一种识别弹奏乐中错误动作的方法与流程
本发明涉及基于插值的跨模态的对比学习算法,具体来讲,是使用了基于动量编码的对比学习框架,设计了一种内插值和外插值的方法用做数据增强,并且设计了一种重构对比学习中负样本的方法。可以实现动作与音频双模态的输入下对人们弹奏音乐过程中的动作失误进行识别。
背景技术:
1、弹奏音乐已经成为许多人的爱好和职业。在弹奏音乐的过程中很容易出现一些难以察觉的错误习惯。比如,不准确的手指摆放位置、错误的高低音等。这些错误靠学者自身或者老师进行纠错是比较困难的。这种潜在的错误的弹奏习惯会影响演奏的质量,还会一定程度上对手关节造成伤害。
2、在技术层面,对手部的动作识别的常用的方法是在标注的数据集上进行监督学习,但这需要大量的标注数据和人工劳动力,而且标注过程很繁琐,也容易出现主观性问题。而自监督学习是一种通过学习数据本身的特征而不是标签进行学习的方法,能够有效减少标注数据的需求。因此,不充分的数据标签成为了动作识别的主要挑战。为了减少对标签的依赖,研究人员开发了一种称为对比学习的自监督范式,并且的确可以在计算机视觉任务中获得优异的性能。
3、对比学习的主要过程就是在预训练过程中通过数据增强来获得大量的伪标签,使模型能够区分哪些增强的实例是正对、哪些是负对。通过预训练之后,模型可以使用少量的标记数据在下游任务中进行微调,并且可以获得与监督学习同等的竞争力。其中有许多类型的对比学习用于预训练任务,包括moco(momentum contrast,动量对比)、moco.v2和simclr(simple framework for contrastive learning of visual representations,对比学习视觉表示的简单框架)是使用示例判别作为任务,nnclr(nearest-neighborcontrastive learning of visual representations,最近邻对比学习视觉表示)、msf(mean shift feature,均值漂移特征)使用基于正负样本重定义的方法。
4、数据增强在对比学习中被认为是非常关键的,它可以为同一个语义表示设计各种运动模式,并且直接影响模型学习的特征表示的质量,不同于rgb的人体动作识别,3d骨架数据具有更复杂的模态表示,对形态变化更加敏感,所以对于增强方法的设计更为困难。对比学习用于骨架动作识别的核心内容在于数据增强的设计以及正负样本的构建方法。并且在数据集构建的过程中,采集弹奏音乐时,人手错误习惯弹奏的数据比采集基于类的动作识别的动作数据更加困难。
技术实现思路
1、本发明基于现有深度学习技术,提出了一种识别弹奏乐中错误动作的方法,基于动量编码的对比学习框架,设计了一种内插值和外插值的方法用做数据增强,并且设计了一种重构对比学习中负样本的方法。可以实现动作与音频双模态的输入下对人们弹奏音乐过程中的动作失误进行自动纠正。
2、本发明的一种识别弹奏乐中错误动作的方法,包括如下步骤:
3、步骤1,采集弹奏错误的音视频原始数据集hm(b,n)和as(b,n),其中hm(b,n)是手部动作数据集,as(b,n)是对应的音频数据集,原始数据集包括原始样本x,包括原始的手部动作数据和对应的音频数据。
4、步骤2,对原始样本进行数据增强;
5、步骤3,构建对比学习模型;
6、在进入编码器后进行内插值计算。特别在外插值过程中使用了帧间和帧内插值,减少了本发明数据采集,提高了数据质量。
7、步骤4,将原始数据集、进行数据增强后的数据集输入到对比学习模型,对模型进行训练,得到训练好的对比学习模型。
8、进一步的,步骤2中对原始样本进行数据增强,具体包括如下:
9、对原始动作数据集hm(b,n)中的原始样本x进行翻转、旋转和随机遮掩得到普通增强数据xen;
10、再对普通增强数据xen进行外插值增加,得到外插值增强数据xex。
11、进一步的,本发明使用原始样本和弱增强数据在进入编码器前进行外插值计算,所述外插值增加包括两个步骤,帧内插值和帧间插值:
12、(2)帧内插值:
13、将原始样本x和样本增强数据xen进行逐帧融合;融合后进行帧间插值,融合数据长度扩充到原来的m倍;
14、经过帧内插值生成的帧内插值序列m:
15、
16、
17、其中,n为原始样本x的时序长度,设置为50,i表示第i帧。
18、(2)使用帧内插值生成序列m做帧间插值,即在帧与帧之间在生成几帧,以扩充数据,最后得到外插值的增强数据。
19、具体为,对序列m进行时域上的帧间插值:
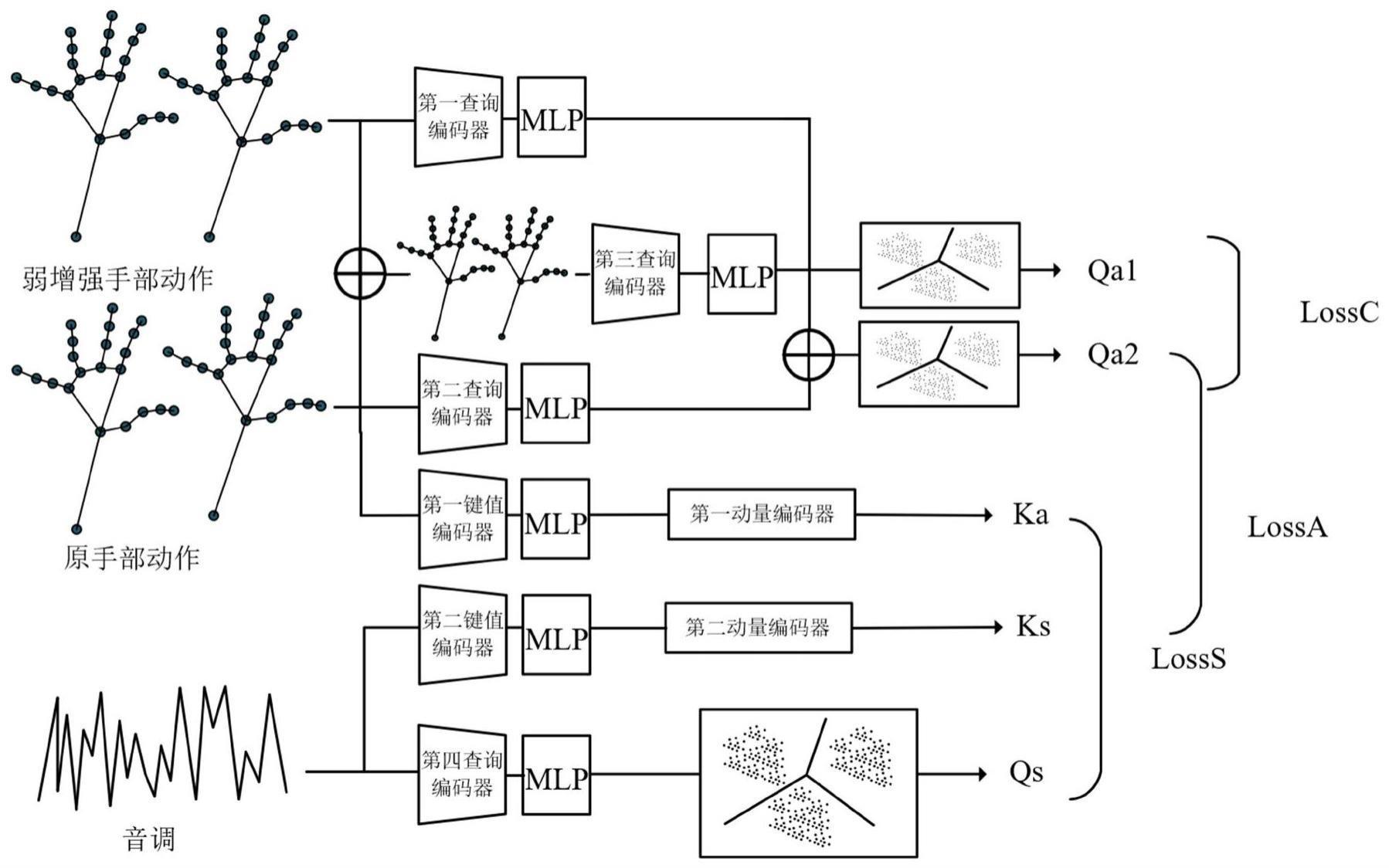
20、
21、
22、序列m的第i帧映射到最终序列xex的第m*i帧中,对于第i帧和i+1帧之间的插值帧依次映射到第m*i+1,m*i+2,……,m*i+m-1,式中j=m-1;
23、进一步,使用一阶马尔科夫链描述骨架数据的状态转移对生成的序列xex进行平滑处理,如下:
24、
25、
26、其中,delta(i,j)是克罗内克δ函数,i表示第i帧,p是控制平滑程度的参数,d为相邻帧之间的时间间隔;
27、进一步的,所述对比学习模型包括第一查询编码器第二查询编码器第三查询编码器以及每个查询编码器后会设置一个mlp投影头g(.);
28、还包括第一键值编码器和第一动量编码器;
29、所述第一查询编码器f(.)、第二查询编码器f(.)、第三查询编码器f(.)均为st-gcn查询编码器f(.);
30、将原始样本x、增强数据xen和外插值数据xex分别输入到第一查询编码器f(.)、第二查询编码器f(.)、第三查询编码器f(.),第一查询编码器f(.)、第二查询编码器f(.)、第三查询编码器f(.)分别输出原始样本x、增强数据xen和外插值数据xex对应的编码特征z、zen、zex;通过查询编码器和mlp投影头g(.)提取表示,其中查询编码器f(.)和mlp投影头g(.)是用于提取特征向量和将特征向量映射到低维空间的两个关键组件,以便计算相似度和进行后续的对比学习。
31、即,第一查询编码器f(.)输出编码特征z;
32、第二查询编码器f(.)输出编码特征zen;
33、第三查询编码器f(.)编码特征zex;
34、然后在经过归一化进行处理:
35、
36、
37、上式中f(.)包含了一个网络编码器和一个mlp投影头,即f(.)=g(f(.))。
38、对编码特征z和编码特征zen做内插值,定义内插值zin:
39、zin=λ*z+(1-λ)*zen=λ*f(x)+(1-λ)*f(xen)
40、式中λ是bata的分布构成的;
41、得到正样本对[zin,zex](extrapolation,interpolation);
42、原始样本输入到第一键值编码器中,得到编码键zak,再通过第一动量编码器对第一键值编码器进行参数更新
43、进一步的,所述对比学习模型还包括第二键值编码器第二动量编码器、第四查询编码器
44、音频数据输入到第二键值编码器将第二键值编码器的输出结果再输入到第二动量编码器中;得到编码键zsk;
45、音频数据输入到第四查询编码器获得音频的编码查询zsq。
46、本发明以moco.v2为对比学习模型做跨模态对比学习,moco.v2是一种使用内存缓存机制和动态负样本生成策略的对比学习框架。在对比学习中,每一个通过vr/ar采集的动作和音频片段都会生成一对查询(query)和键(key),通过对比查询和键的相似度来实现对比学习。在此过程中,查询是从数据增强的数据中提取出的特征向量,而键则是通过特征提取和缓存处理后得到的特征向量,并统一存储在一个动态更新的记忆库中。在本发明中本发明首先给定一个手部动作编码查询(此处手部动作编码查询选择使用内插值编码查询zin)和一个编码键以及一个音频编码查询和一个编码键
47、进一步的,利用梯度停止对外插值序列zex操作,将一致性约束表示为:
48、lossc=sim(zin,stopgrad(zex))
49、进一步的,批量的编码键和被分别嵌入在两个动态更新的记忆库中,本发明将根据数据量设置记忆库规模。在记忆库中,新的编码键和进入记忆库,最先进入记忆库的编码键出库,用于减少冗余计算。其中和和作为两对正样本,和作为记忆库中的样本用作训练的负样本。
50、参照moco.v2[2]中的对比损失函数设计出本发明的跨模型infonce的对比损失函数,写成:
51、
52、
53、其中τ是温度超参数,点积用于计算和用于正样本对的相似性,点击和用于计算负样本对的相似性,对比损失函数要最大化正样本对的相似性,最小化负样本对的相似性。
54、在经过(18)式的对比损失函数后,查询和键对应的编码器:查询编码器和键值编码器需要相应的进行更新。其中查询编码器通过梯度进行参数更新,键值编码器以查询编码器的移动平均值进行更新,也就是动量更新。将查询编码器的参数设置为θq,将键值编码器的参数设置为θk,那么键值编码器的参数更新公式为:
55、θk←mθk+(1-m)θq
56、其中m∈[0,1]为动量系数,一般选择为m=0.999,表示键值编码器将进行缓慢更新,将保证记忆库中键值表示的一致性。
57、进一步的,对记忆库中每一个入库的编码键值进行聚类表示,通过计算了编码键值所属的簇,并将其与记忆库中所保存的键值所属的簇进行比较,得到一个布尔类型的掩码masks。
58、具体为:每一个编码查询q都有一个对应的编码键值k作为正样本;
59、设置记忆库ma和记忆库ms分别用于存放手部动作数据和音频数据,分别对两个记忆库和每个入库的键值k做聚类,记忆库和每个键值k分别生成两个聚类标签,将键值k的聚类标签在记忆库的聚类标签中依次比对,将相同标签进行掩码。基于聚类掩码的对比损失函数构造为:
60、
61、
62、其中,nb表示所采集的总样本数;表示第i个内插值的查询编码特征;表示第i个音频数据的查询编码特征;mj表示记忆库中的第j个数据;ms和ma为维护的两个记忆库,用于存放负样本。
63、进一步的,本发明的框架使用了聚类的方式来重构负样本的定义,但是对于聚类的性能,还需要额外的标准进行量化。如果聚类结果与真实的数据分布差异过大,那么需要真阴性对将被消除,这将严重影响模型的预训练性能。为此,本发明认为在聚类方法中,越靠近聚类边界的样本其分类情况是越不稳定的,越靠近聚类中心的样本更有可能属于同一类。因此,本发明设计了一个超参数β,来调节本发明负样本重构方案。具体地,超参数β,表示靠近聚类中心的样本比例,样本比例内的,采用负样本重构方案,在负样本外的使用基于实例的判断方案。因此本发明提出的策略的样本使用linfo-clus,而moco.v2框架中的对比损失函数linfo。本发明可以多次调整以找到最佳的聚类边界。由此本发明的对比函数损失可以写为:
64、
65、
66、其中thr(β,i)表示样本j如果在聚类中心β以内,则取1,否则取0。当β很小时,每个簇集将获得更少的样本。当β增大时相反。β为0时,模型的对比损失函数退化为标准的moco.v2的损失,β为1时模型退为本发明提出的负样本重构损失。
67、传统对比学习进行增强来扩充正样本时,特别是使用强增强时,样本会产生较大的语义信息的损失,特别对于动作更加细致化的手部骨架。而手部的错误动作仅仅很短暂的出现在整个样本中,难以通过对比学习方法准确捕捉。为了解决这个问题,本发明尝试通过放大错误动作来增强样本,从而更准确地捕捉手部错误动作。此外,在对比学习正负样本选择过程中,实例被视为彼此的否定,在训练过程中彼此远离,意味着同一类实例可能过度分离。针对这两个问题,本发明的工作创新点如下:
68、[1].基于插值的方法构造更加可靠的正样本对,通过对动作序列的插值扩充,将错误动作的持续时间拉长,更容易捕捉到错误动作。并且使用了内插值和外插值两种插值方法,对两种插值方法的特征表示一致性进行约束
69、[2].设计了一种负样本重构的方法,将聚类中不同类样本视为负样本,提出一种新的对比损失函数掩盖相同聚类中实例,并设计实例权重避免无效样本对对比学习的干扰。
- 还没有人留言评论。精彩留言会获得点赞!