面向大场景点云物体检测的自监督对比学习方法及系统与流程
本发明涉及机器视觉,尤其涉及面向大场景点云物体检测的自监督对比学习方法及系统。
背景技术:
1、激光雷达传感器可以提供比传统二维相机更高的定位精度,使其成为自动驾驶视觉感知系统的一种理想的补充。基于激光雷达的三维(3d)物体检测可以从原始激光雷达点云中估计出物体的位置、方向和语义类别,近年来在产业中得到了广泛应用。
2、然而,室外激光雷达点云具有稀疏性、遮挡和分布不均等自然属性。使得从大场景点云中进行物体检测是存在挑战性的。在近年来公开的大规模自动驾驶数据集(如waymo、nuscenes和kitti等)的基础上,基于激光雷达点云的3d检测任务取得了巨大进展。然而,传统的3d检测器都是建立在足够规模的标注数据之上的。尽管随着激光雷达的普及,3d数据采集变得更加容易,但大规模点云数据的精准标注则需要耗费大量人工成本和时间成本。而且即使采用这种高成本的标注数据进行3d检测器的训练,不同地理环境或不同传感器配置所导致的雷达数据域差异也会导致在一个数据集上训练的检测器通常在另一个数据集上表现欠佳。因此,如何从大量未标注的室外点云数据中学习到具有泛化性、迁移性的点云特征,从而提高物体检测精度,是实现自动驾驶的安全性的关键问题。
3、为了高效利用大规模未标注数据,自监督学习提供了一种可行的技术方案。目前,面向大场景点云的自监督学习通常有两种范式,即基于重构的方法和基于对比学习的方法。理想的自监督学习技术应当能够有效地提高少量有标注数据的下游任务性能,并且在未标注的同类数据上实现较合理的迁移性能。
4、其中,在基于对比学习的方法中需要考虑两个关键问题,即如何确定对比学习中的对比实例,以及如何提高检测器在未标注数据上的定位精度。在对比实例的确定方面,现有的对比学习方法通常将整个视图(例如整张图像或整场点云)描述为一个全局特征,这类方法更适合于物体实例级别的分类任务。对于户外检测任务,它需要从稀疏和不均匀分布的点云中定位和识别出各种运动物体。因而,它需要更加细粒度的区分实例。已有的基于对比学习的大场景点云预训练方法通常从原始输入空间(坐标空间)中采集子区域作为对比实例。具体而言,将原始点云划分为具有固定大小和固定数量的实例(如球状的或长方体状的)。然而,具有固定尺寸的坐标空间实例难以平衡局部细节和全场景信息,并且可能忽略不同子区域之间的语义关联性。
5、在提高模型的检测精度方面,现有的面向大场景点云的对比学习没有考虑到与检测任务相关的预训练目标。这类方法可以学习到有区分性的点云特征,但其学习到的特征与具体的物体检测任务关系并不明显。其次,随机从原始空间采集子区域作为对比样本的方法可能给模型的训练带来模糊性干扰。因为具有相似几何特征的子区域也可能被分配为负样本;并且随机采集样本的方法很可能采集到大量简单的背景样本,不利于挖掘到有助于训练的困难样本。此外,固定尺寸和固定数量的样本定义难以平衡大尺度目标(如汽车)与细粒度目标(如行人)的检测。
技术实现思路
1、本发明提出了一种针对大场景点云物体检测的新型自监督对比学习方法,旨在提供面向自动驾驶场景的物体检测预训练框架,减少人工标注成本,并且使3d检测器在不同自动驾驶数据集上更加有效。
2、本发明在第一方面提供了一种面向大场景点云物体检测的自监督对比学习方法,包括:
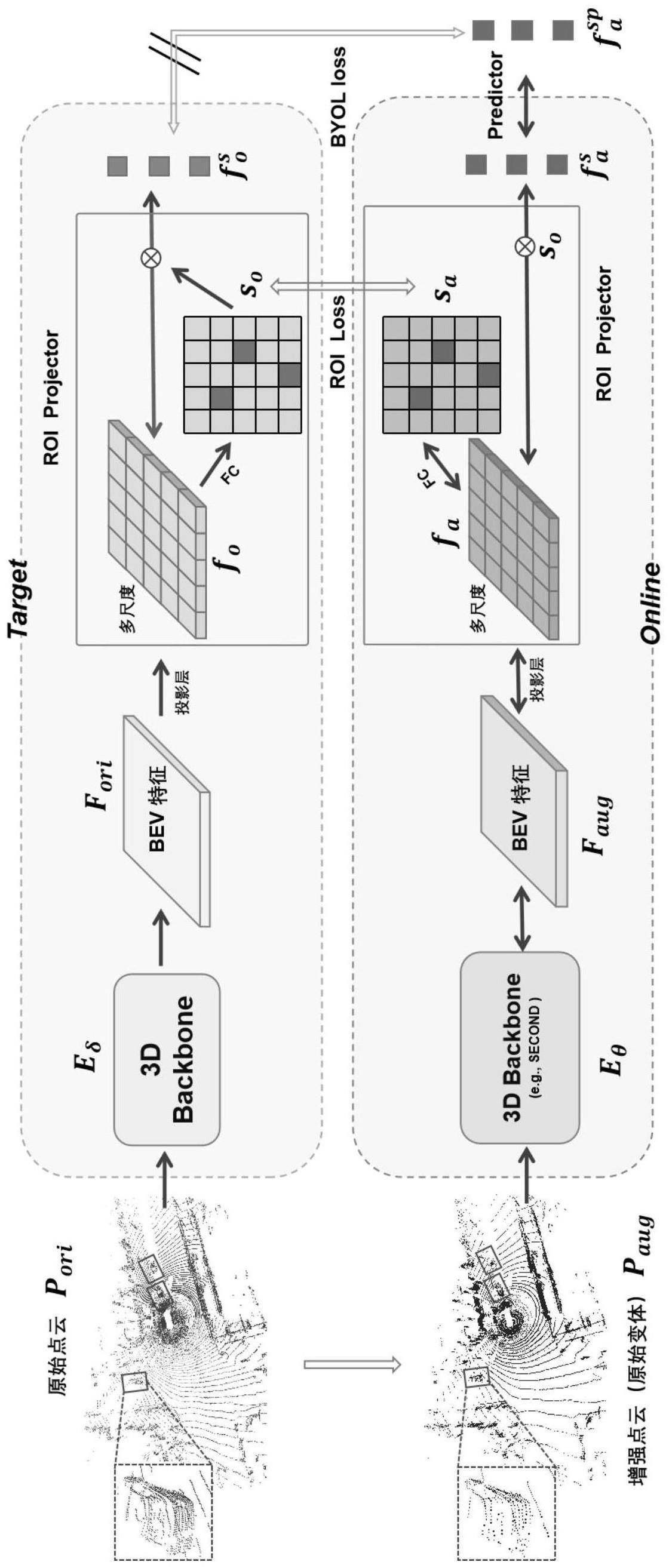
3、将原始点云进行转换操作得到增强点云,并将所述原始点云和所述增强点云分别输入到目标网络和在线网络,分别得到所述原始点云对应的原始bev特征图和所述增强点云对应的增强bev特征图;
4、将所述原始bev特征图和所述增强bev特征图划分成多个子区域,计算每个子区域的roi得分,获取与所述原始bev特征图和所述增强bev特征图相对应的得分图;
5、基于排序后的roi得分,从所述得分图中确定候选子区域,将所述候选子区域的bev特征确定为对比学习中的对比实例,以利用所确定的对比实例进行点云物体检测模型预训练。
6、优选地,所述将所述原始bev特征图和所述增强bev特征图划分成多个子区域,计算每个子区域的roi得分,获取与所述原始bev特征图和所述增强bev特征图相对应的得分图,进一步包括:
7、将所述原始bev特征图和所述增强bev特征图划分成多个预定义大小的子区域特征图;
8、对每个子区域通过投影运算,得到roi子区域特征;
9、通过全连接层计算每个roi子区域特征相关的roi得分,形成得分图。
10、优选地,所述得分图包括与原始bev特征相对应的原始得分图和与增强bev特征相对应的增强得分图,并且在获取所述得分图之后,该方法还包括:
11、通过计算所述原始得分图与所述增强得分图之间的二元交叉熵bce损失,实现roi区域的定位。
12、优选地,所述目标网络和在线网络分别包括3d骨干网络eδ和eθ,用于根据所述原始点云和增强点云分别生成原始bev特征和增强bev特征;
13、其中参数δ采用动量更新的方式:
14、δ←τδ+(1-τ)θ
15、其中τ∈[0,1]是预定义的温度参数,δ和θ分别表示3d骨干网络eδ和eθ对应的可学习参数。
16、本发明在第二方面提供了一种面向大场景点云物体检测的自监督对比学习系统,包括:
17、bev特征提取模块,用于将原始点云进行转换操作得到增强点云,并将所述原始点云和所述增强点云分别输入到目标网络和在线网络,分别得到所述原始点云对应的原始bev特征图和所述增强点云对应的增强bev特征图;
18、多尺度roi投影模块,用于将所述原始bev特征图和所述增强bev特征图划分成多个子区域,计算每个子区域的roi得分,获取与所述原始bev特征图和所述增强bev特征图相对应的得分图;
19、roi区域感知对比学习模块,用于基于排序后的roi得分,从所述得分图中确定候选子区域,将所述候选子区域的bev特征确定为对比学习中的对比实例,以利用所确定的对比实例进行点云物体检测模型预训练。
20、本发明又一方面提供了一种电子设备,包括处理器和存储器,所述存储器存储有多条指令,所述处理器用于读取所述指令并执行前述第一方面的方法。
21、本发明又一方面提供了一种计算机可读存储介质,所述计算机可读存储介质存储有多条指令,所述多条指令可被处理器读取并执行前述第一方面的方法。
22、本发明的有益效果是:本发明从bev特征空间确定对比学习实例,并采用专门用于3d物体检测的基于roi区域感知的自监督对比学习框架,通过对从bev特征空间中采样的每个候选子区域进行打分,以筛选出信息丰富的、与检测任务相关的roi特征,并采用多尺度的对比学习方式,能够更好地考虑局部细节和全场景信息,以及相邻子区域之间的语义关联,使得bev空间上的roi区域与物体检测任务更加相关,避免采集到大量无关的负样本,在训练优化损失函数的驱动下,随着训练的进行,模型可以更加准确地自动定位出有效的roi区域,并在细粒度目标与较大尺度目标两方面进行更好的平衡,更有效地同时挖掘出大尺度物体与细粒度物体特征。
- 还没有人留言评论。精彩留言会获得点赞!