一种基于深度强化学习的GPU动态能源效率优化运行时方法及系统
本发明涉及效率优化,具体涉及一种基于深度强化学习的gpu动态能源效率优化运行时方法及系统。
背景技术:
1、图形处理单元(graphs processing units,gpu)是许多计算系统上的主流计算设备,被广泛用于加速的计算任务,在新型材料研究、生物分子研究、天气预报、石油勘探等大规模计算领域具有关键的加速作用,并且在新兴的人工智能和大数据等计算密集型和数据密集型产业中发挥重要的作用。超大规模集成电路技术将数百亿个晶体管集成到一个芯片,大幅提升gpu计算能力的同时产生高能耗。gpu的高功耗将影响计算系统的可靠性、经济可行性和运营成本。例如,天河二号峰值计算速度每秒达5.49亿亿次、持续计算速度每秒3.39亿亿次,但是它的电力消耗达到了17.81mw,工作一小时的电费高达1000万以上。功耗增加的同时会带来温度的考验,进而影响处理器总体性能,降低系统的可靠性。耗和冷却基础设施贡献了很大一部分的运营成本。因此,gpu功耗问题是gpu广泛应用必须解决的问题之一。
2、目前,动态电压频率调整(dynamic voltage frequency scaling,dvfs)技术被广泛应用于处理器的低功耗优化。gpu功率管理可以通过频率封顶来实现,通过限制最大gpu时钟频率控制gpu功耗。在cpu领域中已提出了广泛的基于dvfs的功率管理方法、基于机器学习的管理方法、基于领域专家的启发式方法和基于分析模型的方法。然而,由于处理器频率和应用程序性能之间存在复杂的非线性关系,许多特定于cpu的技术不能转移到gpu中。
3、现有的gpu功耗研究主要缺乏对gpu上程序执行过程的准确分析因而难以根据程序的特征有针对性地对电压/频率进行调节。多数关于gpu能源的工作都依赖于针对gpu架构的离线分析信息。例如,芯片供应商提供的硬件性能计数器统计程序执行时的性能特征或者通过对gpu程序进行插桩获取程序运行时性能特征,然而,前者会产生大量的分析开销,后者会破坏程序的完整性。因此,在gpu上进行动态能源效率的优化仍然是一个巨大的挑战。
技术实现思路
1、为了解决上述技术缺陷之一,本发明提出一种基于深度强化学习的gpu动态能源效率优化运行时方法及系统。
2、根据本发明的一方面,提供了一种基于深度强化学习的gpu动态能源效率优化运行时方法,所述深度强化学习为优先经验回放的双深度q网络算法,所述方法包括:
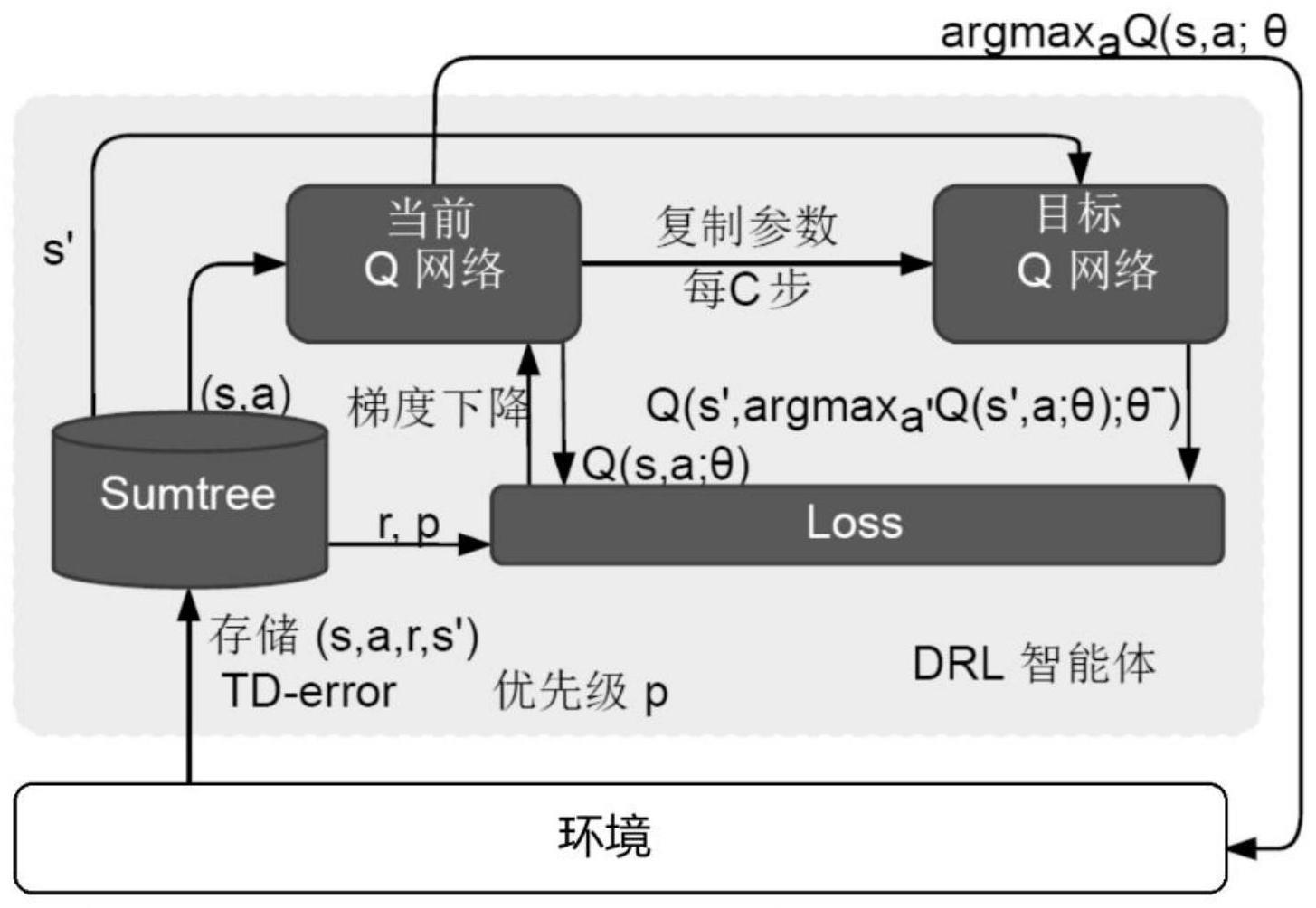
3、将gpu中应用程序工作负载的环境状态当作优先经验回放的双深度q网络的状态,将gpu功率配置当作优先经验回放的双深度q网络的动作,训练基于优先经验存储双深度q网络的gpu动态能源效率优化模型;其中,gpu中应用程序工作负载的环境状态包括gpu核心利用率、gpu内存利用率、功率、gpu频率和gpu温度;所述双深度q网络的当前q网络用于选择最优的gpu频率配置,目标q网络用于评估选择的最优gpu频率配置对能源效率的影响;
4、从训练得到的gpu动态能源效率优化模型中为当前状态选择一个最佳的gpu功率封顶配置,通过gpu频率封顶配置调整能耗。
5、进一步地,训练基于优先经验存储双深度q网络的gpu动态能源效率优化模型的过程包括:
6、初始化当前网络q和目标网络q',以及其他相关参数;
7、初始化经验回放缓冲区;
8、按照如下步骤进行迭代更新:
9、获取当前gpu的状态s,初始化s为当前状态序列的第一个状态,得到状态的特征向量φ(s);
10、在当前网络q中使用特征向量φ(s)作为输入,得到当前网络的所有动作对应的q值输出;
11、利用∈-贪婪算法在当前q值输出中选择对应的动作a;
12、执行当前动作a,观察下一个状态s'对应的特征向量φ(s')和奖励r;
13、将经验存储到经验回放缓存区中;从经验回放缓存区中采样m个经验;其中,所述经验包括当前状态对应的特征向量φ(s)、动作a、奖励r、下一个状态s'对应的特征向量φ(s');
14、使用当前网络q计算当前状态下所有动作的q值qcurrent;
15、使用目标网络q'计算下一个状态所有动作的q值,选择具有最高q值的动作,然后根据贝尔曼方程计算目标q值qtarget;
16、根据当前状态下所有动作的q值qcurrent和目标q值qtarget,计算样本的时序差分误差,更新样本的优先级;使用均方误差计算损失loss,使用梯度下降法更新当前q网络的参数,以最小化损失loss;
17、若迭代次数达到目标网络参数更新频率,则更新目标网络的参数;并更新状态为下一状态。
18、进一步地,训练基于优先经验存储双深度q网络的gpu动态能源效率优化模型过程中的奖励r按如下方式计算:
19、当gpu内存利用率为零且gpu核心利用率为零时,奖励r的计算公式为:
20、
21、其中,c是一个常数,a是当前设置的gpu频率上限,频率上限越小,奖励越大;
22、当gpu内存利用率为零且gpu核心利用率为百分之百时,奖励r的计算公式为:
23、
24、其中,r1>r2>r3>r4,p1<p2<p3,均为常数;δp表示功耗的变化,功率变化越小,奖励越大;
25、当gpu内存利用率为零且gpu核心利用率在零和百分之百之间时,奖励r的计算公式为:
26、r=g/ucore
27、其中,ucore表示gpu核心利用率,g表示使用分段线性回归方法在细粒度水平上的分配分数;
28、当gpu内存利用率和gpu核心利用率为不满足以上条件的其他条件时,奖励r的计算公式为:
29、r=g/umem
30、其中,umem表示gpu内存利用率。
31、进一步地,奖励r的计算过程中,根据gpu频率变化δfreq和gpu功耗变化δpower确定分配分数g:
32、当gpu功耗变化δpower小于或等于零时,通过分段线性回归函数得到分配分数g如下:
33、
34、其中,g1>g2>g3>g4>g5均为常数,n为正整数,step表示gpu频率的步长;
35、当gpu功耗变化δpower大于零时,通过分段线性回归函数得到分配分数g如下:
36、
37、进一步地,训练基于优先经验存储双深度q网络的gpu动态能源效率优化模型过程中使用重要性采样权重调整损失函数,重要性采样权重计算如下:
38、wj=(n*p(j))-β/maxi(wi)
39、式中,n表示经验回放缓冲区的大小;p(j)表示每个样本被采样的概率,即样本的优先级;β表示采样权重系数;maxi(wi)表示所有样本的最大权重;wi表示重要性采样权重。
40、进一步地,训练基于优先经验存储双深度q网络的gpu动态能源效率优化模型过程中目标q值qtarget的计算公式如下:
41、
42、式中,rj表示第j个样本的奖励;γ表示衰减因子;q'(φ(s'j))表示通过目标网络计算的下一个状态的q值;φ(s'j)表示下一个状态的特征向量;argmaxa'q(φ(s'j)表示通过当前网络计算下一个状态q值中最大q值对应的动作;θ表示目标网络q'的参数,θ’表示当前网络的参数。
43、进一步地,训练基于优先经验存储双深度q网络的gpu动态能源效率优化模型过程中的均方差损失函数计算如下:
44、
45、式中,m表示批量梯度下降的样本数;q(φ(sj)表示第j个样本通过当前网络q计算当前状态下的q值;aj表示第j个样本在当前状态采取的动作;yj表示第j个样本的目标q值;
46、每个样本的优先级通过时序差分误差计算如下:
47、δj=yj-q(φ(sj)aj,θ)。
48、根据本发明的另一方面,提供了一种基于深度强化学习的gpu动态能源效率优化运行时系统,该系统包括工作负载监控器、能源效率评估器、功率配置优化器和功率控制器;其中,
49、工作负载监控器配置成:检测并获取gpu应用程序工作负载中的环境状态;
50、功率配置优化器配置成:将gpu中应用程序工作负载的环境状态当作优先经验回放的双深度q网络的状态,将gpu功率配置当作优先经验回放的双深度q网络的动作,训练基于优先经验存储双深度q网络的gpu动态能源效率优化模型;其中,gpu中应用程序工作负载的环境状态包括gpu核心利用率、gpu内存利用率、功率、gpu频率和gpu温度;双深度q网络的当前q网络用于选择最优的gpu频率配置;
51、能源效率评估器配置成:双深度q网络的目标q网络根据当前阶段的gpu功耗和频率的变化来评估当前gpu频率配置对能源效率的影响;
52、功率控制器配置成:从训练得到的gpu动态能源效率优化模型中为当前状态选择一个最佳的gpu功率封顶配置,通过gpu频率封顶调整功能耗。
53、本发明的有益技术效果是:
54、本发明提出一种基于深度强化学习的gpu动态能源效率优化运行时方法及系统,以自动学习gpu工作负载阶段到功率硬件配置的映射,使得动态调整的功率配置能够在不显著影响程序执行时间的情况下降低gpu的能耗。本发明根据gpu资源的使用情况,低开销且动态地识别gpu程序工作负载变化;通过基于启发式的奖惩函数权衡该频率封顶对能耗和性能的影响,在较小的程序性能损失下,降低整个程序执行时的总能耗;通过深度强化学习算法,根据奖惩函数自动地为不同的工作负载设置最佳的gpu频率封顶。本发明实现了动态且自动的现代gpu处理器的能源效率优化,并且运行时系统的开销很小。
- 还没有人留言评论。精彩留言会获得点赞!