一种自适应融合时间信息的自动降噪与增强实体对齐方法
本发明涉及一种自适应融合时间信息的自动降噪与增强实体对齐方法,属于自然语言处理与机器学习领域。
背景技术:
1、实体对齐(entity alignment),也叫实体匹配(entity matching),是指从两个知识图中识别引用同一对象的实体,这对于不完整性很常见的现实世界知识图谱至关重要。知识图谱所承载的丰富信息使其有利于各种应用,例如问答和推荐系统。不幸的是,单一的知识图谱并不能保证知识的全面覆盖。例如,在著名的公共知识数据库freebase中,超过70%个实体的出生地不明。这种数据稀缺问题极大地限制了知识图谱对下游应用的有效性,知识图谱中信息缺失这一问题可以通过融合两个包含补充信息的知识图谱来加以缓解,而知识图谱融合的一个重要步骤是实体对齐。
2、得益于机器学习和深度神经网络的蓬勃发展,许多实体对齐方法通过知识图谱嵌入进行有效的知识图谱融合。尽管他们取得了成功,但实体对齐方法的一个主要限制是他们难以学习事实(实体)的时间动态,因为他们假设事实是静态的;然而,许多事实会随着时间的改变而改变。例如,事实(fifa 世界杯,主办国,卡塔尔)在2022年起才成立,忽略此类时间信息可能会导致实体歧义和误解,更不用说事实的时间动态还带有可以帮助实体对齐的潜在因果模式。
3、在最近的几项研究中,实体对齐任务已经开始包含时间信息(即时间知识图的实体对齐)。一些研究侧重于如何同时学习关系嵌入和时间嵌入。动态网络嵌入的相关模型也激发了时间知识表示学习。此外,有人使用基于固定边距的完整多类对数损失进行有效训练,以及使用顺序时间正则化来模拟未观察到的时间戳。他们认为没有必要学习知识图谱中时间信息的嵌入,因为大多数时间知识图谱具有统一的时间表示。因此,他们提出了一种结合时间信息匹配机制的简单图神经网络模型,以用更少的时间和更少的参数实现更好的性能。人类在时间知识图的实体对齐方面实现了最先进的性能。然而,根据据我们的调查,时间知识图谱的存储时间信息的方式具有多样性,例如时间点、开始或结束时间、时间间隔。这种存储时间信息的混乱方式给构建高级时间实体对齐模型带来了挑战。在对齐大型时间知识图谱时,他们仍然需要大量计算时间才能完成时间知识图谱实体对齐任务。此外,当前时间知识图的实体对齐模型主要依赖于专家标注的标签,而标签中包含噪声的问题尚未得到讨论。
4、随着最近大规模数据集的出现,深度神经网络 (deep neural network,dnn) 在计算机视觉、信息检索和语言等众多机器学习任务中表现出了令人印象深刻的性能。他们的成功取决于大量经过专家标注的数据,这些数据的获取既昂贵又耗时。一些非专家来源,例如:谷歌知识图谱(google knowledge graph)提供没有来源归属或引用的答案;亚马逊的mechanical turk和收集数据的周边文本,已被广泛用于降低高标签成本。然而,使用这些来源通常会导致标签不可靠。此外,即使对于经验丰富的领域专家来说,数据标签也可能非常复杂;它们也可以通过标签翻转攻击进行对抗性操纵。
5、据报道,真实世界数据集中损坏标签的比例在8.0%和38.5%之间。这种从非专家来源的标签可能会破坏真实的标签,因此会产生噪声标签。人们把从非专家来源的标签称为伪标签。虽然大多数现有的实体对齐研究在专家标注种子(实体对齐标签)的帮助下取得了显著的成功,但是实体对齐模型非常容易受到噪声标签的影响,并且性能会急剧下降。在伪标签存在噪声的情况下,已知训练 dnn 容易受到噪声标签的影响,因为大量模型参数使dnn 过度拟合甚至损坏的标签,具有学习任何复杂函数的能力。有人表明 dnn 可以轻松地用任意比例的损坏标签拟合整个训练数据集,这最终导致测试数据集的泛化能力差。不幸的是,流行的正则化技术,如数据增强(data augmentation)、权重衰减(weight decay)、随机失活(dropout)和批量归一(batch normalization)等,虽然已经得到广泛应用,但它们并不能完全解决过拟合问题。即使激活了上述所有正则化技术,在干净数据和噪声数据上训练的模型之间的测试精度差距仍然很大。此外,标签噪声导致的精度下降比输入噪声等其他噪声更加有害。有人提出了可以在噪声的标记实体对中完成实体对齐任务的实体对齐模型。该模型的两个组成部分是噪声检测和噪声感知,实体对齐噪声检测建立在对抗性训练原则之上,噪声感知实体对齐的核心是基于图神经网络的知识图谱编码器。为了相互增强这两个组件的性能,他们提出了一种统一的强化训练策略来将它们结合起来。虽然该模型在实体对齐任务中可以取得更好的性能,但在时间实体对齐任务中无法取得更好的效果。
6、因此,在存在噪声标签的情况下实现模型良好的泛化能力是一个关键挑战。
技术实现思路
1、本发明的目的是针对现有技术在存在噪声标签的情况下实现模型的泛化能力不足的问题,提出一种自适应融合时间信息的自动降噪与增强实体对齐方法,有效的解决了实体的时间属性多样性问题,并恰当的建模了时间知识图谱的实体之间的复杂关系。除此之外,此框架可以自适应的融合时间信息和增加相似性度量的维度可以有效抵抗噪声标签对时间实体对齐模型的干扰。
2、本发明的技术方案包括如下内容:
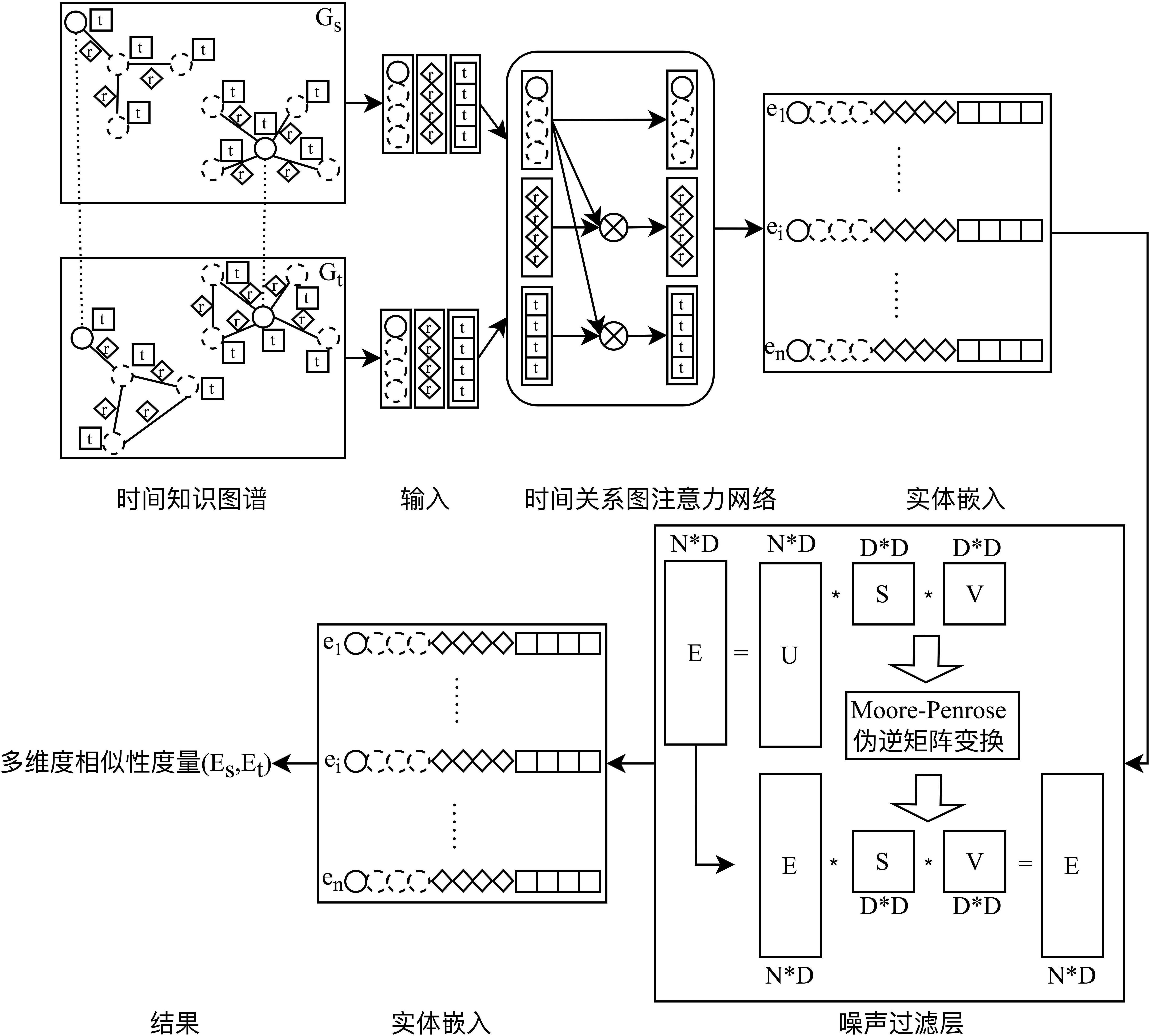
3、步骤1,编码计算相关特征。通过一个聚合获得时间关系图注意力网络的输出特征是通过一个聚合获得的,该聚合线性组合了相邻实体输入特征的实体、时间和关系正交变换。
4、步骤2、计算模型的损失。
5、自适应相对误差损失最小化方案是在训练阶段作为时间实体对齐模型的优化目标,它是基于相对误差定理的方案。首先,在训练过程中,使用l2距离作为度量来定义两个实体和的表示差异。其次,通过计算源种子实体和目标种子实体的距离得出测量值 () ,这类似于翻译嵌入(translating embedding,transe)的翻译假设;通过分别计算源种子实体、目标种子实体和所有其他实体之间距离的平方获得真实值();最后,我们使用相对错误率作为时间实体对齐模型的优化目标。
6、步骤3、噪声过滤。
7、噪声过滤使用噪声过滤层,噪声过滤层是实体嵌入的约束moore-penrose伪逆矩阵变换。moore-penrose伪逆是一种线性代数技术,用于逼近不可逆矩阵的逆矩阵。这种技术可以逼近任何矩阵的逆矩阵,无论是否为正方形。
8、步骤4、根据、和训练练模型直至收敛。
9、步骤5、实体对齐的多维度相似性度量算法是计算在源实体和目标实体之间生成可靠的匹配对。
10、步骤6、使用训练好的模型用多维度相似性度量算法对实体进行对齐并输出结果。
11、有益效果
12、相比于已有的时间知识图谱实体对齐方法,本发明利用时间关系图注意力网络来捕获时间知识图谱的实体结构信息、关系信息和时间信息。此外,通过本发明自适应相对误差损失最小化作为模型的优化算法,可以在没有固定边距或手动设置超参数来优化模型。
13、相比于依赖专家标注种子的方法,不仅减少了人工标注成本,而且对伪标签数据集进行了过滤,噪声过滤层还增强了模型的鲁棒性。本发明的多维相似性度量算法在源实体和目标实体之间能够生成可靠的匹配对,大大增强了时间实体对齐模型的性能,从而提高了实体对齐的准确性,进而提升了知识图谱的质量。
- 还没有人留言评论。精彩留言会获得点赞!