一种基于FPGA的A3C深度强化学习算法加速器
本发明涉及人工智能的深度强化学习,特别是一种基于fpga的a3c深度强化学习算法加速器。
背景技术:
1、a3c(asynchronous advantage actor-critic,a3c)算法是一种典型的深度强化学习(deep reinforcement learning,drl)算法,通过采用分布式学习与异步训练的方式,能够很好的打破训练数据的相关性,提高智能体的训练效率和训练结果。a3c算法构建一个中心智能体(central agent)作为分布式智能体模板,并将该模板复制n份后构成n个本地智能体(local agent),分别放入n个独立的环境中进行交互,而每个智能体都可视作一个独立的actor-critic(ac)智能体,在分布式框架下,每个智能体都能在互不干扰的情况下按照ac算法流程与环境进行交互获得经验值,并完成神经网络参数梯度值计算。由于分布式异步学习框架的引入,a3c算法的算法复杂度和计算量较大,因此如何在现有的硬件平台上实现高性能且低功耗的a3c算法具有一定的研究意义和实际价值。
2、a3c算法的硬件实现平台主要分为四种:通用处理器cpu、图形处理器gpu、专用集成电路asic以及现场可编程逻辑门阵列fpga。cpu受限于串行的执行模式和有限的数据带宽,在功耗和延时两个方面都无法满足a3c算法运算的需求,因此目前a3c算法的硬件加速一般基于gpu、asic和fpga平台。由于a3c算法在训练中采用小批量的样本来进行计算,因此,在使用gpu执行该算法的计算任务时利用率较低,使得a3c算法并不容易被gpu加速。fpga具有可编程性、可重构性、高并行性以及低功耗等优点,相比于gpu和asic固定的硬件结构,fpga可以设计适应各种深度强化学习算法的硬件结构,同时,与cpu和gpu相比,fpga在单位功耗下可以获取更高的性能,具有更加出色的能耗比和加速比。现有基于fpga的深度强化学习算法加速器大多是针对以dqn(deep q network,dqn)为代表的单智能体drl算法,而在分布式drl算法加速方面研究较少。因此,对分布式深度强化学习算法展开fpga加速器研究,在实现其分布式异步学习框架的同时,提升该算法的执行速度,缩短其训练周期,是非常值得研究的一个问题。
技术实现思路
1、本发明所要解决的技术问题是克服现有技术的不足而提供一种基于fpga的a3c深度强化学习算法加速器,采用计算并行、流水线设计的加速策略,并通过多模块部署实现a3c深度强化学习智能体的所有计算步骤;通过将存储区域划分为多个独立空间,在计算单元部署多个pe实现a3c算法的分布式学习框架;通过在参数更新单元中对智能体的参数更新顺序进行控制,实现a3c算法的异步学习框架。
2、本发明为解决上述技术问题采用以下技术方案:
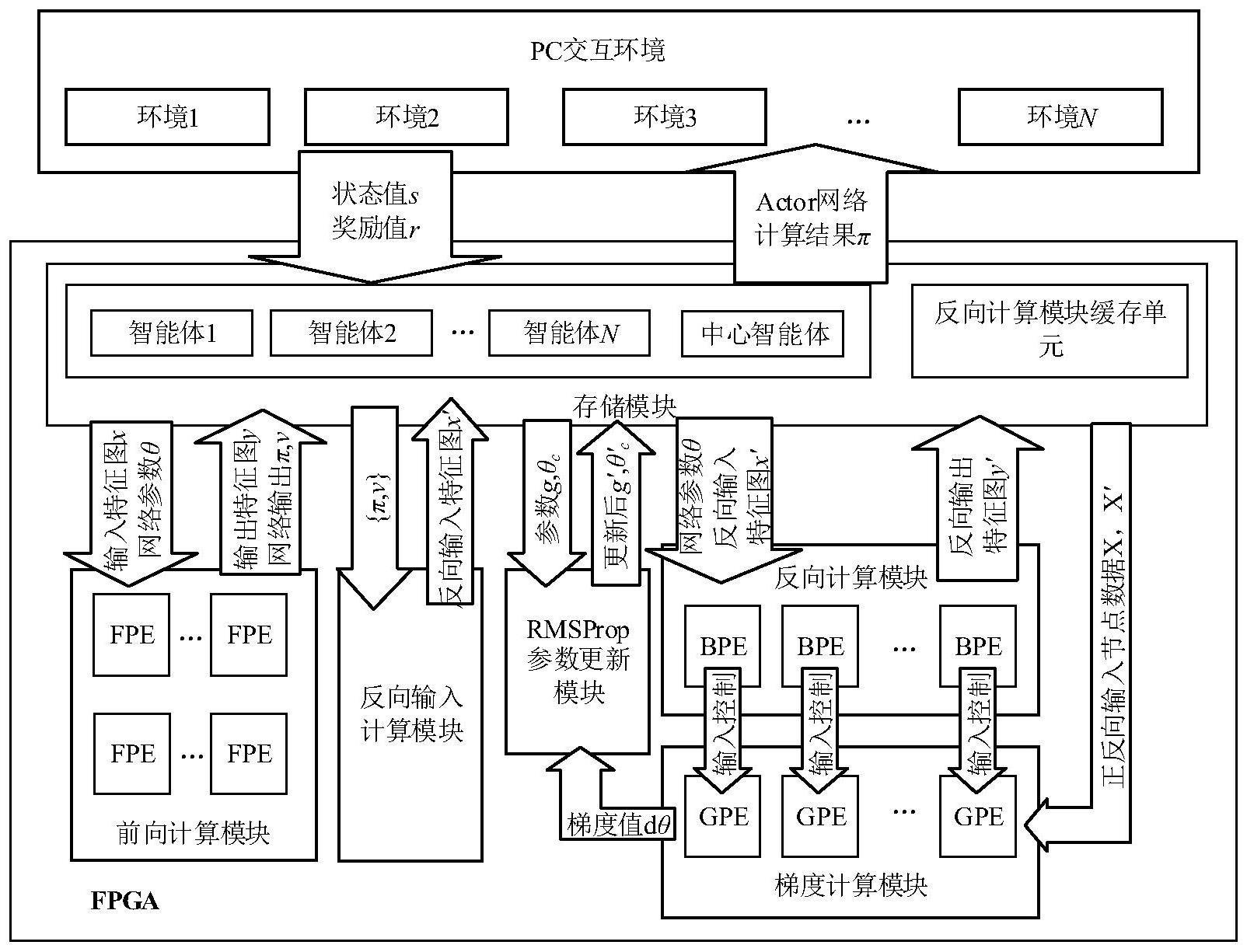
3、根据本发明提出的一种基于fpga的a3c深度强化学习算法加速器,包括用于提供交互环境的上位机和用于计算加速的fpga加速器,fpga加速器包括存储模块、前向计算模块、反向计算模块、反向输入计算模块、梯度计算模块和rmsprop参数更新模块,其中,
4、前向计算模块包括n个并行计算的fpe模块,fpe模块包括第一矩阵计算单元、relu激活单元和softmax激活单元;其中,
5、计算共享层时:
6、第一矩阵计算单元,用于从存储模块中读取输入特征图x和网络参数θ、对x和网络参数θ进行矩阵乘法运算后输出运算结果a至relu激活单元和存储模块;
7、relu激活单元,用于对第一矩阵计算单元输出的运算结果a进行激活运算后输出特征图y至存储模块缓存;
8、计算输出层时:
9、第一矩阵计算单元,用于从存储模块中读取y和网络参数θ,对y和网络参数θ进行线性相乘求和,得出一个critic网络输出值v输出至存储模块;
10、softmax激活单元,用于对并行读入的共享层的计算结果进行处理,共享层的计算结果指y,得到一组actor网络输出值π并将其输出至存储模块;
11、反向输入计算模块,用于根据存储模块中的a3c智能体网络输出层计算结果,计算反向输入特征图x’并将其输出至存储模块,a3c智能体网络输出层计算结果为actor网络输出值π和critic网络输出值v,x’包括actor网络反向输入图y’π和critic网络的反向输入图y’v;
12、反向计算模块包括n个并行计算的bpe模块,其中,
13、bpe模块,用于对正向输入节点数据x、反向输入特征图x’和网络参数θ进行处理,得到反向输出特征图y’并将其输出至存储模块;其中,正向输入节点数据x指未经relu激活操作的第一矩阵计算单元输出的运算结果a;
14、梯度计算模块包括n个并行计算的gpe模块,其中,
15、gpe模块,从存储模块中读取正向输入节点数据x和反向输入节点数据x’,x’指反向输入特征图x’或反向输出特征图y’,gpe模块对x和x’进行处理,输出一组网络参数梯度值dθ至rmsprop参数更新模块和存储模块;
16、rmsprop参数更新模块包括梯度聚合单元和参数更新单元,其中,
17、梯度聚合单元,用于根据从存储模块中读取的历史的梯度值、对dθ聚合计算,聚合后的梯度值输出至参数更新单元;
18、参数更新单元,用于根据聚合后的梯度值,对从存储模块中读取的历史网络参数进行更新计算,得到新的网络参数并将其输出至存储模块。
19、作为本发明所述的一种基于fpga的a3c深度强化学习算法加速器进一步优化方案,第一矩阵计算单元包括乘法器和加法器,relu激活单元包括0值比较器,softmax激活单元包括指数运算器、除法器和加法器。
20、作为本发明所述的一种基于fpga的a3c深度强化学习算法加速器进一步优化方案,前向计算模块的计算过程具体如下:
21、在计算共享层时,使用第一矩阵计算单元和relu计算单元,此时前向计算模块的计算过程包括以下步骤:
22、步骤11、从存储模块中读取输入特征图x和网络参数θ到第一矩阵计算单元;
23、步骤12、将读入的输入特征图x和网络参数θ送入第一矩阵计算单元的乘法-加法树结构中,x和θ将在相乘求和后与偏置相加;
24、步骤13、将第一矩阵计算单元输出结果作为输入数据送入relu激活单元,将输入数据与0进行比较,当输入数据小于0时,输出为0;当输入数据大于等于0时,输出数据并保持输入数据的大小不变,并将输出数据缓存至存储模块中,经过预设的时钟周期,完成所有输出的计算;
25、在计算输出层时,使用第一矩阵计算单元和softmax激活单元,此时前向计算模块的计算过程包括以下步骤:
26、步骤21、从存储模块中读取y和网络参数θ到第一矩阵计算单元,读取y至softmax激活单元;
27、步骤22、第一矩阵计算单元的乘法-加法树结构通过乘加方式,完成y与网络参数θ的线性相乘求和,得出一个critic网络输出值v;
28、步骤23、softmax激活单元以并行读入的共享层的计算结果作为输入数据,将输入数据转化为串行排列,得到串行序列,共享层的计算结果指y;
29、步骤24、将步骤23得到的串行序列送入指数运算器获得指数输出,然后通过累加器和除法器求出一组actor网络输出π。
30、作为本发明所述的一种基于fpga的a3c深度强化学习算法加速器进一步优化方案,反向输入计算模块包括乘法器、加法器和选择器;反向输入计算模块的计算过程包括以下步骤:
31、在计算actor网络反向输入图时,此时反向输入计算模块的计算过程包括以下步骤:
32、步骤31、从存储模块中读取l个actor网络层的输出结果π到反向输入计算模块中,π记为z1~zl,zi为第i个actor网络层的输出结果,zj为第j个actor网络层的输出结果,1≤i≤l,1≤j≤l;
33、步骤32、利用浮点数计算ip核对z1~zl进行取反、取对数、乘法和加法操作后得到1-lnzi、-zizj与zi(1-zi)结果;
34、步骤33、将步骤32得到的1-lnzi、-zizj与zi(1-zi)结果送入乘法-加法树结构,将乘法-加法树结构输出的计算结果分别与超参数c、时间误差δ相乘后求和得出actor网络反向输入图y’π;
35、在计算critic网络反向输入图时,此时反向输入计算模块的计算过程包括以下步骤:
36、步骤41、从存储模块中读取critic网络层的第一至第三个网络参数θw1~θw3到反向输入计算模块中。
37、步骤42、利用浮点数计算ip核对时间误差δ进行取反和扩大两倍的操作后将其送入乘法器中与网络参数矩阵相乘,即得出critic网络的反向输入图y’v。
38、作为本发明所述的一种基于fpga的a3c深度强化学习算法加速器进一步优化方案,bpe模块包括正负缓存单元、权重输入控制单元和第二矩阵计算单元,其中,所述正负缓存单元包括选择器和寄存器,用来记录正向输入节点数据的正负;所述权重输入控制单元包括选择器,用来根据正向输入节点数据的正负完成relu激活函数的求导运算;所述第二矩阵计算单元包括乘法器和加法器,第二矩阵计算单元用来完成反向输入特征图x’与权重输入控制单元输出之间的矩阵乘法运算,并将反向输出特征图y’输出至存储模块中。
39、作为本发明所述的一种基于fpga的a3c深度强化学习算法加速器进一步优化方案,反向计算模块的计算过程包括以下步骤:
40、步骤51、从存储模块读取网络参数θ、正向输入节点数据x和反向输入特征图x’到反向计算模块中,并用正负缓存单元记录下该层正向输入节点数据的正负;正向输入节点数据x指未经relu激活操作的第一矩阵计算单元的输出结果a;
41、步骤52、权重输入控制单元利用步骤51正负缓存单元存储的正负值,完成relu函数的求导运算,当正负值为0时,权重输入为0;当正负值为1时,权重输入为步骤51读取的网络参数;
42、步骤53、将权重输入控制单元的输出和反向输入特征图x’送入第二矩阵计算单元的乘法-累加器结构,经过一定时钟周期,完成反向输出特征图y’的计算。
43、作为本发明所述的一种基于fpga的a3c深度强化学习算法加速器进一步优化方案,每个gpe模块包括正负缓存单元、输入控制单元和n个并行乘法器;所述正负缓存单元包括选择器和寄存器,正负缓存单元的输入为正向输入节点数据x,正负缓存单元用来记录正向输入节点数据的正负;所述输入控制单元包括选择器,输入控制单元的输入为0和正向输入节点数据x,用来根据正向计算结果的正负完成relu激活函数的求导运算;n个并行乘法器用来完成反向输入节点数据x’,x’指反向输入特征图x’或反向输出特征图y’和输入控制单元输出之间的乘法运算,输出一组网络参数梯度值dθ至rmsprop参数更新模块;
44、梯度计算模块的计算过程如下:
45、步骤61、读取正向输入节点数据x和反向输入节点数据x’到梯度计算模块中;
46、步骤62、利用正负缓存单元和输入控制单元控制反向输入节点数据x’和正向输入节点数据x相乘得到梯度计算结果,经过一定时钟周期,可以完成所有梯度值的计算。
47、作为本发明所述的一种基于fpga的a3c深度强化学习算法加速器进一步优化方案,rmsprop参数更新模块包括梯度聚合单元和参数更新单元;所述梯度聚合单元包括多个并行度为n的加法器阵列,梯度聚合单元的输入为梯度计算模块传来的网络参数梯度值dθ,用来完成梯度计算模块中每个gpe模块的梯度聚合计算,计算完成后将聚合后的梯度值输出至参数更新单元;所述参数更新单元包括乘法器、加法器和寄存器,参数更新单元从存储模块中读取历史网络参数,并利用梯度聚合单元的计算结果进行参数更新计算,然后将新的网络参数输出至存储模块。
48、作为本发明所述的一种基于fpga的a3c深度强化学习算法加速器进一步优化方案,rmsprop参数更新模块的计算过程如下:
49、步骤71、从梯度计算模块中读取梯度值dθ,从存储模块中将历史梯度dθ’读入到梯度聚合单元;
50、步骤72、对读取的梯度值进行求和计算,然后将计算结果送入存储模块,经过一定时钟周期,完成梯度聚合计算;
51、步骤73、当梯度聚合计算完成时,读取控制信号传入先进先出存储器fifo中,待到参数更新单元空闲时,选择器将fifo读端口的控制信号读出,同时访问中心智能体参数存储器与控制信号所对应智能体的梯度值缓存器,进行梯度更新计算,并将更新后的网络参数值传入存储模块。
52、作为本发明所述的一种基于fpga的a3c深度强化学习算法加速器进一步优化方案,存储模块包括片上bram,片上bram包括智能体数据存储单元与反向计算模块缓存单元,智能体数据存储单元为包括中心智能体缓存和n个本地智能体缓存,中心智能体缓存用于存储中心网络参数θc,而每个本地智能体的存储分为参数θ缓存、参数g缓存、梯度值缓存和前向计算缓存;其中,参数θ缓存用于对本地智能体深度神经网络参数θ进行存储;参数g缓存对本地智能体所维护的rmpprop参数g进行存储;梯度值缓存用于对本地智能体的梯度值计算结果进行存储;前向计算缓存用于对本地智能体在推理计算过程中深度神经网络每一层的输入、输出进行存储;反向计算模块缓存单元为每个bpe分配了一个中间结果缓存区,用于对反向计算中深度神经网络传播产生的中间计算结果进行存储。
53、本发明采用以上技术方案与现有技术相比,具有以下技术效果:
54、(1)本发明提出了一种a3c深度强化学习算法fpga加速器架构,该架构通过独立的存储和计算模块部署实现了a3c算法的分布式框架,通过对参数更新计算过程的控制模块设计实现a3c算法的异步框架。
55、(2)本发明提出异构的计算结构部署方式,可以实现在最少存储开销的前提下,用最短的时钟周期完成权重数据的访问,有着较高权重存储的访问效率。
56、(3)本发明的加速器相对于通用处理器具有高能效的特点。
- 还没有人留言评论。精彩留言会获得点赞!