一种基于知识图谱和深度学习的用户菜品推荐方法与流程
本发明涉及用户菜品推荐,特别是一种基于知识图谱和深度学习的用户菜品推荐方法。
背景技术:
1、面对海量的菜品选项,用户可能感到无从选择。一个有效的推荐系统可以帮助用户快速找到合适的菜品,节省用户在挑选菜品上的时间。通过个性化的菜品推荐,用户可以更容易地发现符合自己口味、需求和喜好的菜品,从而提高点餐体验和满意度。而且个性化推荐有助于激发用户的兴趣和购买欲望,从而增加平台的订单量和营业额。有效的菜品推荐可以使用户感受到点餐平台关注并满足他们的需求,从而增加用户对平台的忠诚度和黏性。现有的点餐平台的菜品推荐技术有很多,比如,基于协同过滤的方法;其基本思想是根据用户之前的喜好以及其他兴趣相近的用户的点餐行为来预测该用户感兴趣的菜品,基于对用户历史行为数据的挖掘发现用户的喜好偏向,并预测用户可能喜好的产品进行推荐,一般仅仅基于用户的行为数据(评价、购买、点击等),而不依赖于菜品自身的任何附加属性信息或者用户的任何附加信息(年龄,性别等)。目前应用较为广泛的菜品协同过滤算法是基于领域的方法,该方法又可细分为以下两类:基于用户的协同过滤算法(usercf):给用户推荐和他兴趣相似的其他用户喜欢的产品,基于菜品的协同过滤算法(itemcf):给用户推荐和他之前喜欢的菜品相似的菜。基于内容的菜品推荐算法,根据用户的历史订单和评价数据,获取用户感兴趣的偏好以此进行推荐。
2、然而,采用协同过滤的方法时,点餐平台菜品数量众多,用户一般只对一小部分菜品进行评分或者有购买记录,所以用户之间对菜品的喜好重合性相对较小,在这种情况下会造成样本的稀疏性;对于新用户,没有历史的菜品访问、购买及评价信息,所以无法获取用户对菜品的历史相关联信息,所以这就出现了冷启动问题。另外,基于内容的菜品推荐算法,推荐的结果会聚集在用户过去感兴趣的属性的菜品上,如果用户不主动关注其他类型的菜品,很难为用户推荐多样性的结果,也无法挖掘用户深层次的潜在兴趣,而且基于实践应用场景,基于内容的推荐算法精确度也相对较低;同时现如今的菜品推荐算法大多忽略了菜品的营养健康属性。
技术实现思路
1、本发明的目的在于针对现有技术的缺陷,提供一种能够结合多维度提升菜品推荐的多样性及准确性的基于知识图谱和深度学习的用户菜品推荐方法。
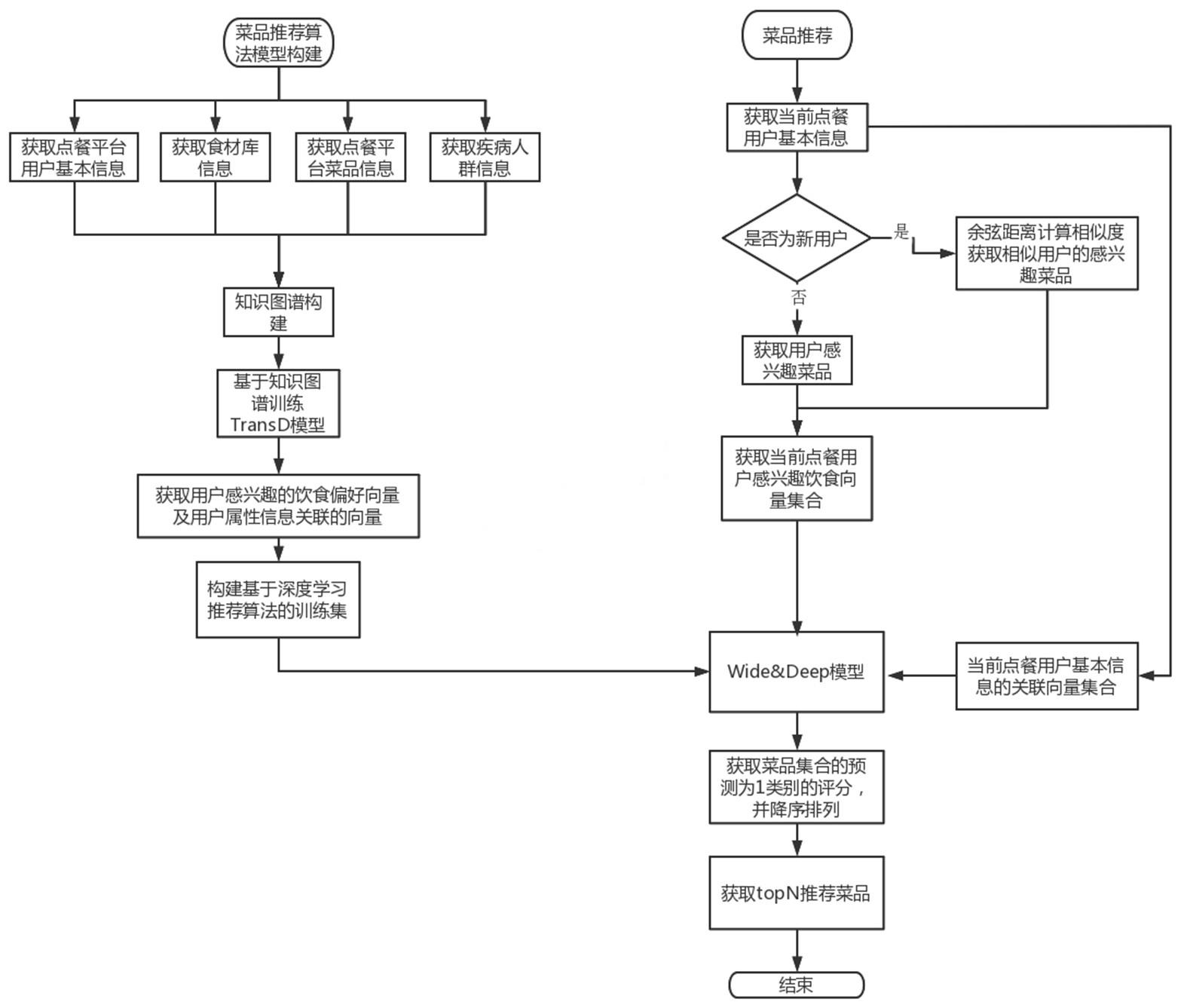
2、本发明所述的基于知识图谱和深度学习的用户菜品推荐方法,包括:
3、菜品推荐算法模型构建:
4、获取食材库信息、疾病人群信息以及点餐平台的用户基本信息和菜品信息;
5、根据食材库信息、疾病人群信息以及点餐平台的用户信息和菜品信息,利用三元组表示菜品实体、菜品相关属性及菜品实体与菜品相关属性之间的属性关系集合来构建知识图谱;
6、通过知识图谱中的三元组关系集合训练transd模型;
7、根据用户在点餐平台的历史购买、点击、收藏记录及用户基本信息获取用户感兴趣的菜品集合和用户信息与购买信息的用户属性信息关联集合;
8、将用户感兴趣的菜品集合和用户信息与购买信息的属性关联信息集合通过训练好的transd模型,在知识图谱中计算出菜品属性的权重,由属性权重和属性值的向量计算出用户对菜品的饮食偏好向量和用户基本属性信息关联向量;
9、根据饮食偏好向量、用户基本属性信息关联向量进行向量拼接构建基于深度学习推荐算法的训练集对wide&deep模型进行训练;
10、菜品推荐:
11、获取当前点餐用户基本信息;
12、判断当前点餐用户是否为新用户;
13、是,则将当前点餐用户基本信息的关联向量集合与老用户基本属性信息关联向量集合通过相似度计算出新用户的相似用户,并将相似用户感兴趣的菜品集合作为当前点餐用户感兴趣的菜品集合;否则直接获取当前点餐用户感兴趣的菜品集合;
14、将当前点餐用户感兴趣的菜品集合通过训练好的transd模型,在知识图谱中计算出菜品属性的权重,由属性权重和属性值的向量计算出当前点餐用户对菜品的饮食偏好向量集合;
15、将当前点餐用户对菜品的饮食偏好向量集合和当前点餐用户基本信息的关联向量集合进行向量拼接,作为wide&deep的输入,并通过已经训练好的wide&deep模型输出,由softmax进行降序排列得到推荐评分,以获取前n个分数对应的菜品,作为推荐给当前点餐用户的菜品集合。
16、作为本发明的一种优选方案,三元组用(h,r,t)来表示,知识图谱可以定义为g:g={(h,r,t|h,t∈e,r∈r)},其中h为菜品实体,t为菜品相关属性,r表示菜品实体与菜品相关属性之间的属性关系集合。
17、作为本发明的一种优选方案,菜品属性的权重计算公式如下:其中h和rj为transd训练获取的菜品及属性关系的向量,则为transd模型中依据菜品实体h生成的投影矩阵。
18、作为本发明的一种优选方案,根据属性权重和属性值的向量计算出当前点餐用户对菜品的饮食偏好向量q,计算公式如下:tj为属性值的向量,为菜品对应属性值的权重,得到用户i对某一菜品p的饮食偏好向量qp,qp={e1,e2,...ek},k为知识图谱中实体嵌入的维度k。
19、作为本发明的一种优选方案,softmax公式如下所示:其中c表示向量的维度数,xi表示向量的第i个参数值,e表示常数,其值约为2.71828,表示e的xi次方。
20、作为本发明的一种优选方案,设当前点餐用户基本信息的关联特征f,f为一个一维向量如下所示:f={f1,f2,f3,...fn},n=属性数;相似度计算则使用余弦相似度,计算公式如下:
21、
22、作为本发明的一种优选方案,食材库信息包括食材所属类别。
23、作为本发明的一种优选方案,疾病人群信息包括疾病人的疾病症状、疾病可以食用食材及菜品、疾病推荐食用食材及菜品、疾病不宜食用食材及菜品;通过获取非结构化的文本信息,采用知识抽取方式,从非结构化数据中提取疾病的相关信息以获得疾病人群信息。
24、作为本发明的一种优选方案,点餐平台的用户基本信息包括用户年龄、性别、身高、体重、患病史、个人饮食口味偏好及对自身体重的预期。
25、作为本发明的一种优选方案,点餐平台的菜品信息包括菜品的制作方式、制作所需食材、菜品营养成分、菜品口味、适合食用人群。
26、本发明的有益效果:
27、菜品推荐算法结合食材库信息,同时对菜品、用户及疾病等数据利用三元组表示菜品实体、菜品相关属性及菜品实体与菜品相关属性之间的属性关系集合来构建知识图谱,从而可以帮助理解同类型实物与不同类实体之间的关联,作为辅助信息嵌入到推荐算法中,用来解决传统推荐算法中存在的冷启动和数据稀疏性问题,其能够有效提升菜品推荐的多样性;另外,基于深度学习的推荐算法中结合用户多种属性进行特征构建,通过根据饮食偏好向量和用户基本属性信息关联向量进行向量拼接构建基于深度学习推荐算法的训练集对wide&deep模型进行训练,将当前点餐用户对菜品的饮食偏好向量集合和当前点餐用户基本信息的关联向量集合进行向量拼接,作为wide&deep模型的输入,并通过已经训练好的wide&deep模型输出,不断优化模型,从而实现高精度的预测和分类,而且自适应性更强,预测精准度更高。
- 还没有人留言评论。精彩留言会获得点赞!