因果图为:
11、通过将i、q、h、c分别赋予空值,即i=i*,q=q*,h=h*和c=c*,进而有k=k*,阻断i、q、h和k对答案a预测产生的影响;
12、常识c在反事实的世界中一次可同时被赋予两个值,即c=c*和c=c;前者用以得到k=k*,而后者与答案a直接连接来评估常识c对答案预测a的自然直接效应。
13、第二方面、一种基于反事实常识因果推理的视觉对话生成装置,所述装置包括:处理器和存储器,所述存储器中存储有程序指令,所述处理器调用存储器中存储的程序指令以使装置执行第一方面中的任一项所述的方法步骤。
14、第三方面、一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序包括程序指令,所述程序指令被处理器执行时使所述处理器执行第一方面中的任一项所述的方法步骤。
15、本发明提供的技术方案的有益效果是:
16、1、本发明将外部常识知识引入现有的视觉对话任务中,智能体不仅能根据已有的图像信息和对话历史上下文信息进行推理,还能利用来自常识知识中的信息来生成答案;现有的视觉对话方法往往忽略了常识知识在视觉对话生成过程中的重要作用;本发明关注智能体在推理答案时所需的信息来源,常识知识的引入使智能体人机交互能力不断提高,有效提升了答案生成精度;
17、2、本发明在将常识知识引入视觉对话任务的同时,考虑了常识中蕴含的“有害偏差”对答案生成的负面影响,构建了基于常识融合的反事实因果图,将该负面影响量化为常识对答案生成的自然直接效应;而现有的基于常识融合的视觉对话生成方法仅仅将常识引入视觉对话任务,使智能体在生成答案时易受到“有害偏差”的干扰;本发明关注常识知识在视觉对话任务中对答案生成的影响,利用因果理论中的自然直接效应来量化常识中蕴含的“有害偏差”对答案生成的负面影响,从而进行去除,来进一步提升答案生成精度;
18、3、本发明构建了基于常识融合的视觉对话事实因果图,现有的基于常识融合的视觉对话框架往往基于该图演绎,本发明基于此图得出常识对答案生成的总效应,从总效应中去除常识对答案生成的自然直接效应,同时本发明还通过最小化kl-散度损失函数使自然直接效应与总效应的答案概率分布相似,从而更好的去除常识中蕴含的“有害偏差”对答案生成的负面影响,保留常识对答案生成的正面影响,现有的方法往往忽略了这一点;本发明关注去除常识中蕴含的“有害偏差”对答案生成的负面影响,提高智能体的人机交互能力;
19、4、本发明方案借助因果理论中的反事实分析方法去除常识中蕴含的“有害偏差”对答案生成的负面影响,具有一定的泛化性,可以适用于大部分的视觉对话模型;
20、5、将本发明的生成结果应用于灾害救援任务中,提高了智能体在实时地回答救援人员问题时的答案预测精度,使救援人员能够充分了解灾害现场的环境信息,从而更好的制定救援计划,降低了救援难度,避免了救援伤亡。
- 还没有人留言评论。精彩留言会获得点赞!