数据处理方法、装置、设备及介质与流程
本申请涉及数据处理,尤其涉及一种数据处理方法、装置、设备及介质。
背景技术:
1、文本匹配是个非常典型的任务,如搜索中常见的搜索召回和排序、检索式问答等任务,本质上都属于文本匹配的任务,即给定一段文本作为查询文本,然后匹配出最为相关的文档或答案然后返回给用户。其中,可以结合文本分词的词权重确定两个文本之间的匹配度。现有词权重确定方式通常是根据文本分词在文本中的共现统计特征来确定。然而,这些共现统计特征与文本分词本身是独立的,比如在一个文本中,通过共现统计特征确定出一个文本分词的词权重为0.5,当这个文本分词被替换为不相关的其他分词时,由于共现统计特征不变,使得替换后的其他分词在该文本中的词权重同样为0.5,也就是说,现有方式所确定出的词权重并不能反映不同文本分词在文本中的重要程度。因此,如何提高文本分词的词权重的确定准确性成为一个亟待解决的问题。
技术实现思路
1、本申请实施例提供了一种数据处理方法、装置、设备及介质,可以提高文本分词的词权重的确定准确性。
2、一方面,本申请实施例提供了一种数据处理方法,该方法包括:
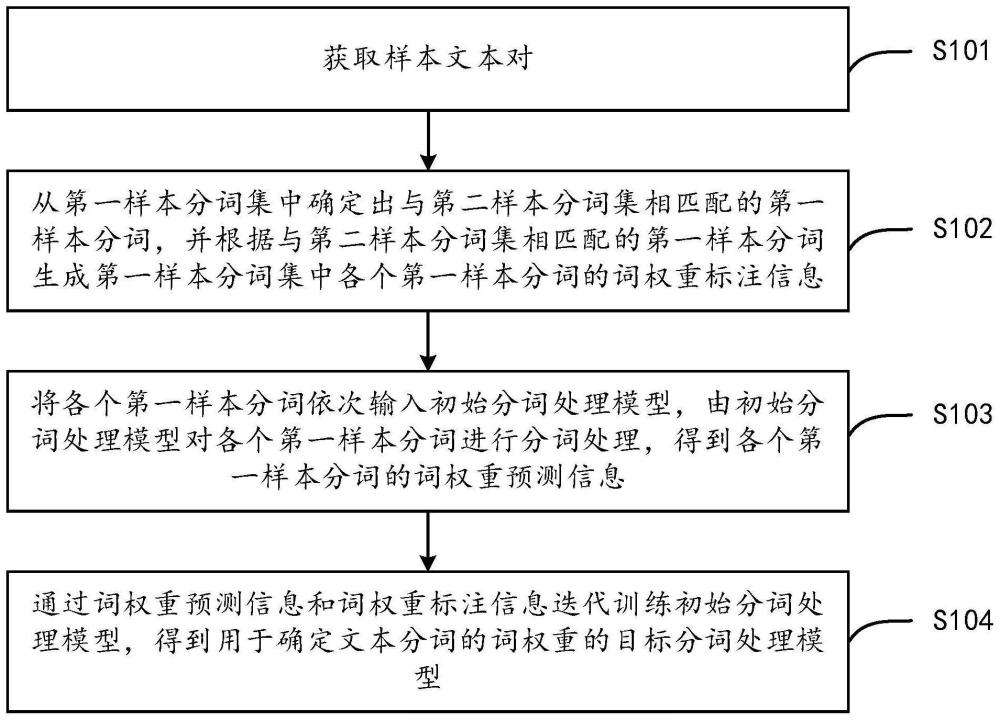
3、获取样本文本对;样本文本对包括第一样本文本以及与第一样本文本相匹配的第二样本文本;第一样本文本为目标关键领域中的召回文本,第二样本文本为目标关键领域中的查询文本;第一样本文本关联有第一样本分词集,第二样本文本关联有第二样本分词集;第一样本分词集包括至少一个第一样本分词;第二样本分词集包括至少一个第二样本分词;
4、从第一样本分词集中确定出与第二样本分词集相匹配的第一样本分词,并根据与第二样本分词集相匹配的第一样本分词生成第一样本分词集中各个第一样本分词的词权重标注信息;
5、将各个第一样本分词依次输入初始分词处理模型,由初始分词处理模型对各个第一样本分词进行分词处理,得到各个第一样本分词的词权重预测信息;
6、通过词权重预测信息和词权重标注信息迭代训练初始分词处理模型,得到用于确定文本分词的词权重的目标分词处理模型。
7、一方面,本申请实施例提供了一种数据处理装置,该装置包括:
8、获取模块,用于获取样本文本对;样本文本对包括第一样本文本以及与第一样本文本相匹配的第二样本文本;第一样本文本为目标关键领域中的召回文本,第二样本文本为目标关键领域中的查询文本;第一样本文本关联有第一样本分词集,第二样本文本关联有第二样本分词集;第一样本分词集包括至少一个第一样本分词;第二样本分词集包括至少一个第二样本分词;
9、处理模块,用于从第一样本分词集中确定出与第二样本分词集相匹配的第一样本分词,并根据与第二样本分词集相匹配的第一样本分词生成第一样本分词集中各个第一样本分词的词权重标注信息;
10、处理模块,还用于将各个第一样本分词依次输入初始分词处理模型,由初始分词处理模型对各个第一样本分词进行分词处理,得到各个第一样本分词的词权重预测信息;
11、处理模块,还用于通过词权重预测信息和词权重标注信息迭代训练初始分词处理模型,得到用于确定文本分词的词权重的目标分词处理模型。
12、一方面,本申请实施例提供了一种电子设备,该电子设备包括处理器和存储器,其中,存储器用于存储计算机程序,该计算机程序包括程序指令,处理器被配置用于调用该程序指令,执行上述方法中的部分或全部步骤。
13、一方面,本申请实施例提供了一种计算机可读存储介质,该计算机可读存储介质存储有计算机程序,该计算机程序包括程序指令,该程序指令被处理器执行时,用于执行上述方法中的部分或全部步骤。
14、相应地,根据本申请的一个方面,提供了一种计算机程序产品或者计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令被处理器执行时可实现上述方法中的部分或全部步骤。
15、本申请实施例中,可以获取样本文本对;样本文本对包括目标关键领域下的第一样本文本和第二样本文本,且第一样本文本为召回文本,第二样本文本为查询文本;从第一样本分词集中确定出与第二样本分词集相匹配的第一样本分词,并根据与第二样本分词集相匹配的第一样本分词生成第一样本分词集中各个第一样本分词的词权重标注信息;该词权重标注信息可以有效结合第一样本文本和第二样本文本之间的相关匹配信息;将各个第一样本分词依次输入初始分词处理模型,由初始分词处理模型对各个第一样本分词进行分词处理,得到各个第一样本分词的词权重预测信息;通过词权重预测信息和词权重标注信息迭代训练初始分词处理模型,得到用于确定文本分词的词权重的目标分词处理模型;该可以实现对特定领域下的召回文本的词权重确定,同时在训练初始分词处理模型时,不仅可以结合所在目标关键领域的相关领域信息,还可以结合第一样本文本内部的相关特征信息,从而可以提高目标分词处理模型对于文本分词的词权重的确定准确性。
技术特征:
1.一种数据处理方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述从所述第一样本分词集中确定出与所述第二样本分词集相匹配的第一样本分词,包括:
3.根据权利要求1所述的方法,其特征在于,所述根据与所述第二样本分词集相匹配的第一样本分词生成所述第一样本分词集中各个第一样本分词的词权重标注信息,包括:
4.根据权利要求1所述的方法,其特征在于,所述方法还包括:
5.根据权利要求4所述的方法,其特征在于,所述方法还包括:
6.根据权利要求5所述的方法,其特征在于,所述根据与所述第二目标文本相匹配的文本分词的词权重预测信息确定所述第一目标文本和所述第二目标文本之间的文本匹配度,包括:
7.根据权利要求5所述的方法,其特征在于,所述第一目标文本为多个;所述根据与所述第二目标文本相匹配的文本分词的词权重预测信息确定所述第一目标文本和所述第二目标文本之间的文本匹配度,包括:
8.一种数据处理装置,其特征在于,所述装置包括:
9.一种电子设备,其特征在于,包括处理器和存储器,其中,所述存储器用于存储计算机程序,所述计算机程序包括程序指令,所述处理器被配置用于调用所述程序指令,执行如权利要求1-7任一项所述的方法。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机程序,所述计算机程序包括程序指令,所述程序指令当被处理器执行时使所述处理器执行如权利要求1-7任一项所述的方法。
技术总结
本申请实施例公开了一种数据处理方法、装置、设备及介质,应用于数据处理技术领域。其中方法包括:获取样本文本对,从第一样本分词集中确定出与第二样本分词集相匹配的第一样本分词,并根据与第二样本分词集相匹配的第一样本分词生成第一样本分词集中各个第一样本分词的词权重标注信息,将各个第一样本分词依次输入初始分词处理模型,由初始分词处理模型对各个第一样本分词进行分词处理,得到各个第一样本分词的词权重预测信息,通过词权重预测信息和词权重标注信息迭代训练初始分词处理模型,得到用于确定文本分词的词权重的目标分词处理模型。采用本申请实施例,可以提高文本分词的词权重的确定准确性。
技术研发人员:李军伟
受保护的技术使用者:小红书科技有限公司
技术研发日:
技术公布日:2024/3/21
- 还没有人留言评论。精彩留言会获得点赞!